Tuple Mover 最佳实践完全指南¶
整合自 Vertica 官方 KB 两篇 Tuple Mover 最佳实践文章,标注了版本差异。
1. 版本适用性速查¶
本指南分为两大部分,适用不同版本:
| 部分 | 原文 | 适用版本 | 核心特征 |
|---|---|---|---|
| Part A | KB: Tuple Mover Best Practices: Part 1 | Vertica ≤ 9.1 | 有 WOS + Moveout + Mergeout |
| Part B | KB: Tuple Mover Best Practices: Part 2 | Vertica ≥ 9.2 | 无 WOS,仅 Mergeout,新增 Reflexive Mergeout |
关键变化:Vertica 9.2+ 移除了 WOS(Write Optimized Store),数据直接写入 ROS。所有 Moveout / WOSDATA 相关概念在 ≥9.2 版本中不再适用。
阅读时请注意标注 🟠 ≤9.1 only(仅旧版)和 🟢 ≥9.2(新版)的区域。
2. Tuple Mover 架构演变¶
2.1 旧版架构(≤9.1)¶
┌──────────────────────────────────────────────────┐
│ Tuple Mover │
│ │
│ ┌─────────┐ Moveout ┌─────────┐ │
│ │ WOS │ ───────────────► │ ROS │ │
│ │ (内存) │ │ (磁盘) │ │
│ │ ≤2GB │ │ ≤1024 │ │
│ └─────────┘ │ 容器/投影│ │
│ │ /节点 │ │
│ └────┬────┘ │
│ │ │
│ Mergeout │ │
│ (合并+清理) ▼ │
│ ┌─────────┐ │
│ │ ROS 容器 │ │
│ │ 合并为 │ │
│ │ 更少容器 │ │
│ └─────────┘ │
└──────────────────────────────────────────────────┘
- Moveout:将 WOS(内存)中的数据搬迁到 ROS(磁盘),1 个线程
- Mergeout:合并 ROS 容器 + 清理已删除数据,2 个线程(默认)
2.2 新版架构(≥9.2)¶
┌──────────────────────────────────────────────────┐
│ Tuple Mover │
│ (仅 Mergeout) │
│ │
│ INSERT/COPY ──► ROS ──► Mergeout ──► 合并后容器 │
│ (直接写入) 容器 线程 │
│ │
│ ┌──────────────────────────────────────────┐ │
│ │ Reflexive Mergeout (≥9.2) │ │
│ │ │ │
│ │ DML提交 ──► 计数器++ ──► 达阈值? ──► 入队 │ │
│ │ │ │
│ │ MergeoutRequestTracker 主动推送任务 │ │
│ └──────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘
- 无 Moveout:数据直接进入 ROS
- Reflexive Mergeout:事件驱动,不再依赖轮询间隔
- MergeoutRequestTracker:跟踪每个 projection 的容器数/删除向量数
2.3 Eon Mode(≥9.2)¶
┌─────────────────────────────────────────────────────┐
│ Eon Mode │
│ │
│ Primary Subscriber ──► 规划 Mergeout(每个 shard)│
│ │ │
│ │ 11.0.2+: 可委托执行 │
│ ▼ │
│ ┌─────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Node 1 │ │ Node 2 │ │ Node 3 │ │
│ │ Primary │ │ Secondary│ │ Secondary│ │
│ │ 执行 │ │ TM Pool │ │ TM Pool │ │
│ │ mergeout│ │ = 0 │ │ = 0 │ │
│ │ │ │ (禁用) │ │ (禁用) │ │
│ └─────────┘ └──────────┘ └──────────┘ │
│ │
│ S3 (共享存储): 所有 ROS 容器 │
└─────────────────────────────────────────────────────┘
- Primary Subscriber 为每个 shard 规划 mergeout
- 11.0.2+ 可委托给其他节点执行
- Secondary subcluster 可通过
TM 资源池 MEMORYSIZE=0禁用 mergeout
3. 🟢 Reflexive Mergeout 详解¶
本节内容仅适用于 Vertica ≥ 9.2。
3.1 旧版 Mergeout 的弊端¶
在 Reflexive Mergeout 引入之前,Tuple Mover 基于固定调度运行:
旧版 (基于 MergeOutInterval, 默认 600s):
Thread 0: [sleep 600s] → [遍历整个 catalog] → [找任务] → [执行] → ...
Thread 1: [sleep 600s] → [遍历整个 catalog] → [找任务] → [执行] → ...
问题:
┌─────────────────────────────────────────────┐
│ 1. 每个线程独立遍历整个 catalog,重复劳动 │
│ 2. 线程之间可能冲突,丢弃任务重新开始 │
│ 3. ROS 容器可能在下一次轮询前就已经爆炸 │
│ 4. 不管有没有工作要做,线程都会醒来遍历 │
└─────────────────────────────────────────────┘
3.2 Reflexive Mergeout 架构¶
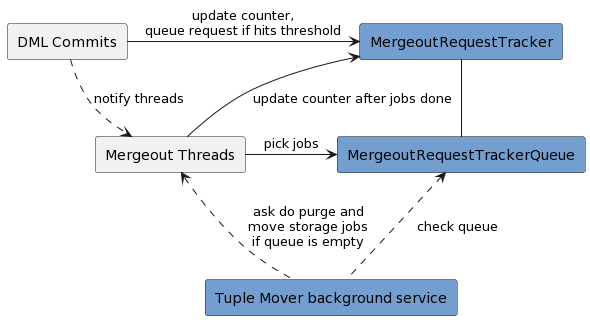
Reflexive Mergeout 将 Tuple Mover 从轮询式改为事件驱动式,核心组件是 MergeoutRequestTracker:
┌─────────────────────────────────────────────────────────────┐
│ Reflexive Mergeout 架构 │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ MergeoutRequestTracker │ │
│ │ │ │
│ │ 每个 projection 维护: │ │
│ │ ┌─────────────────────────────────────────────┐ │ │
│ │ │ • container_count_since_mergeout │ │ │
│ │ │ • container_count_since_last_request │ │ │
│ │ │ • max_dv_count_for_dml (最大 delete vector) │ │ │
│ │ │ • last_mergeout_time │ │ │
│ │ │ • last_dv_mergeout_time │ │ │
│ │ │ • minimum_purge_eligible_epoch │ │ │
│ │ │ • mergeout_container_count_threshold (阈值) │ │ │
│ │ └─────────────────────────────────────────────┘ │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ DML 提交 ──► 计数器++ ──► 达阈值? ──► 入队请求 │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Mergeout 请求队列 │ │
│ │ (Request Queue) │ │
│ └──────────┬───────────┘ │
│ │ │
│ 通知 Mergeout 线程 │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Mergeout Thread │ │
│ │ 取请求 → 执行 → │ │
│ │ 更新计数器 │ │
│ └──────────────────────┘ │
│ │
│ 队列空时 → 后台线程 fallback: 遍历所有 projection 找任务 │
└─────────────────────────────────────────────────────────────┘
3.3 部署方式¶
| 模式 | MergeoutRequestTracker 位置 | Mergeout 执行者 |
|---|---|---|
| Enterprise Mode | 每个节点维护自己的 tracker | 每个节点独立执行 |
| Eon Mode | 所有节点都维护 tracker | 仅 Primary Subscriber 处理 mergeout 请求 |
3.4 触发条件¶
Mergeout 请求通过以下条件触发入队:
条件 1:ROS 容器累积(MERGEOUT 请求)
DML 提交
│
▼
container_count_since_last_request ≥ mergeout_container_count_threshold
│
▼
入队 MERGEOUT 请求
阈值(mergeout_container_count_threshold)会根据以下因素动态重新计算:
- ADD/DROP COLUMN 操作
- ContainersPerProjectionLimit 参数变更
- MaxROSPerStratum 参数变更
条件 2:Delete Vector 累积(DV MERGEOUT 请求)
DML 提交 (含 DELETE)
│
▼
max_dv_count_for_dml ≥ MaxDVROSPerContainer(默认 10)
│
▼
入队 Delete Vector Mergeout 请求
条件 3:过期数据清理(PURGE 请求)
3.5 工作流程¶
1. DML 提交
└─► MergeoutRequestTracker 更新该 projection 的计数器
2. 计数器达到阈值
└─► 请求入队 (vs_mergeout_request_tracker_queue)
3. Mergeout 线程被通知(不是轮询发现!)
└─► 从 MergeoutRequestTracker 取请求
4. 队列有请求?
├─ YES → 取出执行 → 完成后更新计数器
└─ NO → 后台 Tuple Mover 服务检查队列
├─ 队列空 → 线程遍历所有 projection 找任务 (fallback)
└─ 队列有 → 回到步骤 4
5. Fallback 机制
└─► 由 MergeOutInterval 参数控制休眠间隔
└─► 仅在 Reflexive 机制未产生任务时启用
3.6 关键优势¶
| 旧版(轮询) | Reflexive(事件驱动) |
|---|---|
| 线程定期醒来,无差别扫描 catalog | DML 提交时精准触发 |
| 线程间可能冲突、丢弃任务 | 集中式 tracker 无冲突 |
| 可能已经 pushback 了才发现 | 抢占式:在达到 pushback 之前触发 |
| 全量扫描开销大 | 增量计数器,开销极小 |
| 轮询间隔内 ROS 容器无管控 | 实时追踪,即时响应 |
4. Mergeout STRATA 算法详解¶
Part A 和 Part B 中算法原理一致,以下合并说明。
4.1 算法原理¶
Tuple Mover 使用分层(strata)算法来决定合并哪些 ROS 容器。核心目标:每个 tuple 在整个生命周期中只被 mergeout 合并常数次,无论数据加载方式如何。
ROS 容器按大小分层
Stratum N │ ● ← 最大 ROS 容器(高层)
│
Stratum 2 │ ● ● ●
│
Stratum 1 │ ● ● ● ● ●
│
Stratum 0 │ ● ● ● ● ● ● ● ● ← 微小 ROS(≤1MB/列)
└──────────────────────────► ROS 容器大小
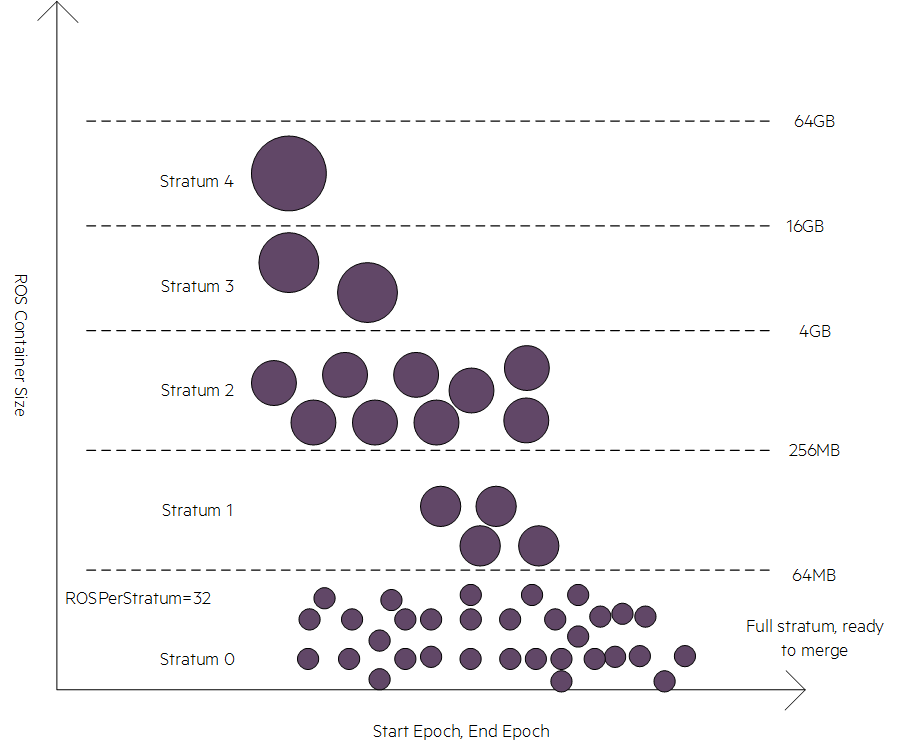
4.2 算法步骤¶
1. 从 Stratum 0(最小层)开始向上扫描
2. 检查每个 stratum 中的 ROS 容器数是否 ≥ ROSPerStratum(默认 32)
3. 若 stratum 满了 → 标记该 projection 为 mergeout 候选
4. 从满的 stratum 中取出 ROSPerStratum 个容器合并
5. 生成的新容器通常归入下一层(更大的 stratum)
6. 例外:Stratum 0 合并所有符合条件的容器(不限于 32 个)
4.3 线程分配规则¶
| 线程 | ≤9.1 行为 | 9.2-9.3 行为 | ≥10.0 行为 |
|---|---|---|---|
| Thread 0 | 处理所有 strata,也处理非活跃分区 | 处理所有 strata + 非活跃分区 | 半数线程处理活跃+非活跃,半数只处理活跃 |
| Thread 1+ | 只处理低层 strata | 只处理低层 strata(除首尾线程外) | 同上 |
| 非活跃分区 | 仅 Thread 0 | 仅首尾线程 | 半数线程可处理 |
线程 0 只在没有其他 projection 符合 strata 算法条件时,才会处理非活跃分区。
4.4 活跃分区 vs 非活跃分区¶
┌─────────────────────────────────────────────────────┐
│ 分区表 Mergeout 行为 │
│ │
│ 活跃分区 (ActivePartitionCount 控制数量) │
│ ┌──────────┐ │
│ │ 使用 STRATA 算法 │ ← 每个活跃分区独立构建 strata │
│ │ 动态合并 │ │
│ └──────────┘ │
│ │
│ 非活跃分区 │
│ ┌──────────┐ │
│ │ 合并到最少容器数 │ ← 通常每个非活跃分区 1 个 ROS │
│ │ (不跨分区合并) │ │
│ └──────────┘ │
│ │
│ ⚠️ Vertica 不会跨分区合并 ROS 容器! │
│ 因此数百个分区 = 数百个 ROS 容器(仅非活跃部分) │
└─────────────────────────────────────────────────────┘
5. 投影设计最佳实践¶
5.1 排序列(Sort Order)¶
| 建议 | ≤9.1 | ≥9.2 | 原因 |
|---|---|---|---|
| 排序列数量 | ≤10 列 | ≤8 列 | 太多排序列拖慢 mergeout |
| 宽 VARCHAR | 避免 | 严格避免 | VARCHAR 排序极慢 |
| 高基数列放最后 | ✓ | ✓ | 加速 replay delete |
| Row Length | 未提及 | <10,000 | 超过 10K 性能显著下降 |
为什么排序列影响 mergeout? Mergeout 需要重排数据以维护排序顺序,排序列越多、越宽,每次 mergeout 耗时越长。长耗时的 mergeout 会阻塞其他 mergeout 任务,导致 ROS 容器堆积。
5.2 投影集数量¶
🟠 ≤9.1 only:每个表不要超过 2 套投影集(projection set),超过会浪费资源且增加 mergeout 负担。
🟢 ≥9.2:Part 2 未再强调此限制,但仍是合理建议。
5.3 宽表特殊处理¶
如果表包含 >100 列(≤9.1)或 >100 列且 row_length > 10,000(≥9.2):
Mergeout 吞吐量 < 1 GB/分钟?
│
├── YES → 增大 TM 资源池
│ ≤9.1: 增加 memorySize + maxMemorySize
│ ≥9.2: MEMORYSIZE = 5% 可用内存 或 10GB(取小值)
│ PLANNEDCONCURRENCY = 3
│
└── NO → 当前配置合理
6. 分区最佳实践¶
6.1 分区数量¶
| 建议 | 细节 |
|---|---|
| 上限 | 每表 ≤ 50 个分区(理想),或至少远小于 1024 |
| 原因 | Vertica 不跨分区合并 ROS 容器,几百个分区 = 几百个最小 ROS 容器数 |
6.2 ActivePartitionCount¶
默认值 1,表示只有最新分区为「活跃」分区,使用 STRATA 算法动态合并。
如果频繁向多个分区写入数据(如同时写入今天、昨天、前天的分区):
有客户在正确设置此参数后观察到显著的集群性能提升。
6.3 层级分区(Hierarchical Partitioning)¶
🟢 ≥9.0:推荐使用层级分区减少 ROS 容器数。例如按 (year, month, day) 层级分区,比单纯按 date 进行范围分区更高效。
6.4 归档老旧分区¶
对于不再访问的旧分区,移入归档表:
=> SELECT MOVE_PARTITION_TO_TABLE(
'source_table', 'min-range-value', 'max-range-value', 'archive_table'
);
6.5 分区重组¶
修改分区表达式后,必须重组,否则旧 ROS 容器不会被 mergeout 考虑:
-- 检查是否有未完成的重组
=> SELECT table_schema, projection_name
FROM partition_status
WHERE partition_reorganize_percent <> 100;
-- 触发重组
=> ALTER TABLE <table_name> REORGANIZE;
7. TM 资源池配置¶
7.1 参数速查¶
TM Resource Pool
┌─────────────────────────────────┐
│ MEMORYSIZE ← 单线程内存 │
│ MAXMEMORYSIZE ← 内存上限 │
│ PLANNEDCONCURRENCY ← 预期并发 │
│ MAXCONCURRENCY ← 最大线程数 │
└─────────────────────────────────┘
7.2 线程数调整¶
| 场景 | ≤9.1 | ≥9.2 |
|---|---|---|
| 默认 | 3(1 moveout + 2 mergeout) | 取决于资源池(通常 3) |
| 需要增加时 | MAXCONCURRENCY=4 | PLANNEDCONCURRENCY + MAXCONCURRENCY 调大 |
| 上限 | ≤6(超过影响集群性能) | 未硬性限制,但需谨慎 |
| 窄表/正常 | 不需要调整 | 不需要调整 |
7.3 ≥9.2 版本内存建议¶
MAX(5% × 节点可用内存, 10GB) → 但不超过 10GB
│
▼
┌───────────────┐
│ 观察 mergeout │
│ 吞吐量是否 │── < 1 GB/min ──► 增大 MEMORYSIZE
│ ≥ 1 GB/min │
└───────┬───────┘
│ ≥ 1 GB/min
▼
┌───────────────┐
│ 配置合理 │
└───────────────┘
8. 删除(Delete)与 Replay Delete¶
8.1 问题根源¶
DELETE 操作
│
▼
创建 Delete Vector(标记删除的行)
│
▼
Mergeout 时遇到 Delete Vector
│
▼
Replay Delete: 逐行检查并跳过已删除数据
│
▼
⚠️ 如果 delete vector 很多 → replay delete 极慢
→ block mergeout 线程 → ROS 容器堆积 → pushback
8.2 优化策略¶
-
投影设计:将高基数列放在排序列最后一位
-
批量删除:尽量批量 DELETE/UPDATE,避免频繁小手笔删除
-
使用 WOS 暂存删除(仅 ≤9.1):WOS 将多次删除合并为更少的 delete vector
-
卡住的 replay delete:
-
🟢 ≥9.2 新增:
purge_table()手动清理:
8.3 ReplayDeleteAlgorithmSwitchThreshold¶
如果 replay delete 持续很慢且 projection 未优化:
9. 配置参数速查表¶
9.1 全版本通用参数¶
| 参数 | 默认值 | 功能 | 调优建议 |
|---|---|---|---|
| ROSPerStratum | 32 | 每个 stratum 中 ROS 容器数上限,达到则触发 mergeout | 降低 → 减少 ROS 容器数,但增加 I/O(更多 mergeout) |
| MaxDVROSPerContainer | 10 | 单个 ROS 容器关联的 delete vector 上限,超过触发合并 | 通常不需调整 |
| PurgeMergeoutPercent | 20 | 非活跃分区中删除数据占比超过此值才触发 purge | 通常不需调整 |
| ContainersPerProjectionLimit | 1024 | 每节点每投影的 ROS 容器上限 | 不建议调大,会导致列数据碎片化、查询性能下降 |
| MergeOutInterval | 600s | Mergeout 休眠间隔(秒) | 仅当 ROS 容器在休眠期内高速产生时缩短 |
9.2 🟠 ≤9.1 独有参数¶
| 参数 | 默认值 | 功能 |
|---|---|---|
| MoveOutInterval | 300s | Moveout 休眠间隔 |
| MoveOutSizePct | — | WOS 占用超过此百分比才触发 moveout(适用少量表大量写入的场景) |
| MoveOutMaxAgeTime | 1800s | 数据在 WOS 中驻留超过此时间强制 moveout |
9.3 🟢 ≥9.2 Reflexive Mergeout 行为变化¶
旧版 (基于 MergeOutInterval):
[sleep 600s] → [遍历 catalog] → [找任务] → [执行] → [sleep 600s] → ...
↑_____________________________|
新版 (Reflexive Mergeout, ≥9.2):
DML 提交 → 计数器++ → 达阈值 → 入队 → 通知线程 → 立即执行
│
队列空时 → fallback: 遍历所有 projection 找任务
旧版的 MergeOutInterval 参数在 Reflexive Mergeout 启用后影响降低,但仍作为 fallback 机制的轮询间隔。
详见第 3 节"Reflexive Mergeout 详解"了解完整原理。
10. 监控与诊断¶
10.1 ROS 容器数(全版本)¶
-- 检查各节点各投影的 ROS 容器数
=> SELECT node_name, schema_name, projection_name,
sum(delete_vector_count) delete_vector_count,
count(*) ROS_container_count,
sum(delete_vector_count) + count(*) total_container_count
FROM storage_containers
GROUP BY 1, 2, 3
ORDER BY 6 DESC;
10.2 活跃分区查询¶
-- Part A 写法(≤9.1)
=> SELECT DISTINCT partition_key FROM strata
WHERE projection_name = '<projection_name>'
AND schema_name = '<schema>';
-- Part B 写法(≥9.2)
=> SELECT DISTINCT stratum_key FROM strata
WHERE projection_name = '<PROJECTION_NAME>'
AND schema_name = '<SCHEMA_NAME>';
10.3 🟢 Mergeout 性能监控(≥9.2 详细版)¶
SELECT
dtme.node_name,
dtme.transaction_id,
dtme.projection,
dtme.table_name,
dtme.container_count,
dtme.total_size_in_gb,
dtme.start_time,
dtme.complete_time,
dtme.epochs,
dtme.number_of_columns,
dtme.columns_in_sort_order,
dtme.row_length,
dtme.number_of_wide_1k_cols,
dtme.widest_col,
dtme.mergeout_time,
dtme.mergeout_throughput||' GB/Min' mergeout_throughput,
dtme.include_replay_delete,
dra.memory_mb,
des.bytes_spilled
FROM (
SELECT
s.node_name,
s.transaction_id,
s.schema_name||'.'||s.projection_name projection,
s.table_name,
s.container_count,
(s.total_size_in_bytes / 1024^3)::NUMERIC(10,2) total_size_in_gb,
s.time start_time,
c.time complete_time,
(s.end_epoch - s.start_epoch) epochs,
projcols number_of_columns,
sortkey columns_in_sort_order,
col.row_length,
col.cnt_widecols number_of_wide_1k_cols,
col.widest_col,
DATEDIFF(MINUTE, s.time, c.time) mergeout_time,
TRUNC(s.total_size_in_bytes / 1024^3 / NULLIFZERO(DATEDIFF(MINUTE, s.time, c.time)), 3)::NUMERIC(5,3) mergeout_throughput,
CASE WHEN c.plan_type = 'Replay Delete' THEN true ELSE false END include_replay_delete
FROM dc_tuple_mover_events s
JOIN dc_tuple_mover_events c
ON s.node_name = c.node_name
AND s.projection_oid = c.projection_oid
AND s.transaction_id = c.transaction_id
AND s.total_size_in_bytes = c.total_size_in_bytes
AND s.session_id = c.session_id
AND s.operation = 'Mergeout'
AND c.operation = 'Mergeout'
AND s.event = 'Start'
AND c.event = 'Complete'
JOIN vs_projections p ON p.oid = s.projection_oid
JOIN (
SELECT t_oid,
SUM(attlen) row_length,
COUNT(CASE WHEN attlen >= 1000 THEN 1 ELSE NULL END) cnt_widecols,
MAX(attlen) widest_col
FROM vs_columns GROUP BY 1
) col ON t_oid = p.anchortable
) dtme
JOIN (
SELECT node_name, transaction_id, (MAX(memory_kb) / 1024)::INT memory_mb
FROM dc_resource_acquisitions
WHERE pool_name = 'tm'
GROUP BY 1, 2
) dra USING (node_name, transaction_id)
JOIN dc_Execution_summaries des USING (node_name, transaction_id)
WHERE dtme.total_size_in_gb > 1
ORDER BY
dtme.mergeout_time DESC,
dtme.mergeout_throughput,
dtme.total_size_in_gb DESC;
10.4 🟢 Reflexive Mergeout 监控(≥9.2)¶
-- MergeoutRequestTracker 状态
=> SELECT
mrts.node_name,
prj.projection_schema || '.' || prj.projection_name projection_name,
mrts.mergeout_container_count_threshold,
mrts.container_count_since_mergeout,
mrts.container_count_since_last_request,
mrts.last_mergeout_time,
mrts.dv_count_threshold,
mrts.max_dv_count_for_dml,
mrts.last_dv_mergeout_time,
mrts.minimum_purge_eligible_epoch
FROM
vs_mergeout_request_tracker_status mrts
JOIN projections prj ON mrts.projection_id = prj.projection_id;
-- MergeoutRequestTracker 队列
=> SELECT
mrtq.node_name,
prj.projection_schema || '.' || prj.projection_name projection_name,
mrtq.request_id,
mrtq.request_type, -- MERGEOUT 或 PURGE
mrtq.storage_creation_rate,
mrtq.stratum,
mrtq.request_created_time
FROM
vs_mergeout_request_tracker_queue mrtq
JOIN projections prj ON mrtq.projection_id = prj.projection_id;
10.5 检查分区数(全版本)¶
=> SELECT node_name, table_schema, projection_name,
count(DISTINCT partition_key)
FROM PARTITIONS
GROUP BY 1, 2, 3
ORDER BY 3 DESC;
11. 常见问题 FAQ¶
11.1 Mergeout 相关¶
Q: Mergeout 会清理已删除数据吗?
仅当删除发生在 AHM(Ancient History Mark)之前,且该 ROS 容器符合 strata 算法条件。对于非活跃分区,还需删除比例超过 PurgeMergeoutPercent(默认 20%)。
Q: 可以增加 mergeout 线程数吗?
| 版本 | 限制 |
|---|---|
| ≤9.1 | 最多 6,超过损害性能 |
| 9.2-9.3 | 仅首尾线程处理非活跃分区 |
| ≥10.0 | 半数线程处理活跃+非活跃,半数只处理活跃 |
Q: 非活跃分区为什么没被合并?
🟢 ≥10.0.1 新增规则:当 ROS 容器数超过 ContainersPerProjectionLimit 的一半时,不再跳过超大 ROS 文件(旧版会跳过「比其余容器总和大 10 倍以上」的单个 ROS 文件,避免无意义的 I/O)。
11.2 🟠 Moveout 相关(≤9.1 only)¶
Q: 可以增加 moveout 线程数吗?
不能。Moveout 始终只有 1 个线程,不可调整。
Q: Moveout 会因为什么失败?
- 无法获取 T 锁(长事务持有 X 锁阻塞)
- 目标 ROS 容器正在被长时间运行的 mergeout 使用
- 单表向 WOS 加载了超过 1024 个分区
Q: Moveout 获取什么锁?
| 操作 | 锁类型 |
|---|---|
| 移动 WOS → ROS | U 锁(Update Lock) |
| 管理 delete marks / replay deletes | T 锁(Tuple Lock) |
11.3 Eon Mode 相关¶
Q: Eon Mode 下 mergeout 在哪个节点执行?
Primary Subscriber 规划,默认自己执行。≥11.0.2 可委托给其他节点。
Q: 如何禁止 secondary subcluster 执行 mergeout?
-- 将 secondary subcluster 的 TM 资源池设为 0
=> ALTER RESOURCE POOL tm FOR SUBCLUSTER secondary_sc MEMORYSIZE '0';
=> ALTER RESOURCE POOL tm FOR SUBCLUSTER secondary_sc MAXMEMORYSIZE '0';
Primary Subscriber 会忽略 TM 资源池为 0 的 subcluster 中的节点。
11.4 ≥11.0 新增功能¶
Q: 如何对特定表禁用 mergeout?
12. 故障排查路径图¶
ROS Pushback / Mergeout 问题
│
┌─────────────┼─────────────┐
▼ ▼ ▼
合并太慢? 容器太多? 写太快?
│ │ │
┌───────────┤ ┌───────┤ ┌───────┤
▼ ▼ ▼ ▼ ▼ ▼
宽表? replay 分区 未重组 trickle 分区
增大TM delete? 太多? 分区? load? 太多?
资源池 优化投影 减少 执行 去掉 使用
推进AHM 分区 REORG DIRECT 层级
高基数列 归档 ANIZE hint 分区
排最后 老旧
分区
13. 相关笔记¶
- ROS Pushback 故障排查 — 8 种常见 ROS pushback 场景及解决方案
- Vertica 数据库 Replay Delete 算法 — Replay Delete 算法原理与调优
- 理解 Vertica 的分区 — 分区表设计与管理
版本声明:本指南整合自 Vertica 官方 KB 文章(Part 1: ≤9.1 / Part 2: ≥9.2),标注 🟠(仅旧版)和 🟢(新版)记号。请根据您的 Vertica 版本选择性阅读。