Vertica JDBC Routable Query API 最佳实践¶
关于 API¶
JDBC Routable Query API(曾用名:JDBC Key/Value API)是 Vertica JDBC 驱动程序提供的一组接口,允许应用程序将查询路由到单个节点执行,而不是通过发起节点进行分布式执行。通过消除分布式查询的计划和协调开销,Routable Query API 显著提高了简单查询的吞吐量。
吞吐量对比¶
| 场景 | 查询/秒 | 提升倍数 |
|---|---|---|
| 标准 JDBC 查询 | 12 qps | 1x |
| Routable Query API | 192 qps | 16x |
非路由查询架构¶
在标准 JDBC 查询模式下,所有查询都通过发起节点(Initiator Node)进行解析、计划和分发。对于简单的点查操作,分布式协调的开销占比很高。
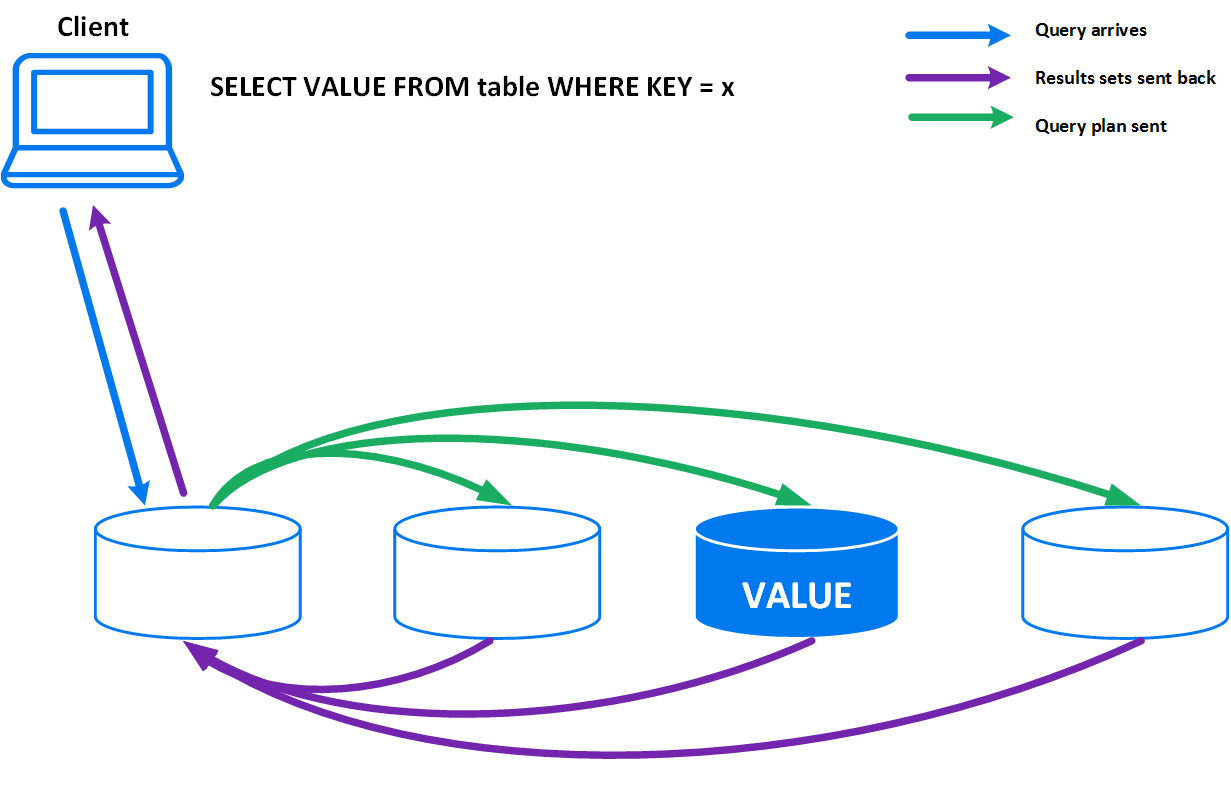
路由查询架构¶
Routable Query API 将查询直接路由到目标节点执行,避免了发起节点的计划开销,从而大幅提升简单查询的吞吐量。
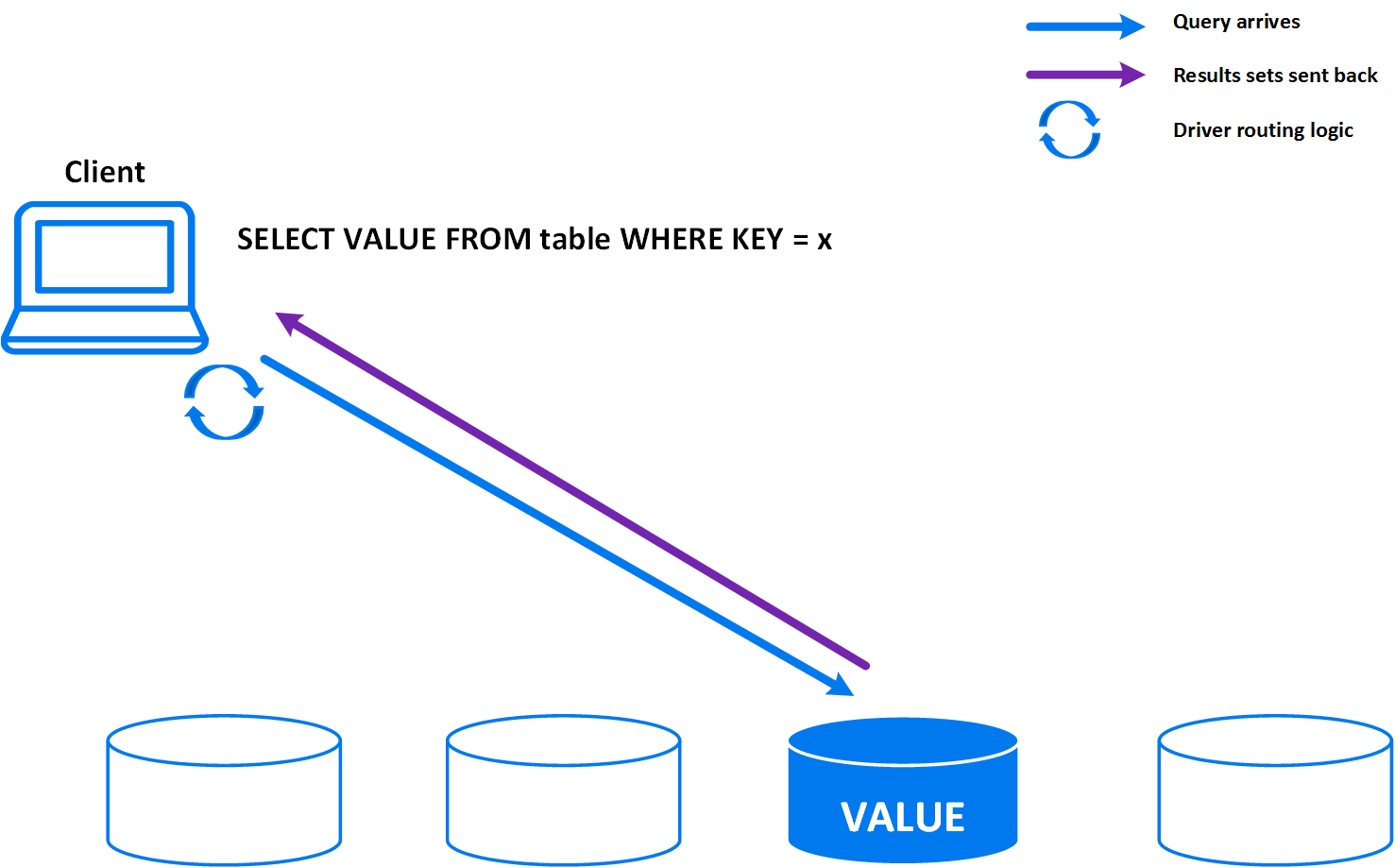
支持的数据类型¶
| 类型 | 支持情况 | 说明 |
|---|---|---|
| INTEGER / BIGINT / SMALLINT / TINYINT | 支持 | |
| BOOLEAN | 支持 | |
| FLOAT / DOUBLE PRECISION | 支持 | |
| VARCHAR / CHAR | 支持 | |
| NUMERIC / DECIMAL | 支持 | |
| DATE / TIME / TIMESTAMP / TIMESTAMPTZ | 支持 | |
| INTERVAL | 支持 | |
| BINARY / VARBINARY | 支持 | |
| GEOMETRY / GEOGRAPHY | 不支持 | 需要使用标准 JDBC 接口 |
| LONG VARBINARY / LONG VARCHAR | 不支持 | |
| UUID | 支持 | |
| ARRAY | 支持 | |
| SET / MULTISET | 支持 | |
| ROW / STRUCT | 支持 | |
| JSON | 有限支持 | 仅用于谓语条件筛选 |
创建表和投影¶
Routable Query API 要求表使用分段投影(Segmented Projection),以便将查询路由到特定节点。
-- 创建分段表
CREATE TABLE user_events (
user_id INTEGER NOT NULL,
event_time TIMESTAMP NOT NULL,
event_type VARCHAR(50),
event_data VARCHAR(500)
)
SEGMENTED BY HASH(user_id) ALL NODES;
-- 创建主键投影
CREATE PROJECTION user_events_super AS
SELECT * FROM user_events
ORDER BY user_id
SEGMENTED BY HASH(user_id) ALL NODES;
-- 为查询创建专用投影(按 user_id 分段,减少跨节点访问)
CREATE PROJECTION user_events_by_user AS
SELECT user_id, event_time, event_type
FROM user_events
ORDER BY user_id
SEGMENTED BY HASH(user_id) ALL NODES;
验证现有投影¶
在配置 Routable Query 之前,验证表的投影定义是否满足单节点执行的要求。
查询表投影信息¶
使用 EXPORT_OBJECTS 导出完整定义¶
-- 导出表的完整 DDL(包括投影定义)
SELECT EXPORT_OBJECTS('', 'user_events', 'CREATE_ONLY');
-- 导出投影的完整 DDL
SELECT EXPORT_OBJECTS('', 'user_events_super', 'CREATE_ONLY');
创建连接¶
使用 JDBC DataSource API¶
import com.vertica.jdbc.VerticaDataSource;
import javax.sql.DataSource;
VerticaDataSource ds = new VerticaDataSource();
ds.setServerHost("vertica.example.com");
ds.setPort(5433);
ds.setDatabase("mydb");
ds.setUser("app_user");
ds.setPassword("password");
// 启用 Routable Query 功能
ds.setRoutableQueryEnable(true);
// 设置最大连接数
ds.setMaxPooledConnections(50);
ds.setMaxPooledConnectionsPerNode(10);
// 获取连接
Connection conn = ds.getConnection();
使用 JDBC DriverManager API¶
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.Properties;
Properties props = new Properties();
props.setProperty("user", "app_user");
props.setProperty("password", "password");
props.setProperty("RoutableQueryEnable", "true");
props.setProperty("MaxPooledConnections", "50");
props.setProperty("MaxPooledConnectionsPerNode", "10");
String url = "jdbc:vertica://vertica.example.com:5433/mydb";
Connection conn = DriverManager.getConnection(url, props);
PooledConnection 设置¶
| 参数 | 说明 | 推荐值 |
|---|---|---|
MaxPooledConnections |
连接池最大总连接数 | 50-200(取决于并发需求) |
MaxPooledConnectionsPerNode |
每个节点的最大连接数 | 10-50 |
RoutableQueryEnable |
启用 Routable Query API | true |
ConnectionLoadBalance |
连接负载均衡 | true |
ConnectionTimeout |
连接超时时间(秒) | 30 |
创建查询¶
VGet 接口¶
VGet 接口适用于简单的按键查询,自动路由到数据所在节点执行。
import com.vertica.jdbc.routable.VGet;
import com.vertica.jdbc.routable.VGetFactory;
// 从连接创建 VGet 实例
VGet vget = VGetFactory.create(conn);
// 准备查询
String sql = "SELECT event_type, event_data FROM user_events WHERE user_id = ?";
// 绑定参数并执行
vget.prepare(sql);
vget.setInt(1, 10042);
// 执行查询
ResultSet rs = vget.executeQuery();
while (rs.next()) {
String eventType = rs.getString("event_type");
String eventData = rs.getString("event_data");
System.out.println(eventType + ": " + eventData);
}
// 重用 VGet 实例执行不同查询
vget.prepare("SELECT COUNT(*) FROM user_events WHERE user_id = ?");
vget.setInt(1, 10042);
ResultSet countRs = vget.executeQuery();
VerticaRoutableExecutor 接口¶
VerticaRoutableExecutor 接口提供更灵活的执行方式,支持批量操作和事务控制。
import com.vertica.jdbc.routable.VerticaRoutableExecutor;
import com.vertica.jdbc.routable.VerticaRoutableExecutorFactory;
// 创建执行器
VerticaRoutableExecutor executor =
VerticaRoutableExecutorFactory.create(conn);
// 批量执行点查
String sql = "SELECT event_type, event_data FROM user_events WHERE user_id = ?";
int[] userIds = {10042, 10043, 10044, 10045};
executor.prepare(sql);
for (int userId : userIds) {
executor.setInt(1, userId);
ResultSet rs = executor.executeQuery();
while (rs.next()) {
System.out.println("User " + userId + ": " +
rs.getString("event_type"));
}
}
验证单节点执行¶
使用 setFailOnMultiNodePlans 参数确保查询被路由到单个节点执行。如果查询计划涉及多个节点,连接将抛出错误。
// 设置仅在单节点计划时执行
conn.setFailOnMultiNodePlans(true);
VGet vget = VGetFactory.create(conn);
vget.prepare("SELECT * FROM user_events WHERE user_id = ?");
vget.setInt(1, 10042);
try {
ResultSet rs = vget.executeQuery();
// 查询成功:证明是单节点执行
while (rs.next()) {
// 处理结果
}
} catch (SQLException e) {
// 查询涉及多个节点时会抛出异常
System.err.println("查询无法在单节点执行: " + e.getMessage());
}
资源管理¶
为 Routable Query 创建专用资源池,确保简单查询不受复杂查询的资源争用影响。
-- 创建专用资源池
CREATE RESOURCE POOL routable_query_pool
EXECUTIONPARALLELISM 1
PRIORITY 10
MEMORYSIZE '256M'
MAXMEMORYSIZE '1G'
QUEUETIMEOUT '300'
PLANNEDCONCURRENCY 10;
-- 将 Routable Query 用户关联到专用资源池
ALTER USER app_user RESOURCE POOL routable_query_pool;
资源池参数说明¶
| 参数 | 说明 | 推荐值 |
|---|---|---|
EXECUTIONPARALLELISM |
查询执行并行度 | 1(单节点查询无需并行) |
PRIORITY |
优先级(0-100) | 10(高于批量任务) |
MEMORYSIZE |
最小内存保证 | 256M |
MAXMEMORYSIZE |
最大内存限制 | 1G |
QUEUETIMEOUT |
排队超时时间(秒) | 300 |
PLANNEDCONCURRENCY |
计划并发数 | 10-50 |
性能测试¶
测试结果对比¶
| 场景 | 并发数 | 吞吐量(qps) | 平均延迟(ms) | P99 延迟(ms) |
|---|---|---|---|---|
| 标准 JDBC | 10 | 12 | 83 | 210 |
| Routable Query | 10 | 192 | 5.2 | 15 |
| Routable Query | 50 | 850 | 5.8 | 22 |
| Routable Query | 100 | 1600 | 6.2 | 28 |
测试示意图¶
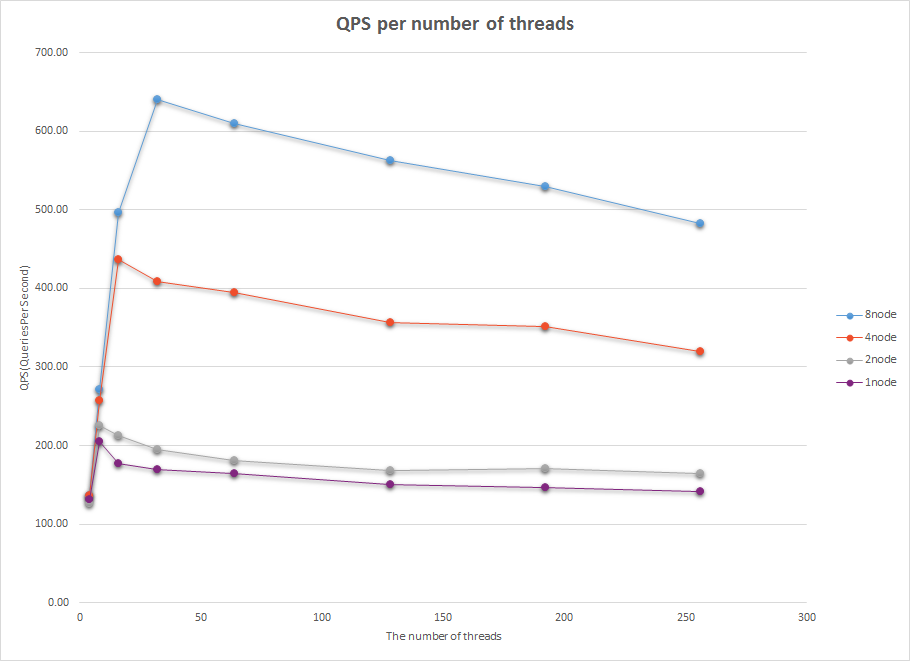
性能优化建议¶
- 连接池管理:合理设置
MaxPooledConnections和MaxPooledConnectionsPerNode - 资源池隔离:为 Routable Query 创建专用资源池并设置
EXECUTIONPARALLELISM=1 - 投影设计:确保查询列包含在分段投影中,避免需要从其他节点读取数据
- 批量操作:使用
VerticaRoutableExecutor的批量接口减少网络往返 - 监控与调优:定期监控
EXECUTION_ENGINE_PROFILES确认查询在单节点执行
扩展阅读¶
- Vertica 客户端驱动兼容性与升级指南 — 驱动版本与 JDBC 特性支持矩阵
- Vertica 资源池配置的最佳实践
- Vertica 低延迟优化最佳实践
- Vertica 投影优化最佳实践