Vertica 维护前准备 Checklist¶
概述¶
在对 Vertica 数据库执行计划性维护(硬件更换、OS 升级、机房搬迁等)之前,必须按照以下 checklist 安全关闭数据库:
- 检查节点依赖状态
- 备份数据库
- 安全关闭数据库
- 验证数据库是否已关闭
实际操作中,有时可能无法顺利关闭数据库。此时需要采取特定的步骤来安全关机,避免强制关机——强制关机可能导致数据全部丢失,并引发数据库重启问题。
1. 检查节点依赖状态¶
关机前的第一步是检查节点依赖。必须确认集群中所有节点上的 buddy projection 都在其他节点上正确配置了副本。
正确的节点依赖¶
节点依赖正确时,所有投影的 segment 和 buddy segment 位于同一对节点上。
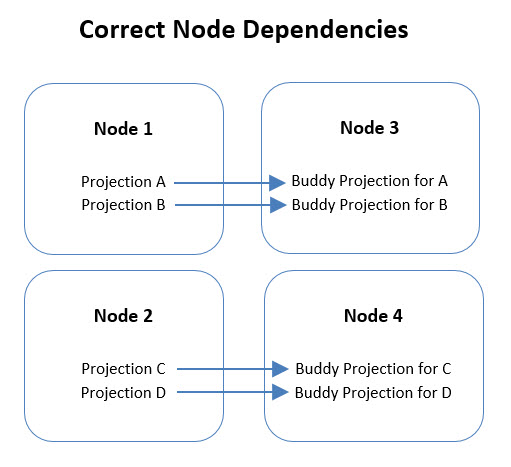
示例:一个 5 节点集群,共有 26 个分段投影(13 个投影 + 13 个 buddy)和 27 个非分段投影:
SELECT is_segmented, COUNT(*) FROM projections GROUP BY 1;
is_segmented | count
-------------+-------
f | 27 -- 非分段投影(所有节点上都有一份)
t | 26 -- 13 个投影 + 13 个 buddy = 26 个分段投影
SELECT GET_NODE_DEPENDENCIES();
GET_NODE_DEPENDENCIES
--------------------------------------------------------------
Deps:
00011 - cnt: 13
00110 - cnt: 13
01100 - cnt: 13
11000 - cnt: 13
10001 - cnt: 13
11111 - cnt: 27
如何解读结果:
- 一份干净的节点依赖列表应显示 (节点数 + 1) 行。每行显示一部分分段投影的数量,最后一行(全 1 行)显示非分段投影的数量。
- 在二进制位图中,每一位代表一个节点。例如
00011意味着 node 1 = 1、node 2 = 1、node 3 = 0、node 4 = 0、node 5 = 0。 - 1 表示 segment 存在该节点上,0 表示不存在。两个同时为 1 的节点互为 buddy。
错误的节点依赖¶
节点依赖不正确的原因包括:
- 未完成的重平衡(rebalance)
- 集群扩容
- Fault group 配置问题
当依赖不正确时,节点上的投影出现分裂依赖(split dependency)——一部分投影的 buddy segment 依赖某个节点,另一部分投影的 buddy segment 依赖另一个节点。
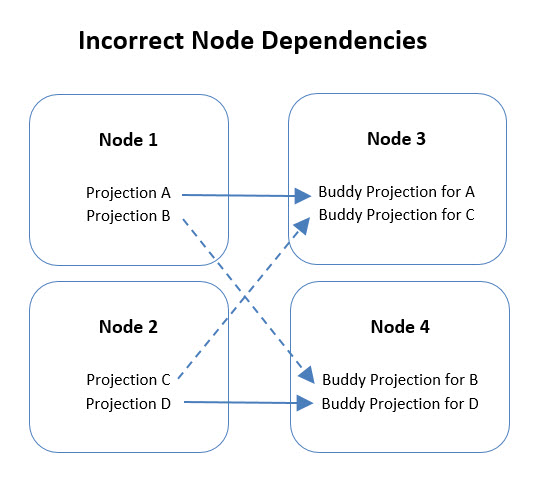
具体场景: 在一个经历过未完成 rebalance 的 5 节点集群中,节点 1 上的一部分投影的 buddy segment 在节点 2 上,而另一部分投影的 buddy segment 在节点 5 上。此时如果节点 1 宕机,节点 2 和节点 5 都会成为关键节点(critical node),因为它们各自持有一部分用于替代节点 1 数据副本的 buddy 数据。
同样是 26 个分段投影(13 个投影 + 13 个 buddy)和 27 个非分段投影,但依赖错误时的输出:
SELECT GET_NODE_DEPENDENCIES();
GET_NODE_DEPENDENCIES
----------------------------------------------------------------
Deps:
00011 - cnt: 3
00110 - cnt: 3
01100 - cnt: 3
11000 - cnt: 3
10001 - cnt: 3
00101 - cnt: 10 -- 额外出现的依赖行
01010 - cnt: 10
10100 - cnt: 10
01001 - cnt: 10
10010 - cnt: 10
11111 - cnt: 27
当依赖不正确时,3 个投影的 buddy segment 在同一节点上,而另外 10 个投影的 buddy segment 在另一个节点上。此时如果节点 1 宕机,它的 buddy segment 分散在节点 2、3、4、5 上,所有节点都变成关键节点。
⚠️ 最关键的警告: 如果在节点依赖不正确的情况下关机,之后又发生磁盘故障,此时要确定一个 K-safe 集群的节点依赖关系极其困难且耗时,这会大幅延长数据库的停机时间。
如何检查与修复¶
第 1 步: 重新计算节点依赖,确保读到最新状态。
第 2 步: 检查结果是否干净。
如果依赖不正确——先修复再关机:
使用以下命令同步重平衡集群并整理节点依赖:
如果重平衡后节点依赖仍然不正确,请联系 Vertica 技术支持。
2. 备份数据库¶
确认节点依赖正确后,即可开始备份数据库。先尝试标准方法(vbr.py),如果失败则使用冷备份(离线备份)。
方法 A:标准备份(使用 vbr.py 脚本)¶
执行 vbr.py 脚本的标准备份流程。详见产品文档 Backing Up and Restoring the Database。
方法 B:冷备份(离线备份)¶
如果标准备份无法完成,可以在数据库关机状态下执行冷备份:将 catalog 目录和 data 目录复制到另一个位置。
重要: 如果必须关机才能做冷备份,需要通过查询
NODES系统表获取 catalog 和 data 目录的正确路径。还可以查询STORAGE_LOCATIONS系统表查看数据存储位置。
正确的路径名称是: catalog 路径去掉 Catalog 子目录,data 路径去掉 SAL 子目录。备份时复制的是这些上级目录。
SELECT name, catalogpath, bdbpath FROM vs_NODES;
-[ RECORD 1 ]-----------------------------------------------------
name | v_test2_node0001
catalogpath | /home/dbadmin/test2/v_test2_node0001_catalog/Catalog
bdbpath | /home/dbadmin/test2/v_test2_node0001_data/SAL
根据以上查询结果,应备份的目录为:
| 类型 | 查询到的完整路径 | 实际要复制的路径(去掉尾部子目录) |
|---|---|---|
| Catalog | /home/dbadmin/test2/v_test2_node0001_catalog/Catalog |
/home/dbadmin/test2/v_test2_node0001_catalog/ |
| Data | /home/dbadmin/test2/v_test2_node0001_data/SAL |
/home/dbadmin/test2/v_test2_node0001_data/ |
每个节点都需要复制这两个目录。
3. 安全关闭数据库¶
备份完成后即可开始关机。关机过程可能需要一定时间,具体取决于集群当前的活动量以及 Vertica 在关机前需要移出(moveout)的数据量。
关机前 Vertica 的执行顺序是:先执行 Tuple Mover moveout,moveout 完成后才开始数据库关机流程。可以用 tail -f vertica.log(位于 catalog 目录下)持续监控关机进度。
关机开始前,Vertica 会进行两项检查:
- 检查活跃会话 — 如果存在活跃会话,关机不会执行,并提示有活跃会话存在的告警。
- 执行 moveout 操作 — 将 WOS(Write Optimized Store)中的数据移入 ROS(Read Optimized Store)。
使用 SELECT SHUTDOWN() 语句关机¶
以下为完整的逐步操作流程:
Step 1: 查看最大会话数¶
Step 2: 验证有哪些会话仍在运行¶
Step 3: 关闭所有会话¶
会话 ID 是一个字符串,用于指定要关闭的会话。该 ID 在集群中任何时间点都是唯一的,但会话关闭后可能会被重用。
Step 4: 阻止新连接¶
将 MaxClientSessions 配置参数设置为 0,阻止其他用户连接到数据库:
当
MaxClientSessions= 0 时,系统仍保留 5 个 dbadmin 会话。作为数据库管理员,你可以使用这些会话来执行必要的管理任务。
验证设置是否生效:
Step 5: 推进 AHM(Ancient History Mark)¶
推进 AHM 可以避免关机后在恢复时需要重放 delete vector:
Step 6: 执行 Tuple Mover moveout¶
将所有投影的数据从 WOS 移入 ROS:
如果不指定表名,Tuple Mover 会将所有表的 WOS 数据全部移出。
Step 7: 验证 WOS 已清空¶
查询 resource_pool_status 确认所有节点的 WOS 数据已清空为 0:
SELECT node_name, SUM(memory_inuse_kb)
FROM resource_pool_status
WHERE pool_name = 'wosdata'
GROUP BY 1 ORDER BY 1;
-- 期望输出(所有节点 WOS 为 0):
node_name | sum
---------------------+-----
v_vmart_db_node0001 | 0
v_vmart_db_node0002 | 0
v_vmart_db_node0003 | 0
v_vmart_db_node0004 | 0
v_vmart_db_node0005 | 0
(5 rows)
Step 8: 关闭数据库¶
也可以通过 Management Console 和 Administration Tools 关闭数据库。详见 Vertica 文档中的 Stopping a Database。
⚠️ 如果无法正常关机,不要强制关闭数据库。 请联系 Vertica 技术支持。
4. 验证关机完成¶
在执行维护操作之前,必须确认数据库已经无任何错误地关闭。
验证方法一:admintools 查看集群状态¶
在 Linux 命令行执行,确认所有节点都为 DOWN 状态:
数据库在所有节点都 DOWN 之前不会完全关闭。
验证方法二:检查 vertica.log 中的关机完成消息¶
验证每个节点的 vertica.log 文件中是否包含 Shutdown complete 消息。根据你的 catalog 目录路径修改命令中的 find 路径:
for host in $(grep "^v_" /opt/vertica/config/admintools.conf | awk '{print $3}' | awk -F, '{print $1}'); do
echo "----- $host -----"
ssh $host "find /home/dbadmin/test2/ -name vertica.log | xargs grep '<INFO> Shutdown complete.'"
done
验证方法三:确认 vertica 进程已不存在¶
验证所有节点上都没有 vertica 进程在运行:
for host in $(grep "^v_" /opt/vertica/config/admintools.conf | awk '{print $3}' | awk -F, '{print $1}'); do
echo "---- $host ----"
ssh $host "ps -ef | grep /opt/vertica/bin/vertica"
done
如果数据库没有正常关闭¶
如果关机过程没有进展,或耗时超出预期:
1. 持续监控日志文件:
2. 在无法正常关闭的节点上,收集 vstack 信息:
将输出的 vstack_nodexx.log 文件发送给 Vertica 技术支持进行分析。
最后手段:强制关机¶
如果无法正常关闭,只能在万不得已时采取以下措施。
原理: 关闭具有相同依赖关系的节点。当一对 buddy 节点(共享同一依赖关系的两个节点)都 DOWN 时,Vertica 会因 K-safety 约束自动完成剩余节点的关机。
操作步骤:
- 使用 Administration Tools:
- 进入 Advanced Menu
- 选择 Stop Vertica on Host — 选择要关闭的节点
- 如果 Stop Vertica on Host 失败,在同一菜单中选择 Kill a Vertica Process on Host
完成以上步骤,数据库安全关闭后,即可执行计划性维护。
流程总览¶
┌──────────────────────────────┐
│ 1. 检查节点依赖 │
│ RECOMPUTE_NODE_DEPENDENCIES │
│ GET_NODE_DEPENDENCIES │
│ └─ 不正确 → REBALANCE_CLUSTER│
└──────────────┬───────────────┘
│ 依赖干净 ✓
▼
┌──────────────────────────────┐
│ 2. 备份数据库 │
│ 首选 vbr.py │
│ 备选 冷备份(复制目录) │
└──────────────┬───────────────┘
│ 备份完成 ✓
▼
┌──────────────────────────────┐
│ 3. 安全关机 │
│ a. 查看会话 → CLOSE_ALL │
│ b. MaxClientSessions = 0 │
│ c. MAKE_AHM_NOW │
│ d. DO_TM_TASK('moveout') │
│ e. 验证 WOS = 0 │
│ f. SELECT SHUTDOWN() │
└──────────────┬───────────────┘
│ 关机完成 ✓
▼
┌──────────────────────────────┐
│ 4. 验证关机 │
│ admintools -t view_cluster │
│ grep 'Shutdown complete' │
│ ps -ef | grep vertica │
└──────────────────────────────┘
│ 全部确认 ✓
▼
可以执行维护了
关键命令速查¶
| 步骤 | 目的 | 命令 |
|---|---|---|
| 1 | 重算节点依赖 | SELECT RECOMPUTE_NODE_DEPENDENCIES(); |
| 1 | 查看节点依赖 | SELECT GET_NODE_DEPENDENCIES(); |
| 1a | 修复依赖 | SELECT REBALANCE_CLUSTER(); |
| 2 | 标准备份 | vbr.py 脚本 |
| 2 | 冷备份 | 复制 catalog/ 和 data/ 目录(去 /Catalog /SAL 后缀) |
| 3a | 查看会话 | SELECT * FROM SESSIONS; |
| 3b | 关闭会话 | SELECT CLOSE_ALL_SESSIONS(); |
| 3c | 阻止新连接 | ALTER DATABASE <name> SET MaxClientSessions = 0; |
| 3d | 推进 AHM | SELECT MAKE_AHM_NOW(); |
| 3e | WOS → ROS | SELECT DO_TM_TASK('moveout'); |
| 3f | 验证 WOS=0 | wosdata pool memory_inuse_kb = 0 |
| 3g | 关机 | SELECT SHUTDOWN(); |
| 4 | 验证集群状态 | admintools -t view_cluster |
| 4 | 验证关机日志 | grep 'Shutdown complete.' vertica.log |
| 4 | 验证进程停止 | ps -ef | grep vertica |
| 4 | 收集诊断信息 | vstack > /tmp/vstack_nodexx.log |
| 最后 | 强制关机(仅最后手段) | admintools → Advanced → Stop/Kill Vertica on Host |
扩展阅读¶
- ROS Bundling 最佳实践 — 升级后执行 COMPACT_STORAGE 加速备份
- Vertica 备份与恢复方案总览 — 备份是维护前第 2 步
- K-Safety 最佳实践 — 节点依赖与数据安全
- Vertica dbadmin 密码过期处理与自动化管理 — 维护前必查密码状态
- Vertica 数据库的启动和关闭 — 数据库启停操作