Vertica 性能调优 - 3 重新设计 PROJECTION¶
编译:JiangChong
这是性能调优三步曲系列的第三篇文档,该系列包含以下文章:
- 第 1 部分:如何阅读 Vertica 的执行计划
- 第 2 部分:使用系统表排除 Vertica 查询性能故障
- 第 3 部分:重新设计查询优化投影
当您向 Vertica 提交查询时,Vertica 查询优化器会根据统计信息自动生成执行计划,该计划是由一系列用于计算查询结果的操作组成。根据数据库中定义的投影的属性,查询优化器可以选择更快、更高效的操作。因此,了解您可以采取哪些措施来优化投影以提高查询性能非常重要。
不同的PROJECTION设计对查询性能和查询运行所需的资源有不同的影响。
下表描述了各种投影属性如何对查询性能产生正面 (+) 或负面 (-) 影响。例如,对数据进行编码将对网络使用产生积极影响。
| Memory | CPU | I/O | Network | Performance | |
|---|---|---|---|---|---|
| Encoding | + When data is encoded - After data materialization |
+/- Depends on encoding type | + | + | + |
| Order by | + In joins and group bys | - in Load and Mergeout | No impact | No impact | + |
| Segmentation | No impact | - in Load and Mergeout | + | + When loading data - In joins and group bys |
+ When table is big and data is distributed - In joins |
1、Projection 编码、压缩¶
作为列式数据库,丰富多样的数据编码方式是 Vertica 数据库的特色。数据编码的目标是减少存储,从而减少加载和读取数据所需的 I/O。但在减少存储空间的同时,可能会增加 CPU 使用率。
除了编码之外,Vertica 还应用压缩。在 Vertica 中,压缩过程使用 LZO 算法。
Vertica 可以使用编码数据,直到数据需要具体化,但压缩数据需要在参与查询之前解压缩。
1.1 Default (AUTO) 编码¶
如果未指定编码类型,Vertica 将使用默认编码 (AUTO)。默认编码类型取决于您要编码的数据。例如,TIMESTAMP 列的默认编码是基于连续列值之间的增量的压缩方案。对于数据类型为 CHAR 和 VARCHAR 的列,Vertica 将应用 LZO 压缩。您可以在此处查看数据类型及其默认编码的列表。
1.2 使用 Database Designer 进行编码¶
您可以运行 Database Designer 来确定投影的最佳编码。Database Designer 通过对 1% 的数据进行抽样并确定列字段类型和基数来实现此目的。根据这些参数,Database Designer 会尝试不同的编码类型并选择使用其中占用存储最少的类型。
您还可以使用 DESIGNER_DESIGN_PROJECTION_ENCODINGS 函数来分析指定投影中的编码,创建脚本来实施编码建议,并部署建议。
1.3 案例:数据加载中的编码和性能¶
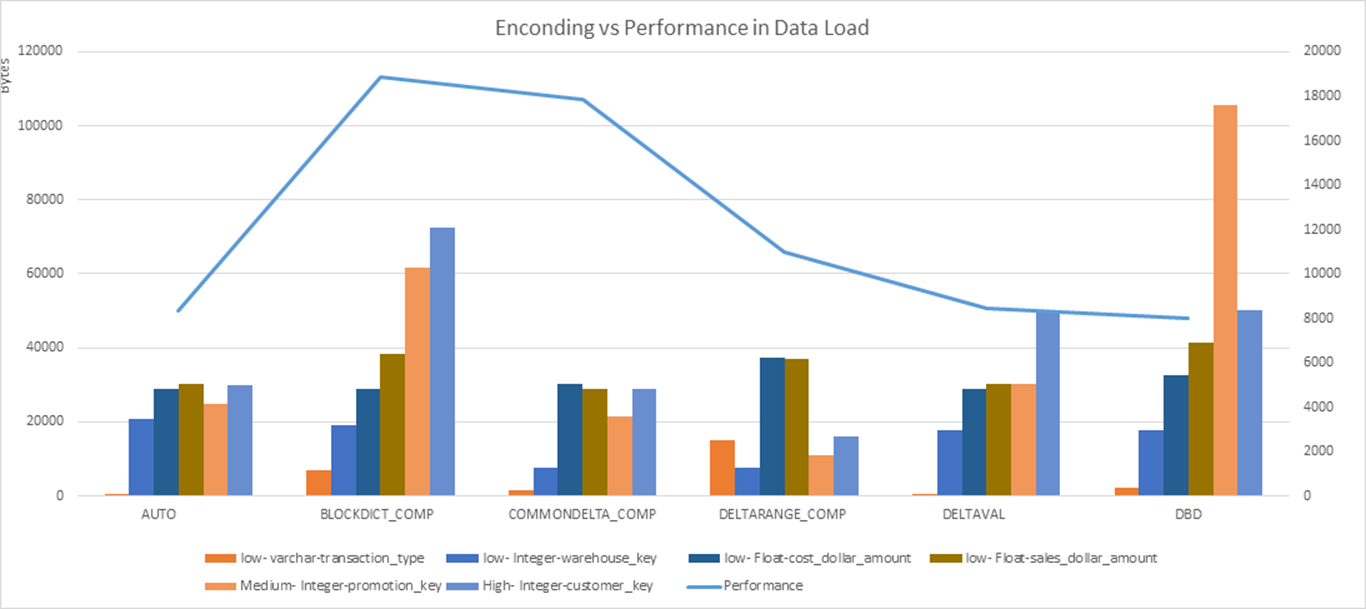
1.4 相关系统表¶
PROJECTION_COLUMNS:提供编码类型、排序顺序、统计信息类型以及列统计信息上次更新时间等信息。
COLUMN_STORAGE:返回每个节点上每个投影的每一列使用的磁盘存储量。
1.5 示例查询¶
SELECT *
FROM PROJECTION_COLUMNS pc, COLUMN_STORAGE cs
WHERE pc.column_id = cs.column_id
AND pc.projection_id = cs.projection_id
AND pc.projection_name ilike '<projection_name>'
GROUP BY 1,2,3,4,5,6,7,9,10,11
ORDER BY pc.projection_name, pc.sort_position ;
-[ RECORD 1 ]----------------+------------------------------------------------
projection_name | online_sales_fact_DBD_15_seg_vertica_7_2_3_8_b0
projection_column_name | product_key
column_position | 2
sort_position |
encoding_type | DELTAVAL
encodings | Int_Delta
compressions | none
sum | 40112451252
access_rank | 0
statistics_type | FULL
statistics_updated_timestamp | 2016-10-17 18:44:27.255243-04
…
2、PROJECTION 中的 ORDER BY 子句¶
Merge Join与Hash Join
您可以通过 Projection 的优化让 Vertica 合理选择驱动表(inner) 和被驱动表(outer),避免额外的排序和节点间数据传输操作,从而提高表关联性能。
Vertica 中的关联有如下两种方式:
- Merge Join
- Hash Join
2.1 优点和缺点¶
| 优点 | 缺点 | |
|---|---|---|
| MergeJoin | · 更快 · 使用内存更少 |
· 数据必须按关联字段排序 |
| HashJoin | · 无需排序 · 如果 Inner 表较小且可以放入内存,则可以更快。 |
· 使用更多内存 · 如果 inner 表无法放入内存,查询将失败。可以重试查询并让哈希表溢出到磁盘,但性能会比较差。 |
优化器会根据查询和投影自动选择最合适的算法。
在Hash Join算法中,Vertica 使用较小的(inner)连接表在内存中构建关联字段的哈希表。然后,Vertica 扫描 outer(大)表并探测哈希表以查找匹配项。如果您设计两个 Projection 均按照关联字段预先进行了排序,则优化器可以使用更快的 Merge Join 。
如果仅对Outer表进行排序,Vertica 可以通过在关联之前对Inner表进行排序来执行sorted merge join。在某些情况下,这种方法比在内存中对整个内部表进行哈希处理占用更少的内存。
2.2 Hints¶
使用以下Hints来告诉优化器要使用哪个连接运算符:
/*+JType(M)*/:强制使用Merge Join。如果关联键未预先排序,Vertica 将在关联之前对其进行排序。/*+JType(H)*/:强制使用Hash Join。
3、针对 GROUP BY 子句优化 Projections¶
3.1 PIPELINED 与 HASH¶
如果您的查询包含 GROUP BY 子句,Vertica 将使用 GROUPBY PIPELINED 或 GROUPBY HASH 算法计算结果。这两种算法计算的结果相同,但如果您的查询包含大量分组数据,GROUPBY PIPELINED 占用的内存更少,速度更快。但是,只有分组汇总数据在 GROUP BY 列上预先排序时才使用此算法。
3.2 优缺点¶
| 优点 | 缺点 | |
|---|---|---|
| PIPELINED | · 如果分组汇总数据量较大,则内存更少且速度更快 | · 数据必须按 GROUP BY 列排序 |
| HASH | · 无需排序 · 如果聚合中只有几个不同的值,则性能更好。 |
· 使用更多内存 |
要提高具有大量不同分组汇总数据的查询的性能,请通过以下最佳实践来使用 GROUPBY PIPELINED 算法:
- 确保投影的排序列包含查询的 GROUP BY 子句中的所有列
- 如果投影的 ORDER BY 子句的列多于查询的 GROUP BY 子句,请验证 GROUP BY 子句的列是否位于投影的 ORDER BY 子句部分的前部。下面将介绍例外情况。
- 如果查询的 GROUP BY 列未首先出现在投影的 ORDER BY 子句中,则验证查询的 GROUP BY 子句中缺少的任何早期出现的投影排序列是否作为单列常量相等谓词包含在查询的 WHERE 中。
4、Projection Replication 与 Segmentation¶
数据库设计器根据SQL与数据统计信息创建投影。为了创建优化查询性能的设计,它还会检查提交的设计表,以决定投影是否应分段(分布在集群节点上)或复制(在所有集群节点上重复)。
| 用于如下场景… | |
|---|---|
| Replication | · 小表 · LONG VARCHAR 和 LONG BINARY 字段 · Projections 满足如下任何一种情况: (largest-row-count = # of rows in the table with the largest row count(数据库中最大的表的数据量)) o largest-row-count < 1,000,000 and number of rows in the table <= 10% of largest-row-count o largest-row-count >= 10,000,000 and number of rows in the table <= 1% of largest-row-count o The number of rows in the table(当前表的数据量) <= 100,000 |
| Segmentation | · 大表、事实表 |
4.1 自动创建 PROJECTION 的分段¶
自动投影是 Vertica 自动为表生成的超级投影。在自动投影中,如果表定义了主键,则投影按主键分段。如果不存在主键,则投影按表的前 32 列分段。
注意
- 在创建表的时候,如果没有指定表的排序、分段,则表创建完成后并没有 PROJECTION。
- 只有在往表里写入数据时,数据库会自动创建一个 superprojection,其排序和分段缺省采用前32列(新版本缺省为8列)。
5、减少数据重新分布¶
根据您的查询,Vertica 优化器可能需要在执行时重新分配数据。此过程会导致过多的网络流量,并且需要更多内存才能运行。
优化器可以通过两种方式重新分配数据:
- Broadcasting(广播):将中间结果的完整副本发送到集群中的所有节点。
- Resegmentation(重新分段):采用现有的投影或中间关系,并在所有集群节点上均匀地重新分段数据。在重新分段操作结束时,输入关系中的每一行都恰好位于一个节点上。
| Used when… | |
|---|---|
| Broadcast | · 一个表与另一个表相比非常小(通常是 Inner 表)。 · Vertica 可以避免其他大型上游重新分段操作。 · 外连接或子查询语义要求复制连接的一侧。 |
| Resegmentation | · 分布式连接中的数据尚未针对本地连接进行分段。 |
为了提高多个表关联查询时的性能,建议将 inner 表数据按照关联字段进行分布或将 Inner 表的 projection 设置为 unsegmented。按照关联字段分布或者 unsegmented 的表在关联时可以在每个节点上进行本地连接,从而减少查询处理期间跨网络的数据移动。
您可以通过使用 EXPLAIN 生成和查看执行计划来确定投影是否在查询连接键上完全分段。如果查询计划包含 RESEGMENT 或 BROADCAST,则投影不是完全分段的。
6、分段与汇总¶
为了避免重新分段,请验证 GROUP BY 子句是否包含投影的所有分段列,尽管它也可以包含其他列。在实现连接之前,将此连接键的数据广播到其他节点。
6.1 使用网络数据压缩降低数据分发代价¶
有时网络操作是不可避免的。如果网络带宽是个问题,您可以将 CompressNetworkData 设置为 1,这样数据在发送到其他节点之前就会被压缩。这种压缩可以加快网络流量,但需要更多 CPU。
7、Projection 的使用¶
随着针对特定查询而优化创建的 PROJECTION 越来越多,查询的性能会得到改善。但是,使用的磁盘空间量和加载数据所需的时间也会增加。因此,应控制表的 PROJECTION 数量,一般每个表的 PROJECTION 控制在3个以内。
扩展阅读¶
- Vertica 性能调优 - 1 如何阅读执行计划 — 理解执行计划
- Vertica 性能调优 - 2 使用系统表排查查询故障 — 系统表分析
- Vertica 锁和锁冲突 — 投影操作中的锁管理
- Projection 优化最佳实践 — Projection 优化最佳实践