Vertica 泊松回归实战¶
编译:JiangChong 原文:Poisson Regression
概述¶
泊松回归是一种广义线性模型(Generalized Linear Model, GLM),常用于建模计数数据(count data)。典型应用场景包括:
- 呼叫中心呼叫量预测(劳动力分配优化)
- 交通流量预测(智能交通管理)
- 健康保险理赔次数预测(精算定价)
泊松回归假设响应变量 Y 服从泊松分布,这是一种离散概率分布,用于描述在固定时间间隔内发生给定数量事件的概率。下图展示了三个不同参数 λ 的泊松分布概率质量函数(PMF)(来源:Wikipedia,许可:CC BY 3.0):
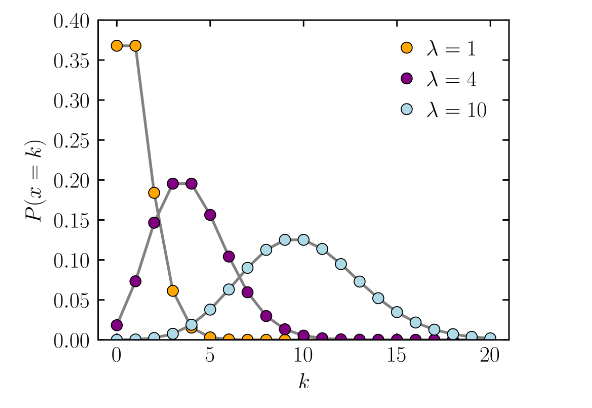
图中 x 轴 k 代表事件发生次数,y 轴 P(x=k) 代表实际次数等于 k 的概率。参数 λ 表示期望发生率。
数据集¶
本文使用 French Motor Claims Dataset(来源:Kaggle)来训练和评估泊松回归模型。该数据集包含 677,991 条机动车第三方责任险保单记录(一个会计年度内的观测数据)。模型将利用风险特征来预测理赔频率。本文的分析思路受参考文献 [1] 和 [2] 的启发。
首先,使用以下命令创建并加载数据表:
CREATE TABLE claims(IDpol INT, ClaimNb INT, Exposure FLOAT, Area VARCHAR, VehPower INT, VehAge INT, DrivAge INT,
BonusMalus INT, VehBrand VARCHAR, VehGas VARCHAR, Density INT, Region VARCHAR);
COPY claims FROM LOCAL 'path_to_data/freMTPL2freq.csv' WITH DELIMITER ',';
查看前 5 行样本数据:
IDpol | ClaimNb | Exposure | Area | VehPower | VehAge | DrivAge | BonusMalus | VehBrand | VehGas | Density | Region
-------+---------+----------+------+----------+--------+---------+------------+----------+---------+---------+--------
1 | 1 | 0.1 | D | 5 | 0 | 55 | 50 | B12 | Regular | 1217 | R82
3 | 1 | 0.77 | D | 5 | 0 | 55 | 50 | B12 | Regular | 1217 | R82
5 | 1 | 0.75 | B | 6 | 2 | 52 | 50 | B12 | Diesel | 54 | R22
10 | 1 | 0.09 | B | 7 | 0 | 46 | 50 | B12 | Diesel | 76 | R72
11 | 1 | 0.84 | B | 7 | 0 | 46 | 50 | B12 | Diesel | 76 | R72
(5 rows)
数据集共有 12 个属性。IDpol 为保单 ID,ClaimNb 为该保单的理赔次数。
6 个数值属性¶
| 属性 | 含义 |
|---|---|
| Exposure | 保单期(年),即风险暴露时长 |
| VehPower | 车辆马力等级 |
| VehAge | 车龄(年) |
| DrivAge | 驾驶员年龄(最常见驾驶员) |
| BonusMalus | 保费奖惩系数(50-230,<100 为奖励,>100 为惩罚) |
| Density | 驾驶员所在城市的人口密度(人/km²) |
4 个分类属性¶
| 属性 | 含义 |
|---|---|
| Area | 基于人口和密度的区域代码 |
| VehBrand | 车辆品牌 |
| VehGas | 燃油类型(Diesel / Regular) |
| Region | 法国大区 |
数据预处理¶
加载数据后,需要进行多项预处理以添加辅助列和新学习特征。
1. 添加交叉验证 Fold 列¶
由于需进行交叉验证,先添加 Fold 列,用于存储均匀分布的随机折 ID:
2. 创建预处理视图¶
创建包含以下预处理步骤的视图:
- Frequency:
ClaimNb / Exposure,即理赔频率,作为模型的目标(响应)变量。 - AreaNum:将分类属性
Area映射为数值。根据参考文献 [1] 的图表,边际频率与Area之间存在单调正相关,故创建数值变量以捕捉该关系。 - VehPowerCat:将数值属性
VehPower转换为分类属性。原始VehPower与边际频率的关系并非简单线性,分箱编码有助于线性模型(包括泊松回归等广义线性模型)捕捉非线性关系。 - VehAgeCat / DrivAgeCat:同理对车龄和驾驶员年龄进行分箱,分箱边界参考了文献 [1] 的专家建议,旨在实现:(1) 组内同质性;(2) 每组有足够的观测量(即暴露期总和)。
- LogDensity:对
Density取自然对数。对数线性尺度的数值属性更适合泊松回归学习。
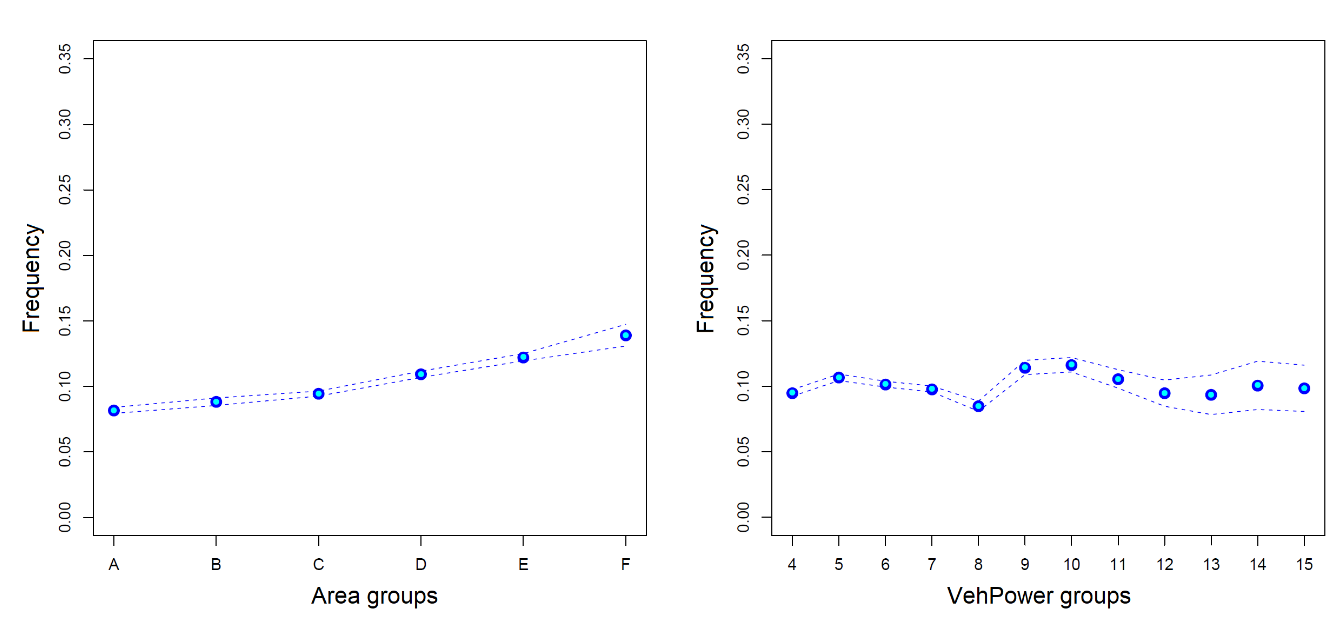
各特征的边际频率分布如下图所示:
CREATE VIEW claims_preproc AS SELECT IDpol,
(ClaimNb / Exposure) AS Frequency,
(CASE Area WHEN 'A' THEN 1 WHEN 'B' THEN 2 WHEN 'C' THEN 3 WHEN 'D' THEN 4 WHEN 'E' THEN 5 ELSE 6 END) AS AreaNum,
(CASE VehPower WHEN 4 THEN 'A' WHEN 5 THEN 'B' WHEN 6 THEN 'C' WHEN 7 THEN 'D' WHEN 8 THEN 'E' ELSE 'F' END) AS VehPowerCat,
(CASE WHEN VehAge < 1 THEN 'A' WHEN VehAge <= 10 THEN 'B' ELSE 'C' END) AS VehAgeCat,
(CASE WHEN DrivAge < 21 THEN 'A' WHEN DrivAge < 26 THEN 'B' WHEN DrivAge < 31 THEN 'C'
WHEN DrivAge < 41 THEN 'D' WHEN DrivAge < 51 THEN 'E' WHEN DrivAge < 71 THEN 'F' ELSE 'G' END) AS DrivAgeCat,
BonusMalus, VehBrand, VehGas, LN(Density) AS LogDensity, Region, Fold
FROM claims;
分类属性编码¶
泊松回归算法仅接受数值特征,因此需要对分类属性进行编码。使用 Vertica 提供的 One-Hot 编码功能:
SELECT ONE_HOT_ENCODER_FIT('claims_encoder', 'claims_preproc',
'VehPowerCat, VehAgeCat, DrivAgeCat, VehBrand, VehGas, Region'
USING PARAMETERS output_view='claims_encoded');
检查编码后的视图:
idpol | frequency | areanum | vehpowercat | VehPowerCat_1 | VehPowerCat_2 | VehPowerCat_3 | VehPowerCat_4 | VehPowerCat_5 | ...
-------+------------------+---------+-------------+---------------+---------------+---------------+---------------+---------------+------
1 | 10 | 4 | B | 1 | 0 | 0 | 0 | 0 |
3 | 1.2987012987013 | 4 | B | 1 | 0 | 0 | 0 | 0 |
5 | 1.33333333333333 | 2 | C | 0 | 1 | 0 | 0 | 0 |
10 | 11.1111111111111 | 2 | D | 0 | 0 | 1 | 0 | 0 |
11 | 1.19047619047619 | 2 | D | 0 | 0 | 1 | 0 | 0 |
(5 rows)
可见 One-Hot 编码为每个分类属性的每个不同取值创建了一个新属性,且在编码后的属性中只有一个值为 1。例如,第一条记录的 VehPowerCat 为 "B",对应编码后的 VehPowerCat_1 为 1。
数据拆分¶
因需进行交叉验证,按折 ID 拆分数据集。5 折 CV 中使用 4 折作为训练集,剩余 1 折作为测试集。将 Fold 值从 0 到 4 分别设置即可生成 5 次运行的对应数据集:
CREATE VIEW claims_encoded_train AS SELECT * FROM claims_encoded WHERE Fold != 0;
CREATE VIEW claims_encoded_test AS SELECT * FROM claims_encoded WHERE Fold = 0;
模型训练¶
训练泊松回归¶
\timing on
SELECT poisson_reg('m1', 'claims_encoded_train', 'Frequency', '*'
USING PARAMETERS
exclude_columns='IDpol, Frequency, VehPowerCat, VehAgeCat, DrivAgeCat, VehBrand, VehGas, Region, Fold',
optimizer='Newton', regularization='L2', lambda=1.0,
epsilon=1e-6, max_iterations=100, fit_intercept=true);
\timing off
训练命令中排除了 ID 列、频率列、折叠列以及 One-Hot 编码后已过时的原始分类列。
关键参数说明:
| 参数 | 说明 |
|---|---|
optimizer |
Vertica 泊松回归仅支持 Newton 优化器 |
regularization |
支持 None(默认)和 L2。正则化用于防止过拟合——当模型复杂度高于问题复杂度时,模型会错误地将响应波动与特征噪声关联起来 |
lambda |
正则化强度,值越大正则化越强 |
epsilon |
收敛判定阈值 |
max_iterations |
最大迭代次数 |
fit_intercept |
是否学习截距权重,通常启用可获得更优结果 |
查看模型摘要¶
输出结果包含学习到的系数及其显著性指标:
=======
details
=======
predictor |coefficient|std_err | z_value |p_value
--------------+-----------+--------+----------+--------
Intercept | -1.01086 | 0.03236|-31.23629 | 0.00000
areanum | 0.00348 | 0.00810| 0.42962 | 0.66747
vehpowercat_1 | 0.38195 | 0.00866| 44.10476 | 0.00000
vehpowercat_2 | 0.45103 | 0.00886| 50.90628 | 0.00000
vehpowercat_3 | 0.16870 | 0.00883| 19.09932 | 0.00000
...
==============
regularization
==============
type| lambda
----+--------
l2 | 1.00000
===========
call_string
===========
poisson_reg('public.m1', 'claims_encoded_train', '"frequency"', '*'
USING PARAMETERS exclude_columns='IDpol, Frequency, VehPowerCat, VehAgeCat, DrivAgeCat, VehBrand, VehGas, Region, Fold', optimizer='newton', epsilon=1e-06, max_iterations=100, regularization='l2', lambda=1, alpha=0.5, fit_intercept=true)
===============
Additional Info
===============
Name |Value
--------------------+------
iteration_count | 5
rejected_row_count | 0
accepted_row_count |542657
系数的显著性越高(p 值越小),说明该特征在预测响应变量时越重要。摘要还包含学习样本量和迭代次数等信息。
模型评估¶
使用 Poisson Deviance(泊松偏差)作为评估指标,其计算公式如下:
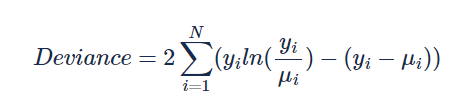
其中 yi 和 μi 分别表示第 i 条记录的观测频率和预测频率,N 为记录总数。
由于需要多次计算该指标,先创建用户自定义函数(UDF):
CREATE FUNCTION PoissonDeviance(obs FLOAT, pred FLOAT) RETURN FLOAT
AS BEGIN
RETURN (CASE obs WHEN 0 THEN 2 * pred
ELSE 2 * (obs * LN(obs/pred) + pred - obs) END);
END;
计算训练 Loss(样本内损失)¶
SELECT AVG(deviance) FROM (
SELECT PoissonDeviance(obs, pred) AS deviance FROM (
SELECT Frequency AS obs,
predict_poisson_reg(
AreaNum, VehPowerCat_1, VehPowerCat_2, VehPowerCat_3, VehPowerCat_4, ...
USING PARAMETERS model_name='m1') AS pred
FROM claims_encoded_train
) AS prediction_output
) AS deviance_output;
计算测试 Loss(样本外损失)¶
将上述查询中的数据集从 claims_encoded_train 替换为 claims_encoded_test 即可获得测试 Loss。
对 5 折交叉验证的 5 次运行重复上述过程后,得到平均结果:
| 指标 | 值 |
|---|---|
| 平均训练 Loss | 2.06757 |
| 平均测试 Loss | 2.08162 |
| 平均训练耗时 | 2099.6 ms |
训练 Loss 与测试 Loss 非常接近,表明模型未发生过拟合。
随机森林回归对比实验¶
为更全面地评估泊松回归的表现,使用 Vertica 的 Random Forest Regressor 进行对比实验。随机森林可以直接处理分类属性,因此直接在 claims_preproc 视图上拆分数据:
CREATE VIEW claims_train AS SELECT * FROM claims_preproc WHERE Fold != 0;
CREATE VIEW claims_test AS SELECT * FROM claims_preproc WHERE Fold = 0;
训练与评估¶
\timing on
SELECT rf_regressor('m3', 'claims_train', 'Frequency', '*'
USING PARAMETERS exclude_columns='IDpol, Frequency, Fold', max_depth=5, max_breadth=1000000000);
\timing off
SELECT AVG(deviance) FROM (
SELECT PoissonDeviance(obs, pred) AS deviance FROM (
SELECT Frequency AS obs,
predict_rf_regressor(AreaNum, VehPowerCat, VehAgeCat, DrivAgeCat, BonusMalus, VehBrand, VehGas, LogDensity, Region
USING PARAMETERS model_name='m3') AS pred
FROM claims_train
) AS prediction_output
) AS deviance_output;
SELECT AVG(deviance) FROM (
SELECT PoissonDeviance(obs, pred) AS deviance FROM (
SELECT Frequency AS obs,
predict_rf_regressor(AreaNum, VehPowerCat, VehAgeCat, DrivAgeCat, BonusMalus, VehBrand, VehGas, LogDensity, Region
USING PARAMETERS model_name='m3') AS pred
FROM claims_test
) AS prediction_output
) AS deviance_output;
不同树深度的结果对比¶
分别设置 max_depth 为 5、10、15(将 max_breadth 设为最大值以允许树生长到设定深度),结果如下:
| max_depth | 训练 Loss | 测试 Loss | 耗时(ms) |
|---|---|---|---|
| 5 | 1.99674 | 2.04856 | 5,897.8 |
| 10 | 1.72121 | 2.02377 | 15,469.4 |
| 15 | 1.48527 | 2.02227 | 53,348.2 |
可见随着 max_depth 增加,训练 Loss 持续下降,但训练 Loss 与测试 Loss 之间的差距也不断扩大,表明模型可能开始过拟合。根据 Min CV rule(选择交叉验证中测试 Loss 最低的模型),选择 max_depth = 15 作为最终的随机森林模型。
最终结果对比¶
| 模型 | 训练 Loss | 测试 Loss | 耗时(ms) |
|---|---|---|---|
| Poisson Regression | 2.06757 | 2.08162 | 2,099.6 |
| Random Forest (max_depth=15) | 1.48527 | 2.02227 | 53,348.2 |
随机森林的测试 Loss 降低了约 2.9%,但训练耗时是泊松回归的 25 倍以上。
总结¶
本文使用 Vertica 的数据库内机器学习函数,在 French Motor Claims 数据集上完成了从数据加载、预处理、编码到交叉验证训练和评估泊松回归模型的完整流程。实验结果表明:
- 泊松回归以约 1/25 的训练耗时,达到了与随机森林相当的预测精度(测试 Loss 仅高约 2.9%)。
- 泊松回归具有更强的可解释性——可直接通过系数解释各特征的影响方向与大小,在客户质询和政府调查等场景下能为定价决策提供更可解释的依据。
- 训练后的泊松回归模型可直接用于保单定价场景的理赔频率预测。
参考文献¶
[1] Noll, Alexander and Salzmann, Robert and Wuthrich, Mario V., Case Study: French Motor Third-Party Liability Claims (March 4, 2020). Available at SSRN: https://ssrn.com/abstract=3164764 or http://dx.doi.org/10.2139/ssrn.3164764
[2] Poisson regression and non-normal loss — scikit-learn 1.2.1 documentation