Vertica K-Prototypes 聚类算法实战¶
原文:K-Prototypes Clustering Using Vertica's In-Built Machine Learning Functions 适用版本:Vertica 12.0.3+ 数据集:Kaggle Customer Personality Analysis(2,240 条记录) 说明:中文注释 + 完整实验过程 + 全部 SQL 原文
概述¶
K-prototypes 是 K-means + K-modes 的混合聚类算法。K-means 仅处理数值型数据,K-modes 仅处理分类型数据,而 K-prototypes 原生支持混合数据,无需对分类变量做额外编码。该功能从 Vertica 12.0.3 开始提供。
典型应用场景:
- 垃圾邮件检测
- 客户行为分析(客户分群)
- 保险理赔高成本群体识别
数据集¶
使用 Kaggle 的 Customer Personality Analysis 数据集,共 2,240 行记录,包含客户的出生年份、教育程度、婚姻状况、收入、各类商品购买量、促销活动响应等字段。
建表 DDL¶
CREATE TABLE customer_data_campaign (
ID INT, Year_Birth INT, Education VARCHAR, Marital_Status VARCHAR,
Income INT, Kids INT, Teens INT, Dt_Customer DATE, Recency INT,
Wine INT, Fruits INT, Meat INT, Fish INT, Sweets INT, Gold INT,
Deals INT, Web INT, Catalog INT, Store INT, WebVisits INT,
Cmp INT, Cmp4 INT, Cmp5 INT, Cmp1 INT, Cmp2 INT,
Complain INT, Z_CostContact INT, Z_Revenue INT, Response INT
);
数据加载¶
COPY customer_data_campaign FROM LOCAL 'path-to-data' WITH DELIMITER ',';
Rows Loaded
-------------
2240
(1 row)
加载后数据预览¶
ID | Year_Birth | Education | Marital_Status | Income | Kids | Teens | Dt_Customer | Recency | Wine | Fruits | Meat | Fish | Sweets | Gold | Deals | Web | Catalog | Store | WebVisits | Cmp | Cmp4 | Cmp5 | Cmp1 | Cmp2 | Complain | Z_CostContact | Z_Revenue | Response
----+------------+------------+----------------+--------+------+-------+-------------+---------+------+--------+------+------+--------+------+-------+-----+---------+-------+-----------+-----+------+------+------+------+----------+---------------+-----------+----------
0 | 1985 | Graduation | Married | 70951 | 0 | 0 | 2013-05-04 | 66 | 239 | 10 | 554 | 254 | 87 | 54 | 1 | 3 | 4 | 9 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0
1 | 1961 | Graduation | Single | 57091 | 0 | 0 | 2014-06-15 | 0 | 464 | 5 | 64 | 7 | 0 | 37 | 1 | 7 | 3 | 7 | 5 | 0 | 0 | 0 | 0 | 1 | 0 | 3 | 11 | 1
9 | 1975 | Master | Single | 46098 | 1 | 1 | 2012-08-18 | 86 | 57 | 0 | 27 | 0 | 0 | 36 | 4 | 3 | 2 | 2 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0
13 | 1947 | PhD | Widow | 25358 | 0 | 1 | 2013-07-22 | 57 | 19 | 0 | 5 | 0 | 0 | 8 | 2 | 1 | 0 | 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0
17 | 1971 | PhD | Married | 60491 | 0 | 1 | 2013-09-06 | 81 | 637 | 47 | 237 | 12 | 19 | 76 | 4 | 6 | 11 | 7 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0
数据字段说明:Year_Birth(出生年份)、Education(教育程度)、Marital_Status(婚姻状况)、Income(收入)、Dt_Customer(注册日期)、Recency(最近购买天数)、Wine/Fruits/Meat/Fish/Sweets/Gold(各品类购买量)、Deals(折扣购买量)、Web/Catalog/Store(各渠道购买次数)、WebVisits(月访问量)、Cmp/Cmp4/Cmp5/Cmp1/Cmp2(历次活动响应)、Response(最终活动响应)。
数据预处理¶
1. 检查 NULL 值¶
SELECT SUMMARIZE_NUMCOL(* USING PARAMETERS exclude_columns='ID,Education,Marital_Status,Dt_Customer') OVER() FROM customer_data_campaign;
输出(列摘要,25行):Income 列 COUNT 为 2216(而非 2240),说明存在空值。
输出显示教育分布:Graduation 1127、PhD 486、Master 370、2n Cycle 203、Basic 54。
输出显示婚姻状况分布:Married 864、Together 580、Single 480、Divorced 232、Widow 77、Alone 3、Absurd 2、YOLO 2。
2. 删除 Income 为 NULL 的行¶
3. 排除无用列¶
Z_CostContact 和 Z_Revenue 只有唯一值,训练时排除。
4. 创建年龄段(AgeRange)分类特征¶
CREATE VIEW customer_data_view AS
SELECT *,
(CASE WHEN (YEAR(NOW()) - Year_Birth) < 30 THEN '18-29'
WHEN (YEAR(NOW()) - Year_Birth) < 50 THEN '30-49'
WHEN (YEAR(NOW()) - Year_Birth) < 70 THEN '50-69'
ELSE '> 60' END) AS AgeRange
FROM customer_data_campaign;
5. Min-Max 归一化¶
各变量量纲差异大(收入差异以千计,二值变量仅 0/1),必须归一化:
SELECT NORMALIZE_FIT('norm_fit_model', 'customer_data_view', '*', 'minmax'
USING PARAMETERS exclude_columns='ID, Dt_Customer, Year_Birth, Education, Marital_Status, AgeRange',
output_view='customer_campaign_norm');
NORMALIZE_FIT
---------------
Success
肘部法选择最优 K¶
训练 K=2 到 K=8 共 8 个模型,保持其他超参数不变。
通用训练模板:
SELECT kprototypes('model_k_x', 'customer_campaign_norm', '*' , x
USING PARAMETERS max_iterations=100, key_columns='ID',
exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue');
SELECT get_model_summary(USING PARAMETERS model_name='model_k_x');
K=2 训练¶
SELECT kprototypes('model_k_2', 'customer_campaign_norm', '*' , 2
USING PARAMETERS max_iterations=100, key_columns='ID',
exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue',
output_view='clustered_k_2');
kprototypes
---------------------------
Finished in 13 iterations
K=2 模型摘要¶
输出如下:
=======
centers
=======
education |marital_status| income | kids | teens |recency | wine | fruits | meat | fish | sweets | gold | deals | web |catalog | store |webvisits| cmp | cmp4 | cmp5 | cmp1 | cmp2 |complain|response|agerange
----------+--------------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+--------+---------+--------+--------+--------+--------+--------+--------+--------+--------
Graduation| Married | 0.07312| 0.22576| 0.32873| 0.49272| 0.18975| 0.11210| 0.07900| 0.11940| 0.08670| 0.12513| 0.17046| 0.15072| 0.08397| 0.43312| 0.27760 | 0.05308| 0.07502| 0.04034| 0.04459| 0.01062| 0.00849| 0.11111| 50-69
Graduation| Together | 0.08100| 0.21233| 0.11893| 0.49923| 0.23004| 0.16824| 0.12815| 0.19093| 0.13214| 0.15779| 0.12752| 0.15235| 0.11550| 0.46930| 0.24545 | 0.10959| 0.07223| 0.13076| 0.09838| 0.01868| 0.01121| 0.21918| 30-49
=======
metrics
=======
Evaluation metrics:
Total Sum of Squares: 5707.2147
Within-Cluster Sum of Squares:
Cluster 0: 2929.7496
Cluster 1: 1953.8979
Total Within-Cluster Sum of Squares: 4883.6475
Between-Cluster Sum of Squares: 823.56717
Between-Cluster SS / Total SS: 14.43%
Number of iterations performed: 13
Converged: True
Call:
kprototypes('public.model_k_2', 'customer_campaign_norm', '*', 2
USING PARAMETERS exclude_columns='ID, Dt_Customer, Year_Birth, Z_CostContact, Z_Revenue',
max_iterations=100, epsilon=0.0001, gamma=1, init_method='random',
distance_method='euclidean', output_view='clustered_k_2', key_columns='ID')
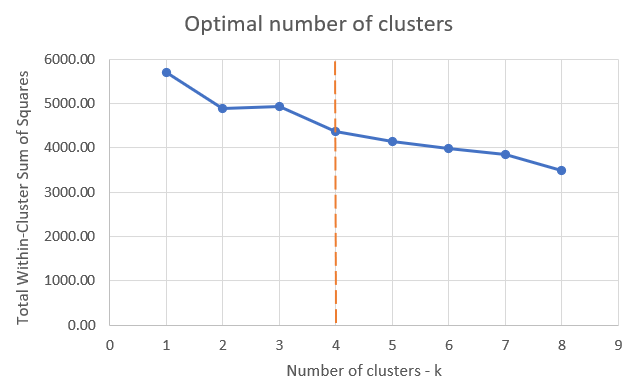
上图展示各 K 值的 Total Within-Cluster Sum of Squares。虽然曲线无明显"肘点",但可见 K>4 后模型改进不显著。
K=4 训练与聚类中心¶
SELECT get_model_attribute(USING PARAMETERS model_name='model_k_4', attr_name='centers') ORDER BY income;
输出(归一化值):
education | marital_status | income | kids | teens | recency | wine | fruits | meat | fish | sweets | gold | deals | web | catalog | store | webvisits | cmp | cmp4 | cmp5 | cmp1 | cmp2 | complain | response | agerange
------------+----------------+--------------------+--------------------+--------------------+-------------------+-------------------+--------------------+--------------------+-------------------+--------------------+-------------------+--------------------+-------------------+--------------------+-------------------+-------------------+--------------------+--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+----------
Graduation | Married | 0.0617337131689543 | 0.32492795389049 | 0.147694524495677 | 0.504948621663319 | 0.100241086646425 | 0.0957670195357189 | 0.0580929708056635 | 0.101782515327184 | 0.0713311481180016 | 0.10213489904567 | 0.148030739673391 | 0.118369089550646 | 0.0584088102099629 | 0.364331633784083 | 0.296685878962536 | 0.0734870317002882 | 0.0144092219020173 | 0.00288184438040346 | 0.00144092219020173 | 0.00144092219020173 | 0.0144092219020173 | 0.0749279538904899 | 30-49
Graduation | Married | 0.0750482928810095 | 0.217258883248731 | 0.352791878172589 | 0.486181613085166 | 0.189783116472472 | 0.1241129505395 | 0.0823935849334216 | 0.127515042235854 | 0.0962762041306622 | 0.132653351677025 | 0.17414551607445 | 0.154427523970671 | 0.0892313270485859 | 0.439437719640765 | 0.273045685279188 | 0.065989847715736 | 0.0629441624365482 | 0.0233502538071066 | 0.0314720812182741 | 0.00812182741116751 | 0.00710659898477157 | 0.114720812182741 | 50-69
Master | Together | 0.0859822442467238 | 0.122252747252747 | 0.274725274725275 | 0.531551781551782 | 0.280677962359141 | 0.14390634491137 | 0.123873228221054 | 0.191193941193941 | 0.116265413975338 | 0.162738351990688 | 0.153663003663004 | 0.178876678876679 | 0.125686813186813 | 0.540786136939983 | 0.234752747252747 | 0.0412087912087912 | 0.0851648351648352 | 0.043956043956044 | 0.0302197802197802 | 0.00549450549450549 | 0.00824175824175824 | 0.104395604395604 | > 60
Graduation | Married | 0.117301123543308 | 0.0317919075144509 | 0.0578034682080925 | 0.429380510305366 | 0.544305022668406 | 0.302872745229035 | 0.277255591857251 | 0.324815319034972 | 0.242509817764638 | 0.24698827724056 | 0.0755298651252408 | 0.207664311710554 | 0.215111478117258 | 0.614495331258337 | 0.167919075144509 | 0.184971098265896 | 0.352601156069364 | 0.699421965317919 | 0.572254335260116 | 0.109826589595376 | 0.00578034682080925 | 0.751445086705202 | 30-49
去归一化:还原真实值¶
CREATE TABLE centers AS
SELECT get_model_attribute(USING PARAMETERS model_name='model_k_4', attr_name='centers');
SELECT REVERSE_NORMALIZE(* USING PARAMETERS model_name='norm_fit_model')
FROM centers ORDER BY income;
输出去归一化后的真实聚类中心:
education | marital_status | income | kids | teens | recency | wine | fruits | meat | fish | sweets | gold | deals | web | catalog | store | webvisits | cmp | cmp4 | cmp5 | cmp1 | cmp2 | complain | response | agerange
------------+----------------+------------------+--------------------+-------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+------------------+--------------------+--------------------+---------------------+---------------------+---------------------+---------------------+--------------------+----------
Graduation | Married | 42778.97 | 0.65 | 0.30 | 49.99 | 149.66 | 19.06 | 100.21 | 26.36 | 18.69 | 32.79 | 2.22 | 3.20 | 1.64 | 4.74 | 5.93 | 0.0735 | 0.0144 | 0.00288 | 0.00144 | 0.00144 | 0.0144 | 0.0749 | 30-49
Graduation | Married | 51632.31 | 0.43 | 0.71 | 48.13 | 283.35 | 24.70 | 142.13 | 33.03 | 25.22 | 42.58 | 2.61 | 4.17 | 2.50 | 5.71 | 5.46 | 0.0660 | 0.0629 | 0.02335 | 0.03147 | 0.00812 | 0.00711 | 0.1147 | 50-69
Master | Together | 58902.69 | 0.24 | 0.55 | 52.62 | 419.05 | 28.64 | 213.68 | 49.52 | 30.46 | 52.24 | 2.30 | 4.83 | 3.52 | 7.03 | 4.70 | 0.0412 | 0.0852 | 0.04396 | 0.03022 | 0.00549 | 0.00824 | 0.1044 | > 60
Graduation | Married | 79727.74 | 0.06 | 0.12 | 42.51 | 812.65 | 60.27 | 478.27 | 84.13 | 63.54 | 79.28 | 1.13 | 5.61 | 6.02 | 7.99 | 3.36 | 0.1850 | 0.3526 | 0.69942 | 0.57225 | 0.10983 | 0.00578 | 0.7514 | 30-49
K=4 聚类解读与营销建议¶
| 聚类 | 收入 | 特征画像 | 营销建议 |
|---|---|---|---|
| 1 | 42,779 | 年轻已婚低收、有小孩、购买最少、但频繁访问网站 | 以网站为主要营销渠道推送活动 |
| 2 | 51,632 | 对营销活动响应度低,但关注打折(Deals 较高) | 推送针对性折扣信息 |
| 3 | 58,903 | 硕士学历(Master)、伴侣关系(Together)、店内线下购买为主、不响应营销活动 | 以店内活动为主,适当推送新品 |
| 4 | 79,728 | 高收入高消费群体,响应所有活动(cmp/response 极高)、不依赖打折 | 推送高端产品/新品,利用全渠道 |
总结¶
K-means 是最流行的机器学习算法之一,但限于纯数值数据。K-prototypes 突破了这一限制,支持同时包含数值和分类特征的混合数据集,无需对分类特征进行独热编码等预处理。
在本文中,我们完成了:
- 数据加载与探索性分析
- NULL 值清理与特征工程(创建 AgeRange)
- Min-Max 归一化(NORMALIZE_FIT)
- 肘部法确定最优 K 值(K=4)
- 模型训练与摘要查看(get_model_summary)
- 去归一化还原真实聚类中心(REVERSE_NORMALIZE)
- 聚类解读与营销策略建议
典型应用场景:网约车行程分群、网站用户行为聚类、交通事故伤害分析等。