Vertica 集成 Delta Lake¶
关于本文档¶
本文档探索了使用外部表集成 Vertica 和 Delta Lake 的方案。Delta Lake 是 Apache Spark 中的一项服务,为数据湖提供 ACID 事务。本文档详细介绍了通过 Delta Lake 和 S3 将数据写入 Vertica 所需的步骤。为测试目的,我们使用 Minio 作为 S3 存储桶。
Delta Lake 概述¶
Delta Lake 是一个开源存储层,为数据湖带来可靠性。Delta Lake 提供 ACID 事务、可扩展的元数据处理,并统一了流处理和批处理数据处理。Delta Lake 在您现有的数据湖上运行,并与 Apache Spark API 完全兼容。
先决条件¶
- Apache Spark 环境。我们测试使用了 4 节点集群(1 个 Master 和 3 个 Worker)。请按照 Set up Apache Spark on a Multi-Node Cluster 的说明安装多节点 Spark 环境。启动 Spark 多节点集群。
- Vertica Analytical Database。我们使用 Vertica 10.0 进行测试。
- AWS S3 或兼容 S3 的对象存储。我们使用 MinIO 作为 S3 存储桶进行测试。
- 必需的 Jar 文件。您可以将这些 jar 复制到 Spark 机器上的任何所需位置。我们将这些 jar 文件放置在
/home/spark: - Vertica:
vertica-spark2.1_scala2.11.jar - Hadoop:
hadoop-aws-2.6.5.jar -
AWS:
aws-java-sdk-1.7.4.jar -
在 Vertica 数据库中运行以下命令以设置访问 S3 存储桶的参数:
SELECT SET_CONFIG_PARAMETER('AWSAuth', 'accesskey:secretkey'); SELECT SET_CONFIG_PARAMETER('AWSRegion','us-east-1'); SELECT SET_CONFIG_PARAMETER('AWSEndpoint','<S3_IP>:9000'); SELECT SET_CONFIG_PARAMETER('AWSEnableHttps','0');注意:您的端点值可能因您为 S3 存储桶位置选择的 S3 对象存储而异。
Vertica 和 Delta Lake 集成¶
要集成 Vertica 与 Delta Lake,首先需要将 Apache Spark 与 Delta Lake 集成,配置 jar 文件和访问 AWS S3 的连接。然后,将 Vertica 连接到 Delta Lake。之后,在 S3 存储桶上执行 Insert、Append、Update 或 Delete 等操作。
在 Apache Spark 上配置 Delta Lake 和 AWS S3¶
在 Apache Spark 机器上运行以下命令。这将下载 Delta Lake 包,配置 jar 文件和 AWS S3:
./bin/spark-shell \
--packages io.delta:delta-core_2.11:0.6.1 \
--jars /<JAR_LOC>/vertica-spark2.1_scala2.11.jar,/<JAR_LOC>/vertica-jdbc.jar,/<JAR_LOC>/hadoop-aws-2.6.5.jar,/<JAR_LOC>/aws-java-sdk-1.7.4.jar \
--conf spark.hadoop.fs.s3a.path.style.access=true \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore \
--conf spark.hadoop.fs.s3a.endpoint=http://<S3_IP>:9000 \
--conf spark.hadoop.fs.s3a.access.key=accesskey \
--conf spark.hadoop.fs.s3a.secret.key=secretkey
准备数据¶
在 Apache Spark 中使用 Scala 创建示例数据:
val df = Seq(
(1,"notebook","2019-01-01 00:00:00"),
(2,"laptop", "2019-01-10 13:00:00"),
(3,"small_phone", "2019-01-15 12:00:00"),
(4,"big_phone", "2019-01-30 09:30:00"),
(5,"kitkat", "2019-04-25 07:30:00")
).toDF("id", "device", "purchase_time")
相应地更改数据类型。在此示例中,我们将其从 String 更改为 Timestamp,以充分利用 Delta Lake 的分区概念:
将数据写入 AWS S3 并验证¶
使用 Scala 运行以下命令,将数据从 Apache Spark 写入 AWS S3 上的 Delta 表:
df2.write.format("delta").mode("overwrite").partitionBy("purchase_time").save("s3a://delta-test/delta_test_table")
注意:分区命名 "purchase_time=" 是必需的,因为 Delta Lake 在表目录中创建其他文件夹。因此,全包通配符 () 不起作用,因为它会在读取时导致错误。因此,使用 "purchase_time=*"。
使用 Scala 运行以下命令,验证数据是否正确从 S3 存储桶读取:
配置 Vertica 和 Delta Lake 集成¶
开始与 Vertica 集成之前,需要在 AWS S3 中生成 Manifest 文件。Manifest 文件是一个文本文件,包含要读取的数据文件(Parquet 文件)列表。此目录中的文件包含要为 Delta 表快照读取的数据文件(Parquet 文件)的名称。
在 AWS S3 中生成 Manifest 文件:
在 Apache Spark 机器上使用 Scala 运行以下命令:
import io.delta.tables._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")
deltaTable.generate("symlink_format_manifest")
Manifest 文件生成在以下目录中:
在 Vertica 中创建外部表:
创建一个包含 AWS S3 上 Delta 表数据的外部表。我们创建了 delta_test_table_data 表:
注意:确保您要创建的表尚不存在。
CREATE EXTERNAL TABLE delta_test_table_data (
id INT,
device VARCHAR,
purchase_time TIMESTAMPTZ,
parquet_filename VARCHAR
)
AS COPY (id, device, purchase_time, parquet_filename AS current_load_source())
FROM 's3://delta-test/delta_test_table/purchase_time=*/*'
PARQUET(hive_partition_cols='purchase_time');
注意:
current_load_source()函数获取记录来源的文件名。这对于解析 Delta 表的 manifest 并查找所有必需的 parquet 文件是必需的。
运行以下命令验证外部表是否被读取:

在 Vertica 中定义另一个外部表,以访问对原始数据的最新更改:
DROP TABLE delta_test_table_manifest;
CREATE EXTERNAL TABLE delta_test_table_manifest (filename varchar)
AS COPY (col FILLER VARCHAR(700), filename AS substr(col,instr(col,'/',-1)+1))
FROM 's3://delta-test/delta_test_table/_symlink_format_manifest/*/*';
创建一个视图以获取最新数据(连接两个外部表):
CREATE OR REPLACE VIEW delta_test_table AS
SELECT id, device, purchase_time
FROM delta_test_table_data
WHERE parquet_filename IN (SELECT filename FROM delta_test_table_manifest);
注意:ETL 过程完成后,需要删除
_symlink_format_manifest目录并在 Apache Spark 机器上重新生成 manifest 文件:
如何让 Vertica 看到变更数据¶
以下各节包含我们执行的一些操作示例,用于在 Vertica 中查看变更数据。
追加数据¶
在此示例中,我们在 Apache Spark 机器上使用 Scala 运行以下命令并追加了一些数据:
val df = Seq(
(6,"notebook2","2019-01-01 00:00:00"),
(7,"laptop2", "2019-01-12 13:00:00"),
(8,"small_phone2", "2019-01-17 12:00:00"),
(9,"big_phone2", "2019-01-30 09:30:00"),
(10,"kitkat2", "2019-04-25 07:30:00")
).toDF("id", "device", "purchase_time")
运行以下命令将此数据追加到 AWS S3 上的 Delta 表:
val df2 = df.withColumn("purchase_time",to_timestamp($"purchase_time"))
df2.write.format("delta").mode("append").save("s3a://delta-test/delta_test_table")
重新生成 manifest 以在 Vertica 中查看新更改:
更新数据¶
在以下示例中,我们更新了 Delta 表的所有记录,包括 id。要更新记录,需要先将数据导入 Apache Spark,然后更新。
import io.delta.tables._
import org.apache.spark.sql.functions._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")
deltaTable.update(
condition = expr("id % 2 == 0"),
set = Map("id" -> expr("id + 100")))
deltaTable.toDF.show()
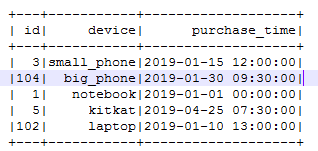
Delta 表已更新,但如果在 Vertica 中查询该表,仍然显示旧记录,因为 manifest 尚未更新。
重新生成 manifest 以获取更新后的记录:
删除数据¶
运行以下命令删除 Delta 表的所有记录(包括基于条件的 id),并重新生成 manifest:
import io.delta.tables._
import org.apache.spark.sql.functions._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")
deltaTable.delete(condition = expr("id % 2 == 0"))
deltaTable.generate("symlink_format_manifest")
deltaTable.toDF.show()
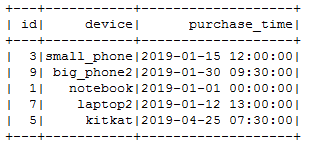
当在 Vertica 中查询数据时,数据可能看起来不一致。

重新生成 manifest 不会删除旧的 manifest,而是更新现有的 manifest。您必须删除 AWS S3 Delta 表中的 _symlink_format_manifest 目录,然后重新生成 manifest。
import io.delta.tables._
val deltaTable = DeltaTable.forPath("s3a://delta-test/delta_test_table")
deltaTable.generate("symlink_format_manifest")
更多信息¶
原文来源:https://www.vertica.com/kb/Vertica_DeltaLake_Technical_Exploration/Content/Partner/Vertica_DeltaLake_Technical_Exploration.htm