增强您的数据发现之旅:使用 DataHub Vertica 插件¶
DataHub 是一个元数据平台,支持端到端的数据血缘和数据发现。本YouTube视频演示了如何使用 DataHub Vertica 插件将 Vertica 数据有效集成到 DataHub 中,使您能够利用该平台的先进功能获得更深入的洞察。
DataHub 是现代数据栈的开源元数据平台。它是一个数据目录,旨在实现端到端的数据发现、数据可观测性和数据治理。这个可扩展的元数据平台专为开发者构建,帮助他们管理快速发展的数据生态系统的复杂性,同时让数据从业者能够充分利用其组织内数据的全部价值。
DataHub Vertica 插件¶
自 2022 年 12 月起,DataHub 支持从多种数据源摄取元数据,包括 PostgreSQL、Snowflake、Vertica 等数据库。测试版 Vertica DataHub 插件最初由 DataHub 社区贡献。该测试版插件仅支持表、视图和数据平台的元数据摄取。
目前 Vertica 插件使用 SQLAlchemy dialect 连接到 Vertica。
然而,该插件缺少重要的元数据信息,例如投影(Projections)、机器学习模型(MLModels)、EON 模式信息、OAuth 元数据以及表-视图-投影之间的血缘关系。我们开展了一个项目来编写一个能够提取这些信息的 Vertica 插件。这也要求重写 SQLAlchemy Vertica Dialect,因为 DataHub 使用 SQLAlchemy dialects 来连接数据库。
Vertica 的 DataHub 插件现在拥有经过认证的 DataHub 摄取插件,可用于将元数据摄取到 DataHub。这使得数据从业者能够在其 DataHub 实例中与其他元数据一起拥有 Vertica 元数据,从而充分利用 DataHub 端到端的数据发现和可观测性能力。他们可以获得关于 Vertica 对象(如表、视图和投影)使用情况的有意义洞察,并可视化血缘关系。
本文档提供了一个使用 Vertica 进行元数据摄取的示例,包括配置环境以及使用 DataHub Vertica 插件连接到 Vertica 的步骤。
测试环境¶
- DataHub 0.13.2.4
- RHEL 8.3
- Vertica Python driver 1.3.8
- Vertica Server 24.1
配置环境以将 DataHub 与 Vertica 结合使用¶
本节介绍如何安装 DataHub Vertica 插件并初始化项目。该配置基于 Linux (RHEL) 环境。
前提条件¶
要从 Vertica 摄取元数据,您需要:
- Vertica Server 版本 10.1.1-0 及以上(较低版本也可能可用)
- Vertica 凭据(用户名/密码)
- Docker for Linux
- Docker Compose
- Python 3.8 或更高版本
安装 DataHub Vertica 插件¶
- 为您的平台安装 Docker 和 Docker Compose v2。
- 在 Linux 上,安装 Docker for Linux 和 Docker Compose。
- 从命令行或桌面应用程序启动 Docker 引擎。
- 安装 DataHub CLI。
- 确保您已安装并配置了 Python 3.8+(使用命令
python3 --version检查)。 - 在终端中运行以下命令:
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip install --upgrade acryl-datahub
datahub version
- 要在本地部署 DataHub 实例,请在终端中运行以下 CLI 命令:
- 要安装 Vertica 插件,请在命令行中运行以下命令:
注意:此命令将自动安装 Vertica-python 客户端驱动和 Vertica-SQLAlchemy dialect。您无需手动安装它们。
有关更多详细信息,请参阅 DataHub Quickstart Guide。
基于 GUI 的摄取¶
通过 GUI 运行摄取的步骤:
- 访问
localhost:9002。 - 输入您的凭据登录。
- 在右上角,点击 Ingestion。在 Sources 中,点击 Create new source,然后选择 Vertica。
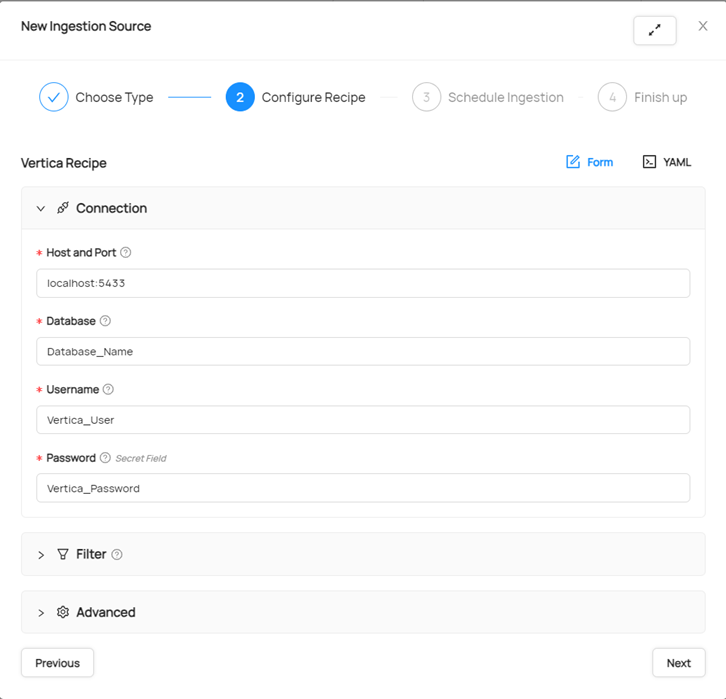
- 使用您的 Vertica 数据库凭据填写表单。
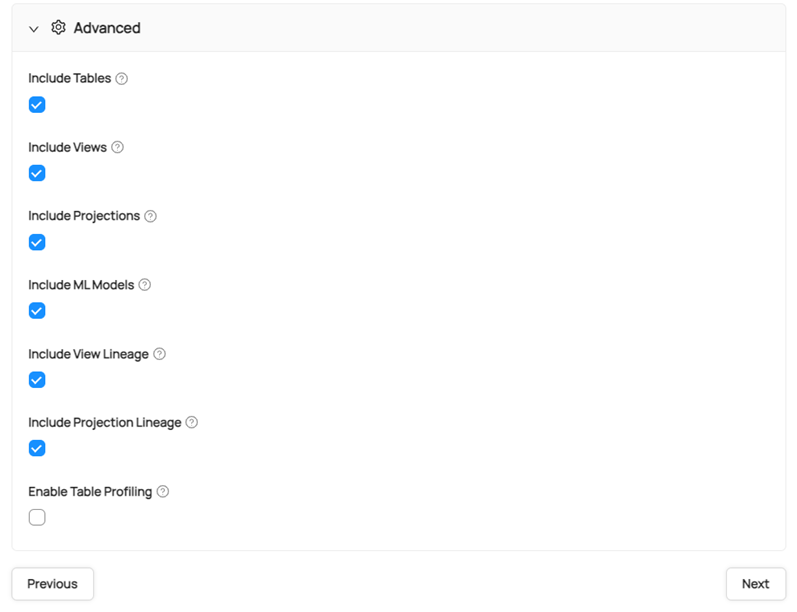
- 点击 Advance 以配置您的元数据对象。选择您想要摄取到 DataHub GUI 的对象。
- 点击 Next,配置摄取调度,然后再次点击 Next。
- 输入摄取名称,然后点击 Advance。
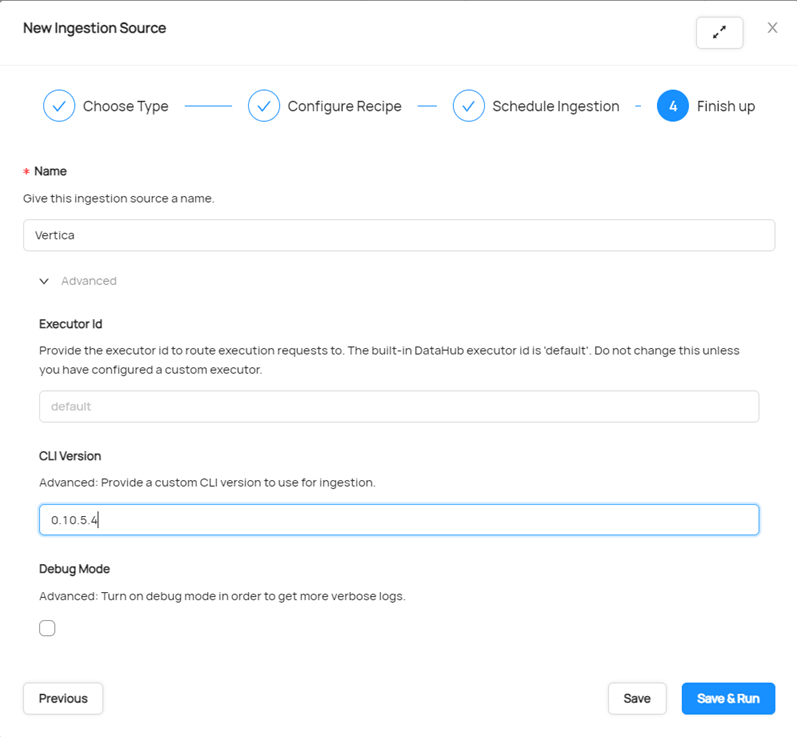
- 检查运行摄取时使用的 CLI 版本。确保您输入的 CLI 版本为 0.10.5.4V 或更高版本,以便在摄取 Vertica 元数据时获得性能改进。
- 点击 Save & Run 开始摄取。
- 如果摄取成功,您将看到以下内容:

基于 CLI 的摄取¶
对于基于 CLI 的摄取,请转到您机器上的 DataHub 目录。创建 recipe.yml 文件并在其中添加 Vertica 源详情。
请查看以下 recipe 以开始摄取!有关所有配置选项,请参阅 Integration Details。
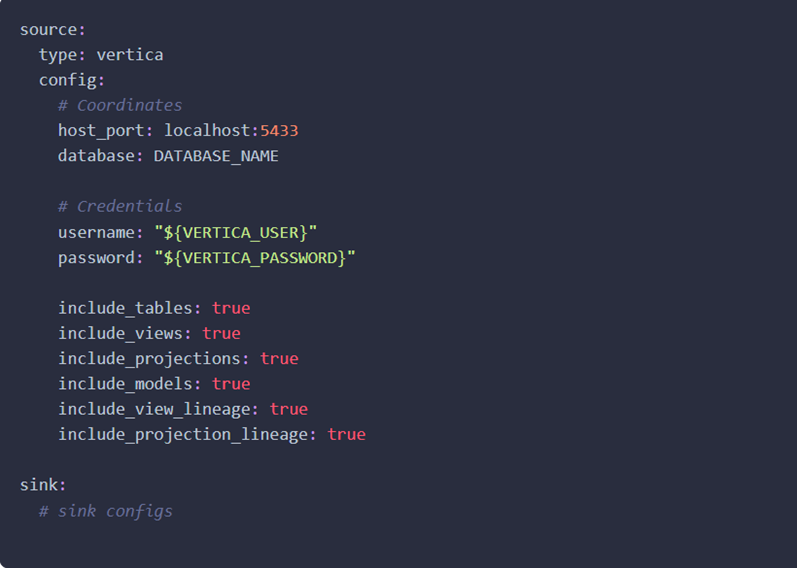
注意:默认情况下,您可以根据偏好更改所有设置为
true的配置属性。您可以根据需要添加 profiling 和其他配置选项。
在 DataHub 目录中添加 recipe.yml 文件后,运行以下命令开始摄取:
当摄取开始运行时,日志如下所示:
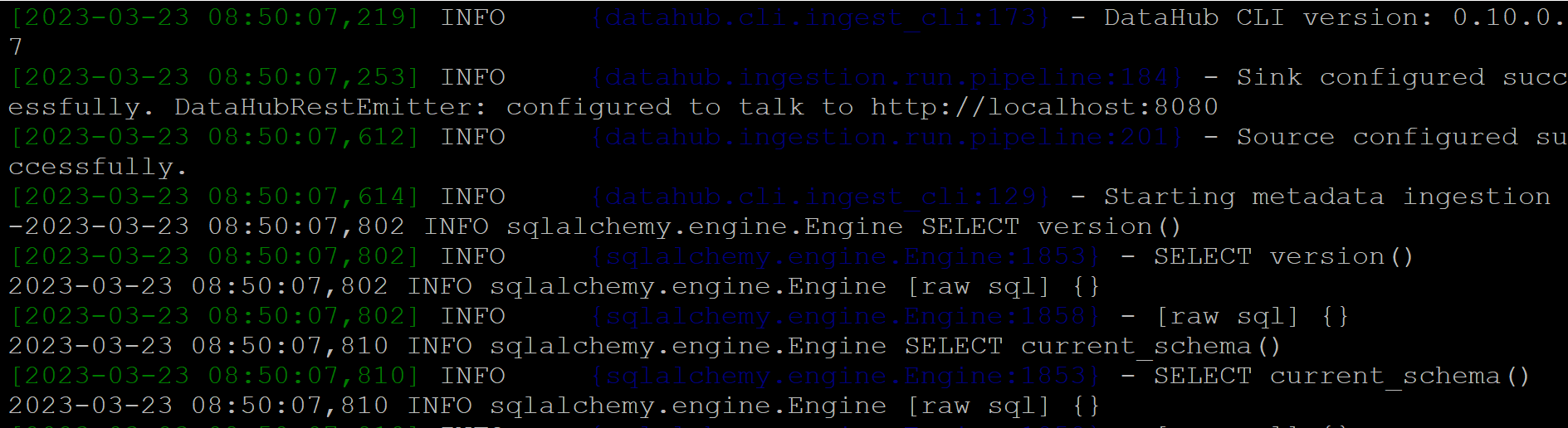
现在您可以进入 DataHub UI 并检查元数据。您将在平台部分看到 Vertica,并显示已摄取的对象数量:

点击 Vertica 徽标,它将带您进入 schema 列表。您可以选择任意 schema,然后选择表、视图、投影来查看元数据。
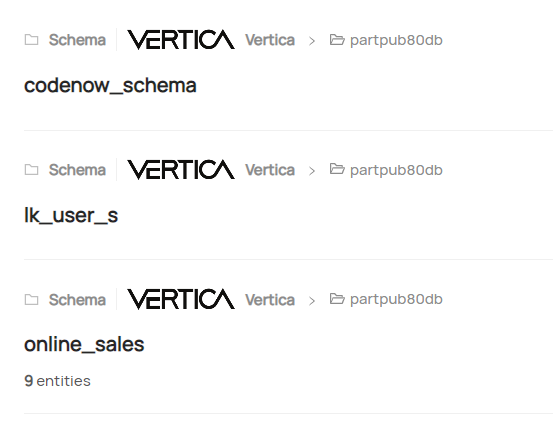
新的 DataHub Vertica 插件功能——支持 Vertica 元数据¶
-
基于 UI 的数据摄取。 您现在可以使用 UI recipe 表单轻松摄取数据。这意味着无需 CLI,将数据导入 DataHub 对于经验丰富和新手用户都变得同样简单。
-
支持查看表、投影和视图的元数据。 您可以可视化 Vertica 表及其关联的投影。
-
一站式获取元数据信息,例如行数、投影数、分区数、列数、表大小、列大小、数据类型、每列的 min/max 统计信息。
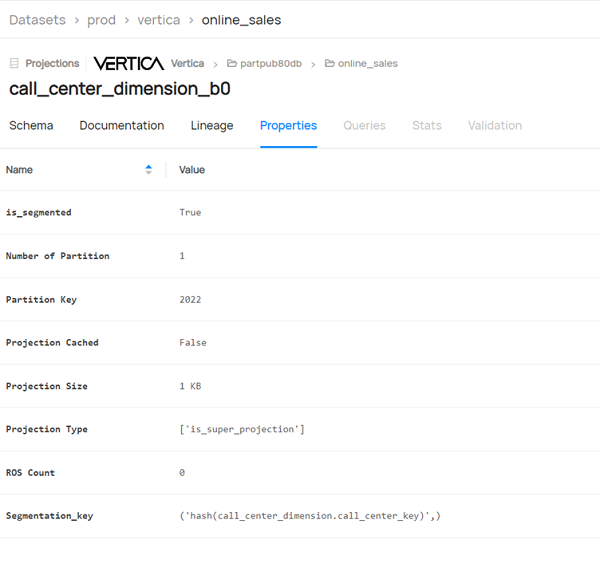
-
对于投影,您还可以检测列列表、投影类型、固定投影、ROS 计数等信息。
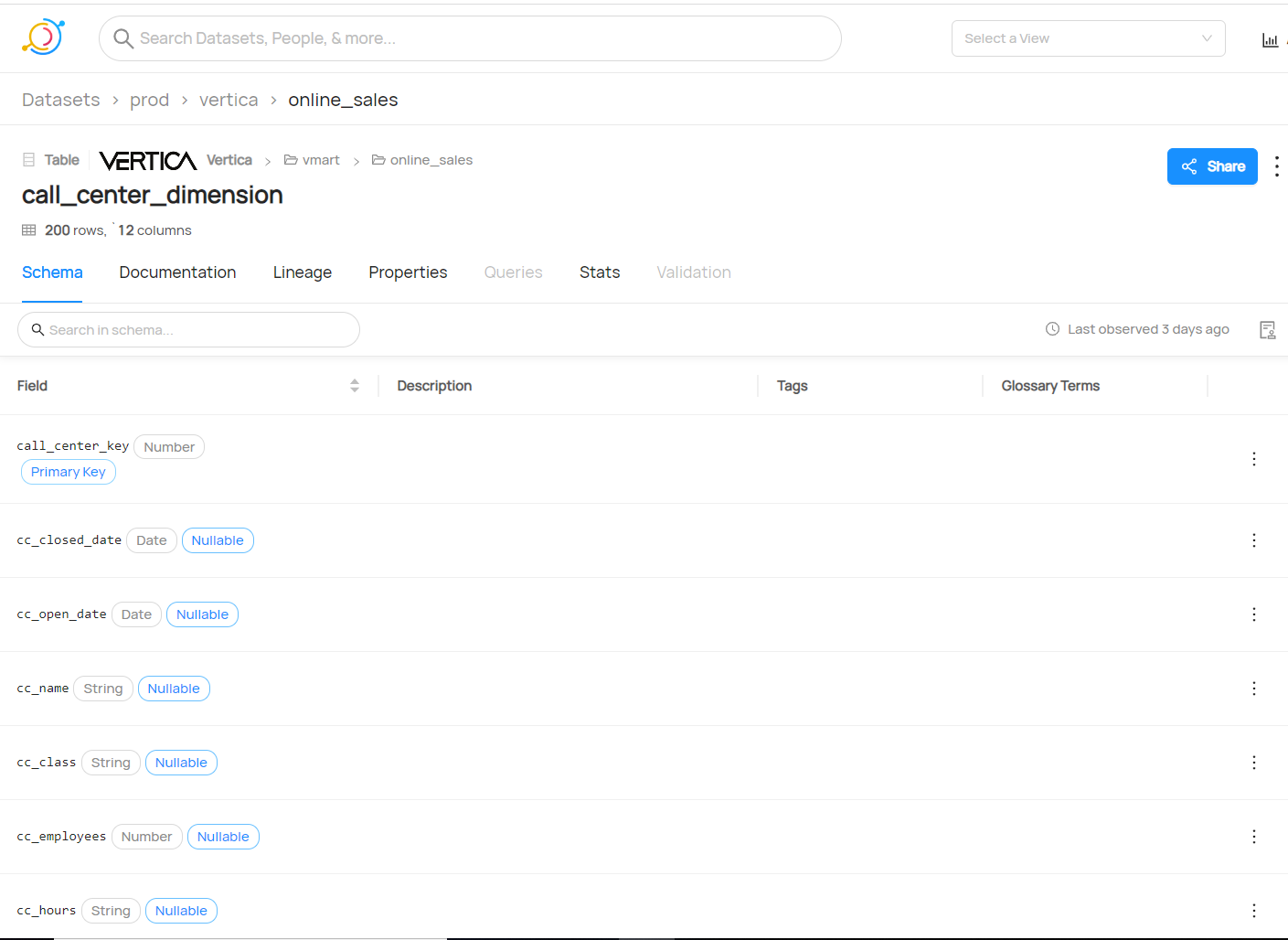
注意:列的默认值(如有)将显示在 Description 中。
- 支持查看表、投影和视图的血缘关系。 您可以可视化 Vertica 对象的"下游"和"上游"血缘关系。例如,一个表可以有 2 个基于该表创建的投影,这些可以在 DataHub 中作为下游血缘关系查看。
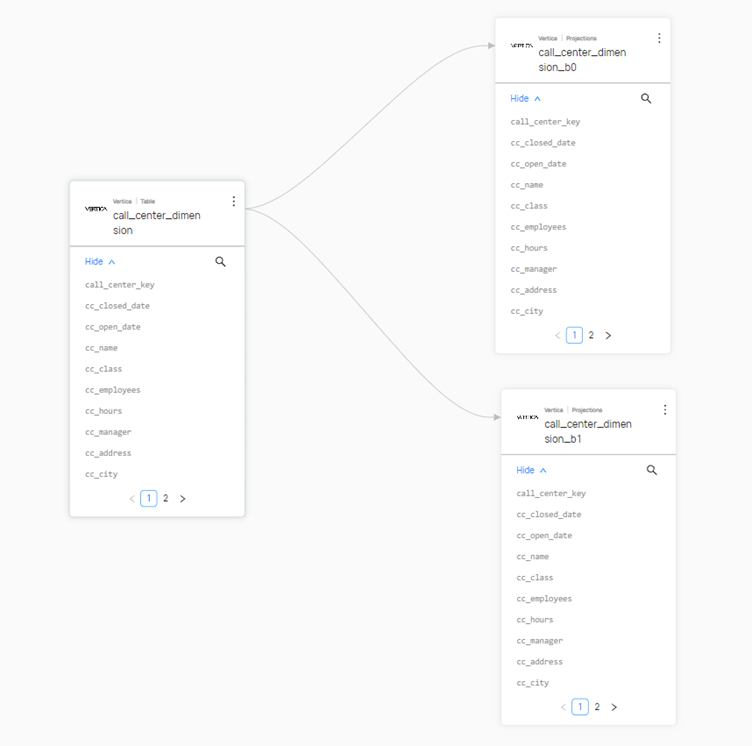
注意:如果表、投影或视图为空,则不显示血缘关系。
- 视图可以有多个上游表,这些也可以被可视化。
- 这对于确定删除或修改 Vertica 表/视图/投影对其依赖项的影响尤为有用。
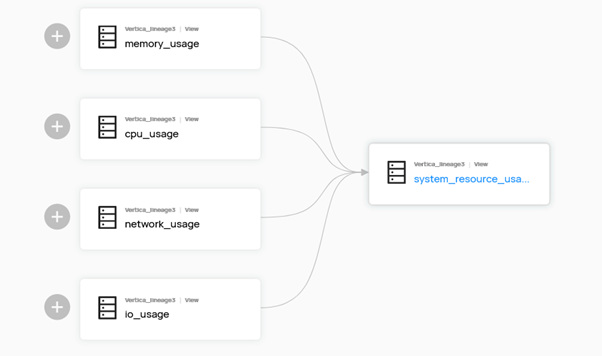
- 支持 UDX 元数据。 您可以查看所有 schema 级别的 UDX(已授权的)及其对应的语言。

-
支持 EON 模式元数据。 您可以确定数据是从哪种数据库模式(Enterprise/EON)摄取的,以及公共存储路径和子集群大小。
-
支持机器学习模型(ML Models)。 您可以在 schema 级别查看 Vertica 数据库中创建的任何 ML 模型的摘要。模型运行的相应结果以及使用它的用户也会一并显示。
-
支持已删除实体。 在摄取期间,启用
stateful_ingestion将使您能够确定相对于上次摄取已删除的任何对象。 -
已摄取数据的所有者。 Vertica 插件使用"owners"(所有者)扩展了 DataHub 的数据联邦支持。每个已摄取的数据只能由 DataHub 中授权的人员查看。
-
改进的 SQLAlchemy Dialect。 将元数据提取到 DataHub 的相关逻辑需要物化到 SQLAlchemy-vertica dialect 中。此前该功能由未知的第三方开发。因此,作为此次开发的副产品,我们现在拥有一个全新的、改进的 Vertica-dialect for SQLAlchemy,它支持比之前开源版本更多的新特性。将逻辑添加到我们的 dialect 而不是 DataHub 中的另一个好处是,任何其他产品现在都可以使用新的 dialect 来访问 Vertica。
视图的列级血缘支持¶
Vertica 现在支持视图的列级血缘(Column Level Lineage, CLL)。请按照以下步骤在 Vertica 中获取视图的列级血缘:
- DataHub 生产环境就绪后,在以下位置查找 Python 安装目录,并在该位置新建一个
vertica.py文件:
- 在新文件中添加以下代码并保存:
from sqlglot import exp, generator, tokens
from sqlglot.dialects.dialect import Dialect
from sqlglot.tokens import Tokenizer, TokenType
class Vertica(Dialect):
class Tokenizer(tokens.Tokenizer):
QUOTES = ["'", '"']
IDENTIFIERS = ["`"]
KEYWORDS = {
**Tokenizer.KEYWORDS,
}
class Generator(generator.Generator):
TYPE_MAPPING = {
**generator.Generator.TYPE_MAPPING,
exp.DataType.Type.INTERVAL: "BIGINT",
}
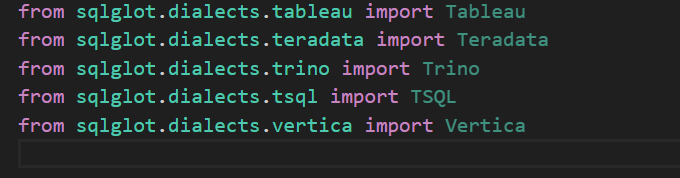
- 修改同一目录下的
__init__.py,在文件末尾添加以下代码:
详情请参见下图:
- 修改同一目录下的
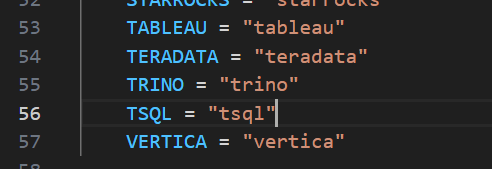
dialect.py,在Dialects类中添加以下代码:
详情请参见下图:
- 按照以下说明修改
{python_location}/site-packages/datahub/ingestion/source/sql/vertica.py文件中的代码:
注释掉 loop_views 和 get_upstream_lineage_info 函数,因为它们会覆盖视图血缘的列级血缘(CLL)特性,然后保存文件。
现在您可以运行 CLI 摄取来查看 Vertica 中视图的列级血缘关系。以下是使用 Vertica 作为数据源的视图 CLL 示例说明。
注意:完成这些修改后,您只能通过 CLI 运行摄取。
Vertica 驱动附加参数¶
DataHub 使用 Vertica Python 驱动进行连接。有关连接选项的更多详细信息,请参阅 vertica-python 驱动 readme。您需要将这些参数传递到您正在使用的 recipe 文件中。以下是一个示例 recipe 文件:
source:
type: vertica
config:
host_port: 'localhost:5433'
database: db_name
username: {"username"}
password: {"password"}
include_tables: true
include_views: true
include_projections: true
include_models: true
include_view_lineage: true
include_view_column_lineage: true
profiling:
enabled: false
stateful_ingestion:
enabled: false
options:
connect_args:
connection_load_balance: true
oauth_access_token: token_value
sink:
type: datahub-rest
config:
server: 'http://localhost:8080'
请确保缩进正确。我们仅在 recipe 文件中添加了部分参数,但所有其他 Vertica-Python 连接属性也同样适用。
已知限制¶
- 在统计信息中,主键(primary keys)不显示最大值和最小值。
- 对于 integer、boolean 和 date 类型的列,不显示列长度,因为在 Vertica 数据库中这些列的长度是固定的。