Vertica 逻辑回归实战(Titanic 数据集)¶
编译:JiangChong 原文:Logistic Regression Using Vertica's In-Built Machine Learning Functions
概述¶
本文档将逐步介绍如何在 Vertica 中使用内置机器学习函数进行逻辑回归。作为示例,我们在 Titanic 数据集上使用 Vertica 的内置机器学习函数进行逻辑回归。
在机器学习中,逻辑回归用于预测事件发生的概率。它是最简单的监督学习方法之一。例如,可以用来预测一封邮件是否为垃圾邮件(1)或非垃圾邮件(0)。给定输入 X,我们使用逻辑函数(Logistic Function)来预测 p(X):
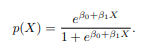
其中 β0 和 β1 是回归系数,是未知的,需要通过训练数据集来估计。我们估计 β0 和 β1 的值,使得 p(X) 的概率尽可能接近对应的原始值。我们使用最大似然估计(Maximum Likelihood Estimation, MLE) 来估计这些系数。
下面我们将使用 Vertica 的内置机器学习函数,将逻辑回归这一统计技术应用到 Titanic 数据集上,预测乘客的生存情况。
数据集背景¶
RMS Titanic 是一艘英国客运邮轮,在其首航中撞上冰山沉没,造成超过 1500 名乘客遇难。我们的目标是预测给定乘客的生存概率。影响哪些乘客能登上救生艇、哪些不能的因素有很多,最显著的是性别和舱位等级。我们将使用两个数据集(一个用于训练,一个用于测试)来创建一个模型,预测乘客是否幸存。
下载数据集¶
克隆 Vertica Machine Learning GitHub 仓库,在终端窗口中执行以下命令:
我们将使用其中的 titanic_training.csv 和 titanic_testing.csv 文件。
加载数据¶
第一步是将数据加载到数据库中。创建两张表,一张用于训练,另一张用于测试。
dbadmin=> CREATE TABLE titanic_training(passenger_id int, survived int, pclass int, name varchar(50),
sex varchar(10), age int, sibling_and_spouse_count int, parent_and_child_count int,
ticket varchar(15), fare float, cabin varchar(10), embarkation_point varchar(15));
CREATE TABLE
dbadmin=>
dbadmin=> CREATE TABLE titanic_testing(passenger_id int, pclass int, name varchar(50),
sex varchar(10), age int, sibling_and_spouse_count int, parent_and_child_count int,
ticket varchar(15), fare float, cabin varchar(10), embarkation_point varchar(15));
CREATE TABLE
dbadmin=>
其中 titanic_training 表包含 12 列(含目标列 survived),titanic_testing 表包含 11 列(不含目标列)。
接下来,将数据加载到对应的表中。
dbadmin=> COPY titanic_training FROM LOCAL 'titanic_training.csv' DELIMITER ',' ENCLOSED BY '"';
Rows Loaded
-------------
815
(1 row)
dbadmin=> COPY titanic_testing FROM LOCAL 'titanic_testing.csv' DELIMITER ',' ENCLOSED BY '"';
Rows Loaded
-------------
378
(1 row)
dbadmin=>
为了评估模型的准确性,我们从 Kaggle 下载测试数据集的生存结果(gender_submission.csv),并创建一张名为 titanic_test_survival 的表。
dbadmin=> CREATE TABLE titanic_test_survival(passenger_id int, survived int);
CREATE TABLE
dbadmin=> COPY titanic_test_survival FROM LOCAL 'gender_submission.csv' DELIMITER ',' ENCLOSED BY '"';
Rows Loaded
-------------
418
(1 row)
dbadmin=>
然后删除 titanic_test_survival 中在 titanic_testing 里没有对应数据的记录。
dbadmin=> DELETE FROM titanic_test_survival where passenger_id in (select passenger_id from titanic_test_survival where passenger_id not in (select passenger_id from titanic_testing));
OUTPUT
--------
40
(1 row)
dbadmin=> commit;
COMMIT
数据探索¶
我们有 815 条训练观测值和 378 条测试观测值。根据表定义,数据集包含 11 个预测变量 和 1 个目标变量(名为 survived)。在这 11 个特征中,Survived、Sex、Pclass、embarkation_point、Cabin、Name、Ticket、sibling_and_spouse_count 和 parent_and_child_count 是分类变量,而 Fare、Age 和 passenger_id 是数值变量。
在统计学中,分类变量指取值数量有限的变量,例如性别(取值为 Male 或 Female)。由于我们有多于 1 个预测变量,因此执行的是多元逻辑回归(Multiple Logistic Regression)。
以下是 Titanic 数据集各特征的详细说明:
| 特征 | 说明 |
|---|---|
| Passenger_id | 分配给每位乘客的唯一标识号 |
| Survived | 乘客是否幸存(0 = 否, 1 = 是)——目标变量 |
| Pclass | 乘客舱位等级(1 = 头等舱, 2 = 二等舱, 3 = 三等舱) |
| Name | 乘客姓名 |
| Sex | 乘客性别(Male / Female) |
| Age | 乘客年龄 |
| sibling_and_spouse_count | 同船兄弟姐妹/配偶人数 |
| parent_and_child_count | 同船父母/子女人数 |
| Ticket | 发给乘客的票号 |
| Fare | 购买该票所花费的金额 |
| Cabin | 乘客所在的船舱类别 |
| Embarkation_point | 乘客登船的港口(C = Cherbourg, Q = Queenstown, S = Southampton) |
数值特征分布¶
使用 SUMMARIZE_NUMCOL 查看数值特征的分布:
dbadmin=> SELECT SUMMARIZE_NUMCOL(passenger_id, survived, pclass, age, sibling_and_spouse_count, parent_and_child_count, fare) OVER() FROM titanic_training;
Table 1 — Titanic 数据集数值特征分布
| COLUMN | COUNT | MEAN | STDDEV | MIN | 25% | 50% | 75% | MAX |
|---|---|---|---|---|---|---|---|---|
| age | 656 | 30.172256097561 | 14.3014190862079 | 1 | 21 | 29 | 39 | 80 |
| fare | 815 | 33.1048303067485 | 50.7783288265627 | 0 | 7.925 | 14.4542 | 31.3875 | 512.3292 |
| parent_and_child_count | 815 | 0.376687116564417 | 0.810978914656903 | 0 | 0 | 0 | 0 | 6 |
| passenger_id | 815 | 447.566871165644 | 257.283317160943 | 1 | 229.5 | 449 | 667.5 | 891 |
| pclass | 815 | 2.29325153374233 | 0.843323892994739 | 1 | 1 | 3 | 3 | 3 |
| sibling_and_spouse_count | 815 | 0.532515337423313 | 1.10665195736505 | 0 | 0 | 0 | 1 | 8 |
| survived | 815 | 0.36319018404908 | 0.481214303403727 | 0 | 0 | 0 | 1 | 1 |
分类特征分布¶
使用 SUMMARIZE_CATCOL 查看分类特征的分布。
Sex 分布:
dbadmin=> SELECT SUMMARIZE_CATCOL(sex USING PARAMETERS WITH_TOTALCOUNT = true) OVER() from titanic_training;
Table 2 — Titanic 数据集分类特征 Sex 分布
| CATEGORY | COUNT | PERCENT |
|---|---|---|
| (总计) | 815 | 100 |
| male | 538 | 66.01% |
| female | 277 | 33.99% |
Embarkation_point 分布:
dbadmin=> SELECT SUMMARIZE_CATCOL(embarkation_point USING PARAMETERS WITH_TOTALCOUNT = true) OVER() from titanic_training;
Table 3 — Titanic 数据集分类特征 Embarkation Point 分布
| CATEGORY | COUNT | PERCENT |
|---|---|---|
| (总计) | 815 | 100 |
| S | 603 | 73.99% |
| C | 150 | 18.40% |
| Q | 60 | 7.36% |
| (空值) | 2 | 0.25% |
数据准备¶
数据准备是机器学习中非常重要的一步。我们需要确保数据集中不包含缺失值、重复行、异常值或数据不平衡问题。如果这一步处理不当,模型可能无法准确预测结果。
缺失值处理¶
我们发现 age、cabin 和 embarkation_point 列存在缺失值。
Table 4 — 含缺失值的特征及对应缺失数量(训练/测试数据)
| 特征名称 | 缺失值数量 |
|---|---|
| age | 159(训练数据), 78(测试数据) |
| cabin | 622(训练数据) |
| embarkation_point | 2(训练数据) |
Vertica 提供了名为 IMPUTE 的内置机器学习函数,可以根据指定的方法替换缺失数据。下面我们对 Table 1 中识别出的含缺失值特征进行填充。
Cabin 列——直接删除¶
在训练数据的 815 条观测值中,cabin 有 622 条缺失。即使我们使用最常出现的舱位号来填充,也没有意义,因为不可能有多个人拥有相同的舱位号。因此,最好不使用此特征。让我们在 titanic_testing 和 titanic_training 表中都删除该列。
dbadmin=> ALTER TABLE titanic_training DROP COLUMN cabin CASCADE;
ALTER TABLE
dbadmin=> ALTER TABLE titanic_testing DROP COLUMN cabin CASCADE;
ALTER TABLE
注意:如果在删除列时遇到错误,请检查投影设计,确保该列不属于 segmentation 或 order by 子句的一部分。
Age 列——均值填充¶
训练数据中有 159 条 age 缺失值。我们使用 IMPUTE 函数以均值(mean)来替换缺失值。
dbadmin=> SELECT IMPUTE('output_view_age','titanic_training','age','mean');
IMPUTE
--------------------------
Finished in 1 iteration
(1 row)
再对测试数据中的 age 执行同样的填充操作:
dbadmin=> SELECT IMPUTE('output_view_age_test','titanic_testing','age','mean');
IMPUTE
--------------------------
Finished in 1 iteration
(1 row)
Embarkation_point 列——众数填充¶
embarkation_point 是分类变量,训练数据中有 2 条缺失值。我们使用 IMPUTE 函数以最频繁出现的值(mode)来替换缺失值。将上一步创建的视图作为输入:
dbadmin=> SELECT IMPUTE('output_view_embarkation','output_view_age','embarkation_point','mode');
IMPUTE
--------------------------
Finished in 1 iteration
(1 row)

编码分类变量¶
Titanic 数据集中有两个分类列需要编码:sex 和 embarkation_point。大多数 ML 模型要求所有的输入和输出变量都是数值类型。有多种方法可以对分类列进行编码,独热编码(One-Hot Encoding) 是最常用的方法,它将数据转换为二进制格式。
Vertica 提供了名为 ONE_HOT_ENCODER_FIT 的内置函数。我们对训练数据集应用独热编码。该函数会将分类特征转换为二进制特征并存储在模型中:
dbadmin=> SELECT ONE_HOT_ENCODER_FIT('titanic_encoder', 'output_view_embarkation', 'sex, embarkation_point');
ONE_HOT_ENCODER_FIT
---------------------
Success
(1 row)

使用 GET_MODEL_SUMMARY 函数查看 titanic_encoder 模型中的编码特征:
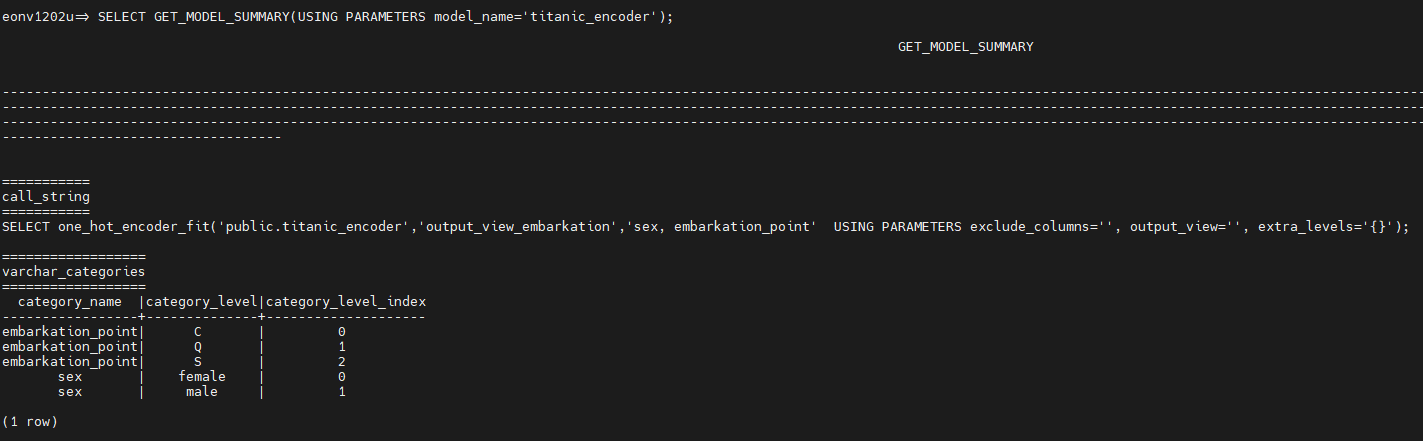
输出显示 embarkation_point 和 sex 都已经被编码为二进制格式:
| category_name | category_level | category_level_index |
|---|---|---|
| embarkation_point | C | 0 |
| embarkation_point | Q | 1 |
| embarkation_point | S | 2 |
| sex | female | 0 |
| sex | male | 1 |
接下来,使用上一步创建的 titanic_encoder 模型对训练数据和测试数据应用编码,创建带编码列的训练和测试视图。Vertica 提供了名为 APPLY_ONE_HOT_ENCODER 的函数来实现这一目的。
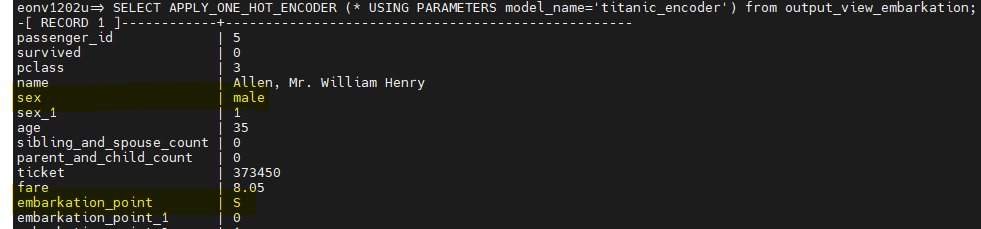
在对训练数据集运行 APPLY_ONE_HOT_ENCODER 后,会同时得到原始值和对应的编码值。要构建模型,我们只需要分类列的编码值。此外,我们将排除 name 和 ticket,因为它们是 varchar 类型的列。逻辑回归要求输入训练数据是数值格式。现在选择所需的列并创建训练视图:
CREATE VIEW titanic_training_encoded AS SELECT passenger_id, survived, pclass, sex_1, age,
sibling_and_spouse_count, parent_and_child_count, fare, embarkation_point_1, embarkation_point_2
FROM (SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='titanic_encoder')
FROM output_view_embarkation) AS sq;
CREATE VIEW
dbadmin=>
接下来,为测试数据创建视图:
CREATE VIEW titanic_testing_encoded AS SELECT passenger_id, name, pclass, sex_1, age,
sibling_and_spouse_count, parent_and_child_count, fare, embarkation_point_1, embarkation_point_2
FROM (SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='titanic_encoder')
FROM output_view_age_test) AS sq;
CREATE VIEW
dbadmin=>
构建逻辑回归模型¶
完成数据预处理后,我们对训练数据运行逻辑回归并构建模型。创建一个名为 titanic_model 的模型。其中 passenger_id 和 survived 被传入 exclude_columns 参数。survived 被排除是因为它已被作为响应列(response column);passenger_id 被排除是因为它无助于预测乘客是否幸存。
dbadmin=> SELECT LOGISTIC_REG('titanic_model', 'titanic_training_encoded', 'survived', '*'
USING PARAMETERS exclude_columns='passenger_id, survived');
LOGISTIC_REG
---------------------------
Finished in 5 iterations
(1 row)
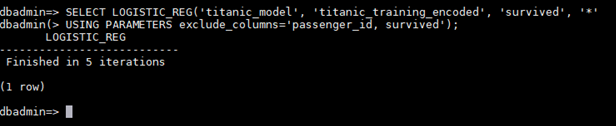
使用 GET_MODEL_ATTRIBUTE 查看 titanic_model 的属性摘要:
Table 5 — Titanic 模型参数
| predictor | coefficient | std_err | z_value | p_value |
|---|---|---|---|---|
| Intercept | 4.79608507226254 | 0.588356390682034 | 8.15166648687681 | 3.58943081416261e-16 |
| pclass | -1.04367548461173 | 0.150046006586495 | -6.95570317634611 | 3.50807788992785e-12 |
| sex_1 | -2.83317816597054 | 0.213897983172462 | -13.245464608641 | 4.79306444216242e-40 |
| age | -0.0308952083686641 | 0.00828154776064673 | -3.73060800487992 | 0.000191018233152909 |
| sibling_and_spouse_count | -0.283460326254313 | 0.114119041328987 | -2.48390034610562 | 0.0129952168866586 |
| parent_and_child_count | -0.142765927531063 | 0.123121694222583 | -1.15955135634315 | 0.246231515660041 |
| fare | 0.00268052020303712 | 0.00245537645477208 | 1.09169418718969 | 0.274967541017099 |
| embarkation_point_1 | -0.160265939268667 | 0.438429351725351 | -0.365545642959287 | 0.714704142353224 |
| embarkation_point_2 | -0.338240678212526 | 0.252730668321822 | -1.33834441406935 | 0.180784189896433 |
预测结果¶
将逻辑回归模型 titanic_model 应用于测试数据,预测乘客是否幸存。将预测结果连同原始生存结果一起存储在名为 titanic_predicted_results 的表中:
dbadmin=> CREATE TABLE titanic_predicted_results AS (SELECT t.passenger_id, t.name, PREDICT_LOGISTIC_REG(t.pclass, t.sex_1, t.age, t.sibling_and_spouse_count,
t.parent_and_child_count, t.fare, t.embarkation_point_1, t.embarkation_point_2 USING PARAMETERS
model_name='titanic_model') as predicted, s.survived FROM titanic_testing_encoded t, titanic_test_survival s WHERE t.passenger_id = s.passenger_id ORDER BY t.passenger_id);
CREATE TABLE
dbadmin=> SELECT * FROM titanic_predicted_results LIMIT 7;
passenger_id | name | predicted | survived
--------------+-----------------------------------------------+-----------+----------
897 | Svensson, Mr. Johan Cervin | 0 | 0
898 | Connolly, Miss. Kate | 1 | 1
901 | Davies, Mr. John Samuel | 0 | 0
902 | Ilieff, Mr. Ylio | 0 | 0
907 | del Carlo, Mrs. Sebastiano (Argenia Genovesi) | 1 | 1
908 | Keane, Mr. Daniel | 0 | 0
917 | Robins, Mr. Alexander A | 0 | 0
(7 rows)
模型评估¶
混淆矩阵(Confusion Matrix)¶
创建混淆矩阵来检验模型的预测准确性。混淆矩阵将实际值与模型预测的目标值进行比较。
dbadmin=> SELECT CONFUSION_MATRIX(original::int, predicted::int USING PARAMETERS num_classes=2) OVER()
FROM (SELECT survived AS original, predicted FROM titanic_predicted_results ORDER BY passenger_id) AS prediction_output;
actual_class | predicted_0 | predicted_1 | comment
--------------+-------------+-------------+-----------------------------------------------
0 | 232 | 10 |
1 | 9 | 127 | Of 378 rows, 378 were used and 0 were ignored
(2 rows)

根据混淆矩阵,模型对测试数据集中的全部 378 条观测值进行了预测。正确预测了 359 条观测值——其中 232 条为 class 0(未幸存),127 条为 class 1(幸存)。
其他评估指标¶
计算 ROC、AUC 和 ERROR_RATE:
dbadmin=> SELECT ROC(original, predicted USING PARAMETERS num_bins=5, AUC = True) OVER()
FROM (SELECT survived AS original, predicted FROM titanic_predicted_results ORDER BY passenger_id) AS prediction_output;
decision_boundary | false_positive_rate | true_positive_rate | AUC | comment
-------------------+---------------------+--------------------+-------------------+-----------------------------------------------
0 | 1 | 1 | |
0.2 | 0.0413223140495868 | 0.933823529411765 | |
0.4 | 0.0413223140495868 | 0.933823529411765 | |
0.6 | 0.0413223140495868 | 0.933823529411765 | |
0.8 | 0.0413223140495868 | 0.933823529411765 | |
1 | 0 | 0 | 0.946250607681089 | Of 378 rows, 378 were used and 0 were ignored
(6 rows)
dbadmin=> SELECT ERROR_RATE(original::int, predicted::int USING PARAMETERS num_classes=2) OVER()
FROM (SELECT survived AS original, predicted FROM titanic_predicted_results ORDER BY passenger_id) AS prediction_output;
class | error_rate | comment
-------+--------------------+-----------------------------------------------
0 | 0.0413223140495868 |
1 | 0.0661764705882353 |
| 0.0502645502645503 | Of 378 rows, 378 were used and 0 were ignored
(3 rows)
dbadmin=> SELECT LIFT_TABLE(original, predicted USING PARAMETERS num_bins=5) OVER()
FROM (SELECT survived AS original, predicted FROM titanic_predicted_results ORDER BY passenger_id) AS prediction_output;
decision_boundary | positive_prediction_ratio | lift | comment
-------------------+---------------------------+------------------+-----------------------------------------------
1 | 0 | NaN |
0.8 | 0.933823529411765 | 2.57653499355947 |
0.6 | 0.933823529411765 | 2.57653499355947 |
0.4 | 0.933823529411765 | 2.57653499355947 |
0.2 | 0.933823529411765 | 2.57653499355947 |
0 | 1 | 1 | Of 378 rows, 378 were used and 0 were ignored
(6 rows)
结论¶
可以看到 ERROR_RATE 较低。标准误差值越低,预测越准确。ROC 曲线 展示了分类模型的性能,绘制了真正例率(TPR)和假正例率(FPR)。AUC(曲线下面积) 是一个非常重要的指标。根据结果,AUC 达到 94%,意味着我们的模型以 94% 的准确率预测乘客的生存结果。AUC 越高,分类器性能越好。Lift 计算了有模型和无模型情况下的结果比率。从结果看,正预测比率(positive prediction ratio)较高,这是一个好迹象。
从 Table 5 的模型参数来看,各特征的 p 值也没有出现过大的情况。总体而言,我们的模型在预测乘客生存方面表现相当不错!