使用 VerticaPy 实现 OpenText Vertica 与 Qwak 的端到端机器学习方案¶
本文介绍使用 VerticaPy 集成 Vertica 和 Qwak 的方案。利用 Vertica 的数据库内机器学习功能和 Qwak 的 MLOps 能力,优化您的整个机器学习生命周期。
Qwak 是一个端到端的机器学习生产平台。它减少了机器学习研究与生产阶段之间的摩擦。Qwak 用于构建、部署和监控生产中的模型,从而减少工程工作量。Qwak 的功能包括 CI/CD、版本管理、模型分析和特征存储(Feature Store)。
本文档提供了一个端到端的解决方案,涵盖将数据加载到 Vertica、使用 VerticaPy 连接 Vertica 和 Qwak、执行数据科学操作以及在 Qwak 平台上部署 ML 模型的全过程。
VerticaPy 是一个 Python 库,具有类似 scikit-learn 的功能,用于 Vertica 的机器学习和高级分析。
Vertica 与 Qwak 的高层设计¶
下图展示了 Qwak 如何通过 VerticaPy 连接到 Vertica,以构建、部署和监控您的机器学习模型的高层设计。Qwak 允许您自定义模型结构,通过该结构您可以使用 VerticaPy 连接到 Vertica,如下设计图所示。
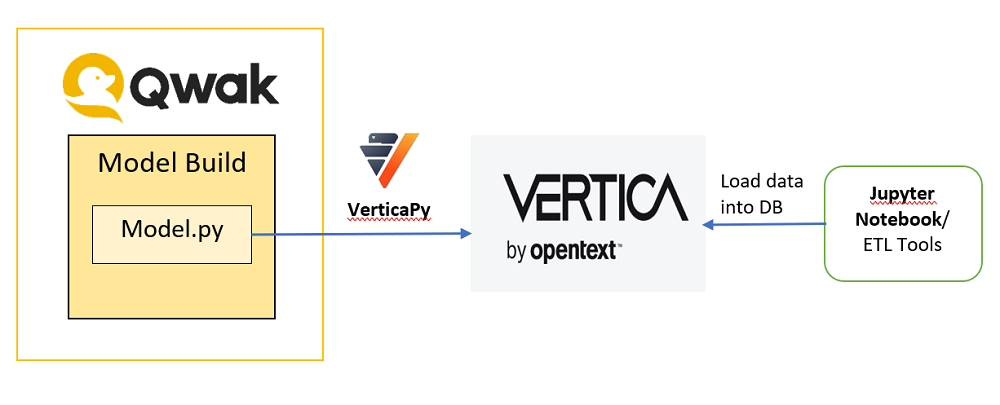
然后,您可以使用模型类(model class)进行数据探索、数据准备、模型构建、模型训练和预测。以下各节提供了逐步说明,涵盖以下内容:
- 使用示例数据集
- 将数据加载到 Vertica
- 安装和设置 Qwak SDK
- 创建项目
- 创建模型
- 构建模型
- 部署模型
- 自动化模型构建与部署
- 模型预测
- 查询模型预测结果
环境¶
首先,您需要搭建以下环境:
- Qwak 云实例
- Vertica Analytical Database 12.0.4
- 在 Qwak 平台上安装 VerticaPy 库
- Jupyter Notebook 或其他任何 ETL 工具,用于将数据加载到 Vertica
假设条件与前置要求¶
- Qwak 已在云端或本地搭建完成,且实例正常运行。
- 已安装 Git,并安装 Python 3.7-3.9 版本。
- 已安装 Qwak SDK。
- 从 Qwak 到 Vertica 实例之间不存在防火墙/连接问题。
预测客户流失的逐步机器学习方案¶
本方案的目标是构建并训练一个模型,用于预测哪些电信用户可能流失,即哪些客户可能停止使用电信服务。
该示例说明了如何从 Vertica 中的数据集开始,使用 VerticaPy 功能在 Qwak 中进行数据探索、数据准备和数据建模,以识别数据集中的趋势。该示例还描述了如何将布尔值转换为数值并创建虚拟变量(dummies),以帮助模型理解分类变量。最后,您将创建一个 RandomForestClassifier(随机森林分类器)模型,使用数据集训练该模型,并部署模型以预测客户流失。
注意:以下各节是可折叠/展开的。请务必点击这些主题以阅读更多内容。
使用示例数据集¶
在我们的方案中,我们使用了 CSV 格式的"Telco Customer Churn"(电信客户流失)数据集。该数据集包含 21 列,包括:
- Churn(流失) — 上个月内离开的客户。
- Services(服务) — 每位客户的服务(电话、多条线路、互联网、在线安全、在线备份、设备保护、技术支持以及流媒体电视和电影)。
- Customer account information(客户账户信息) — 客户使用时长、合同类型、付款方式、无纸化账单、月费和总费用。
- Customer demographics(客户人口统计信息) — 性别、年龄范围,以及是否有伴侣和受抚养人。
目标是了解这些预测变量如何影响流失,以及如何使用 VerticaPy 功能检测客户流失。
如果您想探索这些数据,可以通过在 Kaggle 网站上注册来下载相同的文件:Churn Dataset。
在以下各节中,我们将带您逐步了解使用 Qwak 创建模型以预测客户流失的整个过程。
将数据加载到 Vertica¶
我们使用 VerticaPy 通过 Jupyter Notebook 将示例数据集加载到 Vertica。
- 打开 Jupyter Notebook,运行以下命令安装 VerticaPy:
- 提供 Vertica 数据库连接详情以连接到 Vertica。
import verticapy as vp
# Creating a new connection
vp.new_connection({"host": "<Verticahost>",
"port": "5433",
"database": "<Verticadbname>",
"password": <password>,
"user": "dbadmin"},
name = "MyVerticaConnection")
# Connecting to the Database
vp.connect("MyVerticaConnection")
- 现在,创建一个新的 schema。
- 使用以下命令将 Churn 数据集加载到 Vertica,其中我们传入下载数据集的路径、表名和 schema 名称。
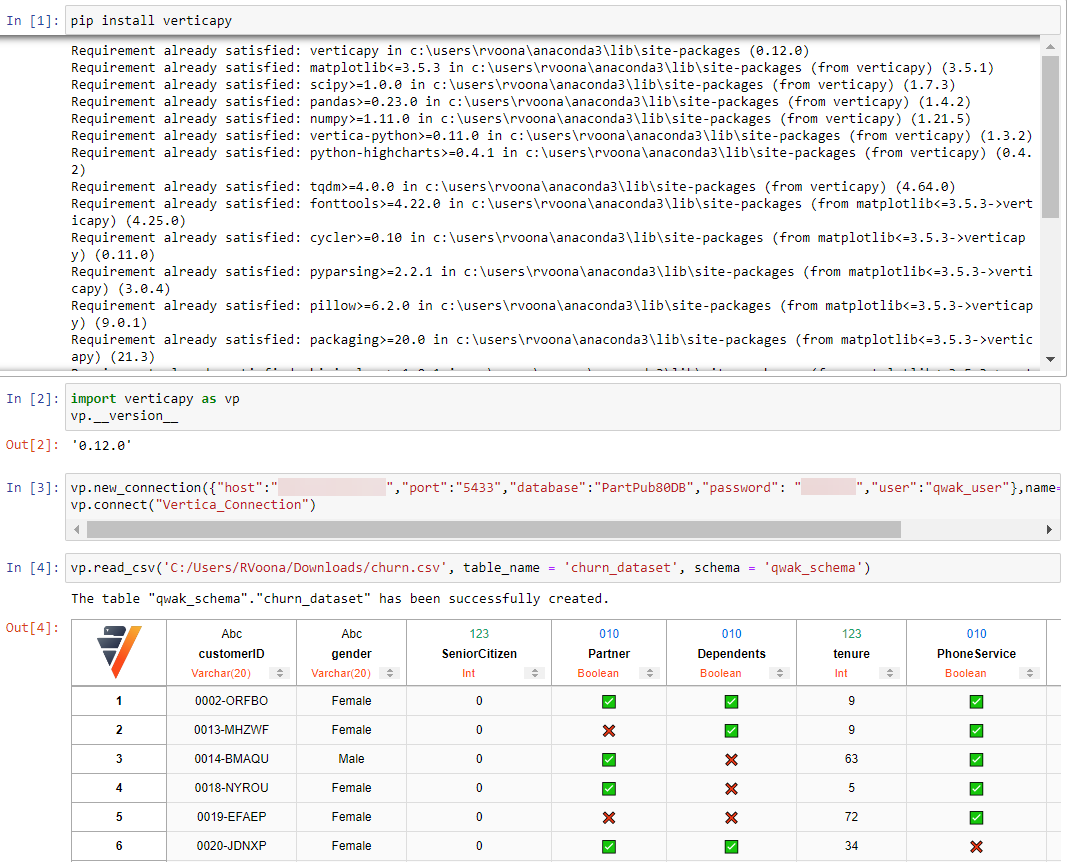
您也可以选择使用任何 ETL 工具。有关将 CSV 数据加载到新表或现有表的步骤,请参阅"导入表数据"(Importing Table Data)以获取更多信息。
安装和设置 Qwak SDK¶
- 联系 Qwak 支持团队以获取您的 API 密钥和用户名。
- 使用 cmd 安装 Git 并安装 Python 3.7-3.9 版本。建议使用虚拟环境。
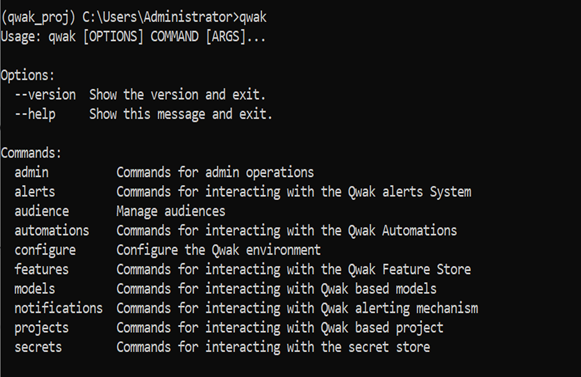
- 在控制台中运行以下命令安装 Qwak Python SDK:
pip install --extra-index-url https://qwak:A3RX55aNSpE8dCV@qwak.jfrog.io/artifactory/api/pypi/qwak-pypi/simple "qwak-sdk<0.10"
- 安装 Qwak SDK 后,验证 Qwak 命令是否正常工作。
- 使用
qwak configure命令验证用户身份并配置 Qwak 环境,以便在 Qwak 平台上执行操作。输入您的 API 密钥。

- 如果身份验证成功,您将看到"User successfully configured"(用户配置成功)消息。

创建项目¶
您可以通过 Qwak UI 或 CLI 命令创建项目:
使用 Qwak UI
- 使用您的凭据登录 Qwak 云实例。
- 单击"Create new project"(创建新项目)。

- 输入项目名称和描述。单击"Create project"(创建项目)。
使用 CLI 命令
运行以下命令创建项目:
您可以使用以上任一方法创建项目。项目创建后将在 Qwak UI 中可见。
创建模型¶
您可以通过 Qwak UI 或 CLI 命令创建模型:
使用 Qwak UI
- 打开项目,单击"Create new model"(创建新模型)。

- 输入模型名称和描述。单击"Create model"(创建模型)。
使用 CLI 命令
运行以下命令使用 CLI 创建模型:
qwak models create --project-id {project_id} --model-name "churn_model" --model-description "Predict churn customer"
您可以使用以上任一方法创建模型。模型创建后将在 Qwak UI 的项目中可见。
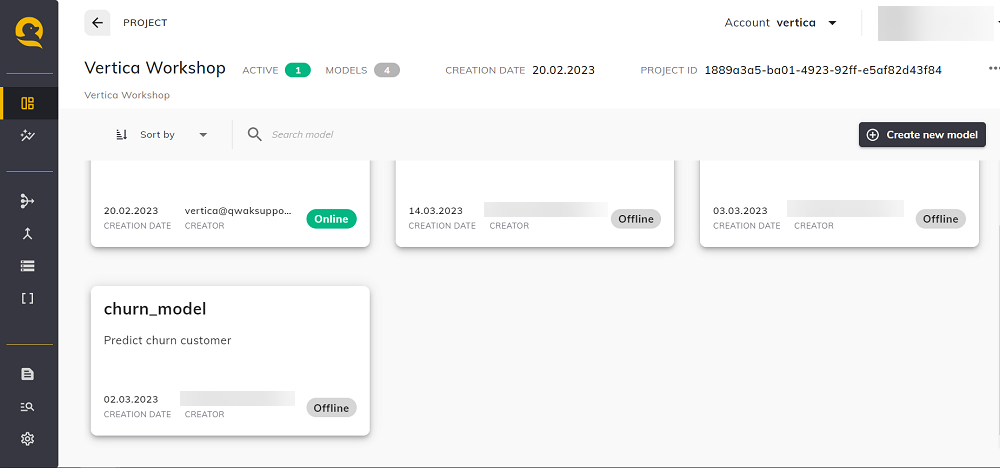
构建模型¶
生成模型目录结构¶
Qwak 提供了一个默认的模型目录结构。

您可以使用以下命令为基于 Qwak 的模型生成目录结构:

这将在您的主目录中创建一个名为 churn_model 的新目录。其中包含 main 和 tests 目录,main 目录中包含所需的文件,如 __init__.py、conda.yml、model.py,tests 目录中包含 test_qwak_model.py。
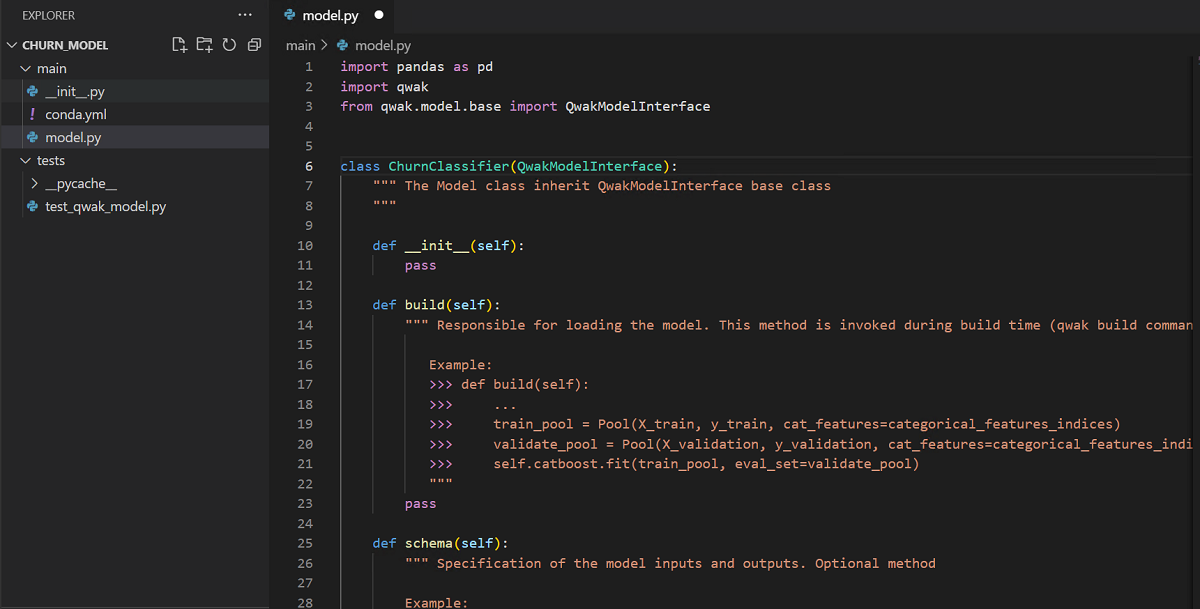
主目录(Main Directory)¶
__init__.py文件设置 Qwak 模型类的导入,以便模型构建过程能够识别该类。
该文件包含以下代码:
conda.yml是一个依赖文件,包含项目所依赖的外部包。Qwak 在构建时下载并链接这些依赖项。
在此文件中,我们添加了 VerticaPy 以便连接到 Vertica 数据库。
name: ChurnClassifier
channels:
- defaults
- conda-forge
dependencies:
- python=3.8
- pip=22.2.2
- pandas=1.1.5
- pip:
- --extra-index-url https://qwak:A3RX55aNSpE8dCV@qwak.jfrog.io/artifactory/api/pypi/qwak-pypi/simple qwak-sdk==0.9.134
- verticapy==0.12.0
model.py创建一个模型类,该类定义了两个必需方法(build和predict)以及两个可选方法(schema和initialize_model)。
以下是 model.py 文件中的默认代码,您可以根据需求进行更新:
import pandas as pd
import qwak
from qwak.model.base import QwakModelInterface
class ChurnClassifier(QwakModelInterface):
""" The Model class inherit QwakModelInterface base class
"""
def __init__(self):
pass
def build(self):
""" Responsible for loading the model. This method is invoked during build time (qwak build command)
Example:
>>> def build(self):
>>> ...
>>> train_pool = Pool(X_train, y_train, cat_features=categorical_features_indices)
>>> validate_pool = Pool(X_validation, y_validation, cat_features=categorical_features_indices)
>>> self.catboost.fit(train_pool, eval_set=validate_pool)
"""
pass
def schema(self):
""" Specification of the model inputs and outputs. Optional method
Example:
>>> from qwak.model.schema import ModelSchema, Prediction, ExplicitFeature
>>>
>>> def schema(self) -> ModelSchema:
>>> model_schema = ModelSchema(
>>> features=[
>>> ExplicitFeature(name="State", type=str),
>>> ],
>>> predictions=[
>>> Prediction(name="score", type=float)
>>> ])
>>> return model_schema
Returns: a model schema specification
"""
pass
def initialize_model(self):
"""
Invoked when a model is loaded at serving time. Called once per model instance initialization. Can be used for
loading and storing values that should only be available in a serving setting or loading pretrained models. Optional method
Example usage:
>>> def initialize_model(self):
>>> with open('model.pkl', 'rb') as infile:
>>> self.model = pickle.load(infile)
"""
pass
@qwak.api()
def predict(self, df: pd.DataFrame) -> pd.DataFrame:
""" Invoked on every API inference request.
Args:
pd (DataFrame): the inference vector, as a pandas dataframe
Returns: model output (inference results), as a pandas dataframe
"""
pass
测试目录(Tests Directory)¶
test_qwak_model.py 文件定义了在构建过程中运行的集成测试。以下是您可以更新的默认代码:
def test_model():
"""
Skeleton for a test that will run as part of the build process
"""
assert True
更新模型类¶
您可以根据需求更新 model.py 中的代码,以定义如何连接 Vertica 数据库、准备数据、构建模型以及进行推理。这里,我们将展示两种基于推理(Inference)执行位置的情况来更新 model.py 中的代码:推理在 Qwak 内存中执行,以及推理在 Vertica 数据库内部执行。推理是将 ML 模型应用于数据集并生成输出或"预测"的方法。
注意:在两种情况下,训练数据始终位于 Vertica 数据库中。两种情况的区别在于:第一种情况下推理在 Vertica 内部完成,第二种情况下推理在 Qwak 内存中完成。
情况一:在 Vertica 数据库中进行推理¶
用于推理的输入数据可以位于 Vertica 中。我们通过将输入数据作为一个 Pandas Dataframe(其中包含一列,该列存储已在 Vertica 中用于预测的表名)传入,在 Vertica 数据库内部运行推理,然后准备数据进行预测。针对模型运行预测,模型将在 Vertica 内部执行预测。预测结果保存到 Vertica 数据库中。
以下代码说明了连接到 Vertica 数据库、准备数据、训练模型和进行预测的过程:
import pandas as pd
import verticapy as vp
import qwak
from verticapy.utilities import *
from verticapy.learn.tools import *
from qwak.model.base import QwakModelInterface
from verticapy.learn.ensemble import RandomForestClassifier
from verticapy.learn.preprocessing import OneHotEncoder
# create connection with vertica DB
CONN_INFO = {
"host": "hostname",
"port": "port",
"database": "dbname",
"password": "pwd",
"user": "user"
}
vp.new_connection(CONN_INFO, name='qwak_conn')
class ChurnClassifier(QwakModelInterface):
""" The Model class inherit QwakModelInterface base class
"""
def __init__(self):
# Connect with the DB
vp.connect('qwak_conn')
# Initialize the model
self.rf_model = RandomForestClassifier(name="qwak_schema.rf_churn",
n_estimators=10,
max_features="auto",
max_leaf_nodes=32,
sample=0.7,
max_depth=5,
min_samples_leaf=1,
min_info_gain=0.0,
nbins=32)
@staticmethod
def data_preparation(vdf, train=True):
"""method to prepare data"""
vdf["TotalCharges"].dropna()
for column in [
"DeviceProtection",
"MultipleLines",
"PaperlessBilling",
"TechSupport",
"Partner",
"StreamingTV",
"OnlineBackup",
"Dependents",
"OnlineSecurity",
"PhoneService",
"StreamingMovies",
]:
vdf[column].decode("Yes", 1, 0)
if train:
enc = OneHotEncoder(name="qwak_schema.ohe_churn")
enc.fit(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
vdf = enc.transform(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
else:
model_enc = load_model("qwak_schema.ohe_churn")
vdf = model_enc.transform(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
vdf.drop(["gender", "Contract", "PaymentMethod", "InternetService"])
return vdf
def build(self):
"""
Responsible for loading the model. This method is invoked during build time (qwak build command)
This function train and save the model inside vertica using data inside vertica
"""
# Read the data from DB and prepare it for model training
churn = ChurnClassifier.data_preparation(vp.vDataFrame("qwak_schema.churn"))
churn['churn'].decode("Yes", 1, 0)
# Split the data to train and test
train, test = churn.train_test_split(test_size=0.2, random_state=0)
# drop the model if already exist
self.rf_model.drop()
# features
predictors = train.get_columns(exclude_columns=['churn', 'customerID'])
# fit the model
self.rf_model.fit(input_relation=train,
X=predictors,
y='churn',
test_relation=test)
# Compute the metric score
accuracy_score = self.rf_model.score("accuracy")
qwak.log_metric({"accuracy_score": accuracy_score})
@qwak.api()
def predict(self, input_data: pd.DataFrame) -> pd.DataFrame:
""" Invoked on every API inference request.
Args:
input_data (Dataframe): dataframe with one column that have the table name to use for prediction.
Returns: model output (inference results), as dataframe with the size of the input, f1 and accuracy metrics to make sure that the prediction is preformed.
"""
# get the table name from the input
table_name = input_data['table_name'].values[0]
# read the table
input_data = vp.vDataFrame(table_name, schema="qwak_schema")
# prepare the data for prediction
input_data = ChurnClassifier.data_preparation(input_data, train=False)
input_data['churn'].decode("Yes", 1, 0)
# list of the independent variables
predictors = input_data.get_columns(exclude_columns=['churn', 'customerID'])
# predict
output_data = self.rf_model.predict(input_data, predictors, name='churn_pred')
# save the results in DB
output_data.to_db(name='"qwak_schema"."churn_ref"', relation_type="insert")
# return the output to pandas DataFrame
return output_data.to_pandas()
情况二:在 Qwak 内存中进行推理¶
用于推理的输入数据可以位于内存中。我们通过将 pandas dataframe 作为输入,并将 Vertica 模型转换为 memmodel,在内存中运行推理,然后模型在 Qwak 内存内部执行预测。
它将返回 Pandas Dataframe 作为输出,并且我们通过将 pandas 转换为 Vertica dataframe 将结果保存到 Vertica 数据库中。
import pandas as pd
import verticapy as vp
import qwak
from verticapy.utilities import *
from qwak.model.base import QwakModelInterface
from verticapy.learn.ensemble import RandomForestClassifier
from verticapy.learn.preprocessing import OneHotEncoder
from verticapy.learn.tools import *
import warnings
warnings.filterwarnings('ignore')
CONN_INFO = {
"host": "hostname",
"port": "port",
"database": "dbname",
"password": "pwd",
"user": "user"
}
vp.new_connection(CONN_INFO, name='qwak_conn')
class churnClassifier(QwakModelInterface):
"""The Model class inherit QwakModelInterface base class
In this case we train and score using in memory model
"""
def __init__(self):
# Connect with the DB
vp.connect('qwak_conn')
# Initialize the model
self.rf_model = RandomForestClassifier(
name="qwak_schema.rf_churn",
n_estimators=10,
max_features="auto",
max_leaf_nodes=32,
sample=0.7,
max_depth=5,
min_samples_leaf=1,
min_info_gain=0.0,
nbins=32,
)
@staticmethod
def data_preparation(vdf, train=True):
"""method to prepare data"""
vdf["TotalCharges"].dropna()
for column in [
"DeviceProtection",
"MultipleLines",
"PaperlessBilling",
"TechSupport",
"Partner",
"StreamingTV",
"OnlineBackup",
"Dependents",
"OnlineSecurity",
"PhoneService",
"StreamingMovies",
]:
vdf[column].decode("Yes", 1, 0)
if train:
enc = OneHotEncoder(name="qwak_schema.ohe_churn")
enc.fit(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
vdf = enc.transform(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
else:
model_enc = load_model("qwak_schema.ohe_churn")
vdf = model_enc.transform(vdf,
["gender", "Contract", "PaymentMethod", "InternetService"])
vdf.drop(["gender", "Contract", "PaymentMethod", "InternetService"])
return vdf
def build(self):
"""Responsible for loading the model. This method is invoked during build time (qwak build command)"""
# Read the data from DB and prepare it for model training
churn = churnClassifier.data_preparation(vp.vDataFrame("qwak_schema.churn"))
churn['churn'].decode("Yes", 1, 0)
# Split the data to train and test
train, test = churn.train_test_split(test_size=0.2, random_state=0)
# drop the model if already exist
self.rf_model.drop()
predictors = churn.get_columns(exclude_columns=["churn", "CustomerID"])
# fit the model
self.rf_model.fit(input_relation=train,
X=predictors,
y="churn",
test_relation=test
)
# Compute the metric score
accuracy_score = self.rf_model.score("accuracy")
qwak.log_metric({"accuracy_score": accuracy_score})
@qwak.api()
def predict(self, input_data: pd.DataFrame) -> pd.DataFrame:
"""
Invoked on every API inference request.
This method take DataFrame as input, then the model does the
prediction. At the end the results are saved in Vetica and return DataFrame
Args:
input_data (list/DataFrame): the inference vector, as a list of lists
Returns: model output (inference results), as a DataFrame
"""
# convert the model to memmodel
m_model = self.rf_model.to_memmodel()
# selected features
predictors = ['gender_1', 'seniorcitizen','partner','dependents','tenure', 'phoneservice','multiplelines',
'InternetService_1','InternetService_2','onlinesecurity','onlinebackup','deviceprotection','techsupport',
'streamingtv','streamingmovies','Contract_1','Contract_2','paperlessbilling','PaymentMethod_1',
'PaymentMethod_2','PaymentMethod_3', 'monthlycharges','totalcharges']
# create pandas df of the predictions
input_data['churn_pred'] = m_model.predict(input_data[predictors])
# save data in vertica
pandas_to_vertica(df=input_data, name="churn_ref", schema="qwak_schema", insert=True)
return input_data
更新测试文件¶
您可以按照以下方式更新 test_qwak_model.py 中的代码:
推理在 Vertica 数据库中¶
用于集成测试的输入数据是已存储在 Vertica 中的表。
import pandas as pd
from qwak_mock import real_time_client
def test_churn_classifier(real_time_client):
feature_vector = [{"table_name":"churn_to_pred_1"}]
predict_res = real_time_client.predict(feature_vector)
assert predict_res['churn_pred'].values[0] == '0'
推理在 Qwak 内存中¶
用于集成测试的输入数据是在 Qwak 外部已准备好的数据。
from qwak_mock import real_time_client
def test_churn_classifier(real_time_client):
feature_vector = [{'customerid': '0137-OCGAB',
'gender_1': 0,
'seniorcitizen': 0,
'partner': 0,
'dependents': 0,
'tenure': 1,
'phoneservice': 1,
'multiplelines': 1,
'InternetService_1': 1,
'InternetService_2': 0,
'onlinesecurity': 0,
'onlinebackup': 1,
'deviceprotection': 0,
'techsupport': 0,
'streamingtv': 0,
'streamingmovies': 0,
'Contract_1': 0,
'Contract_2': 0,
'paperlessbilling': 1,
'PaymentMethod_1': 0,
'PaymentMethod_2': 0,
'PaymentMethod_3': 1,
'monthlycharges': 80.200,
'totalcharges': 80.200,
'churn': True}]
churn_pred = real_time_client.predict(feature_vector)
assert churn_pred['churn_pred'].values[0] == 1
构建模型¶
完成模型文件夹中文件的更新后,在 CLI 中切换到模型目录并运行以下命令来执行模型构建过程:

构建过程可能需要几分钟时间。运行模型后,您可以在模型内部查看已创建的构建。
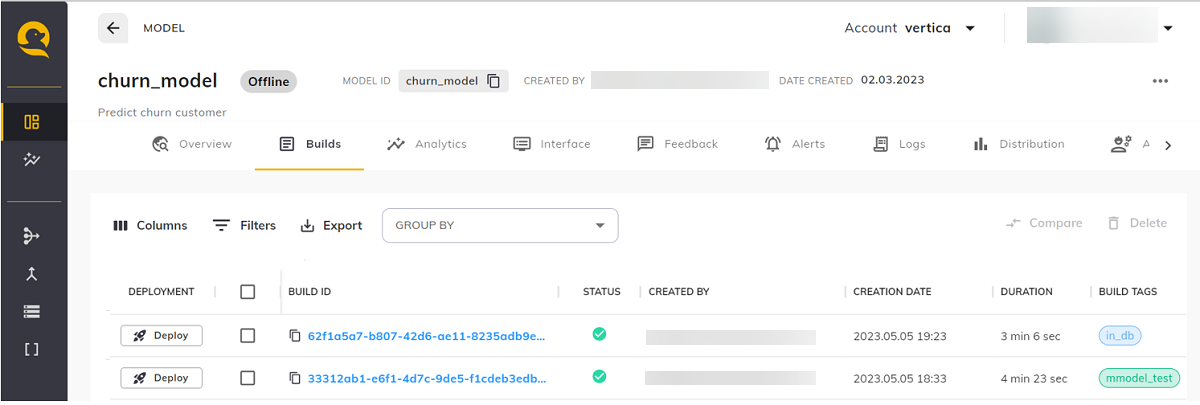
您可以通过单击构建 ID,在构建页面的"Logs"(日志)选项卡中查看各构建的日志。
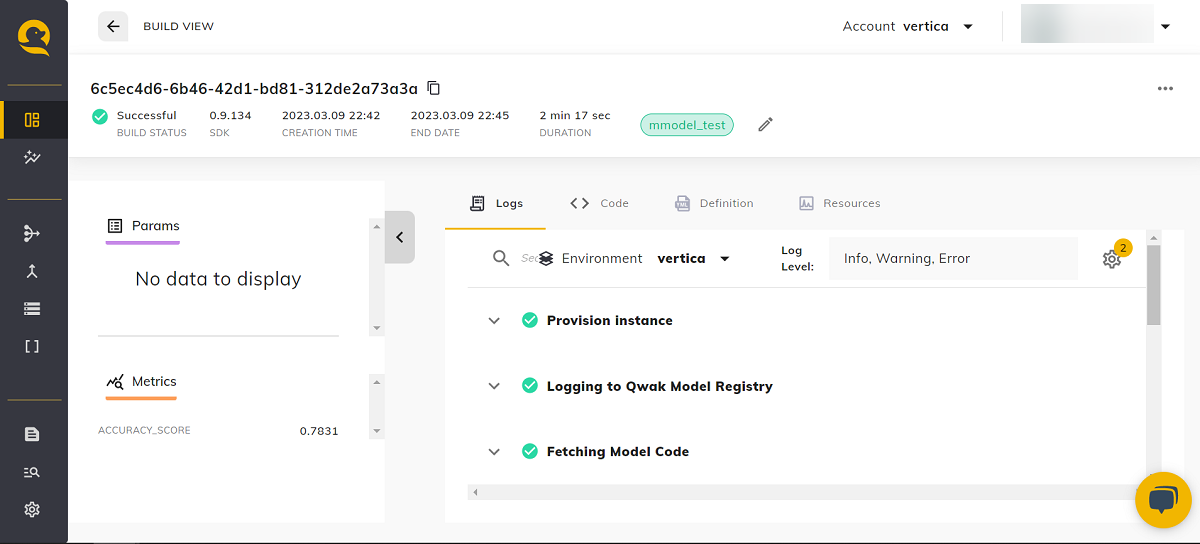
您可以通过构建页面的"Code"(代码)选项卡查看各构建的代码。
部署模型¶
构建成功后,将模型作为运行在 Qwak 平台上的端点进行部署。
从 Qwak UI 部署模型:
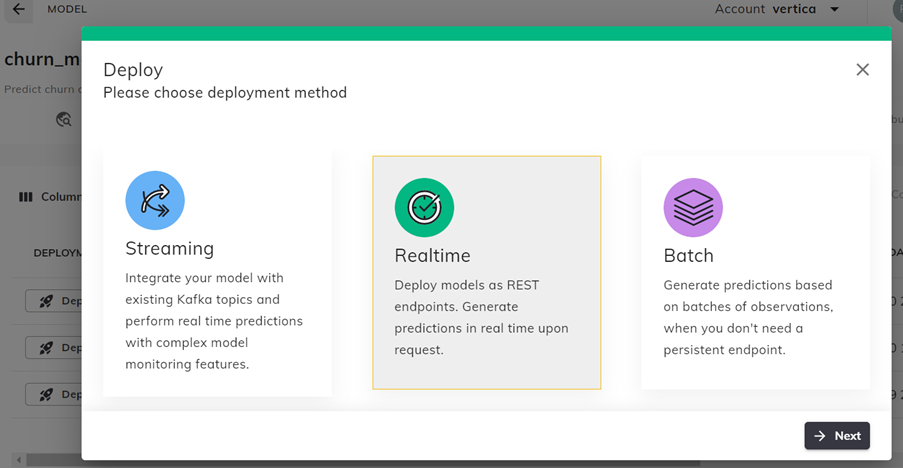
- 在模型的构建页面中单击"Deploy"(部署)。
- 选择部署方式,然后单击"Next"(下一步)。这里我们选择了"Realtime"(实时)。
- 通过选择初始 Pod 数量、CPU 配额和内存来配置实时部署。
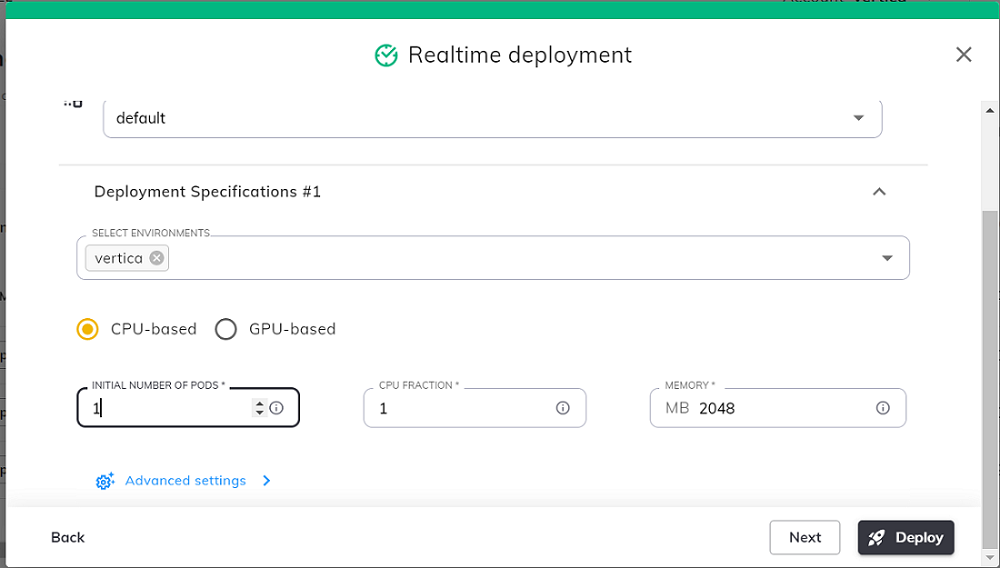
- 配置高级设置,例如注入环境变量、设置调用超时等,然后单击"Deploy"(部署)。
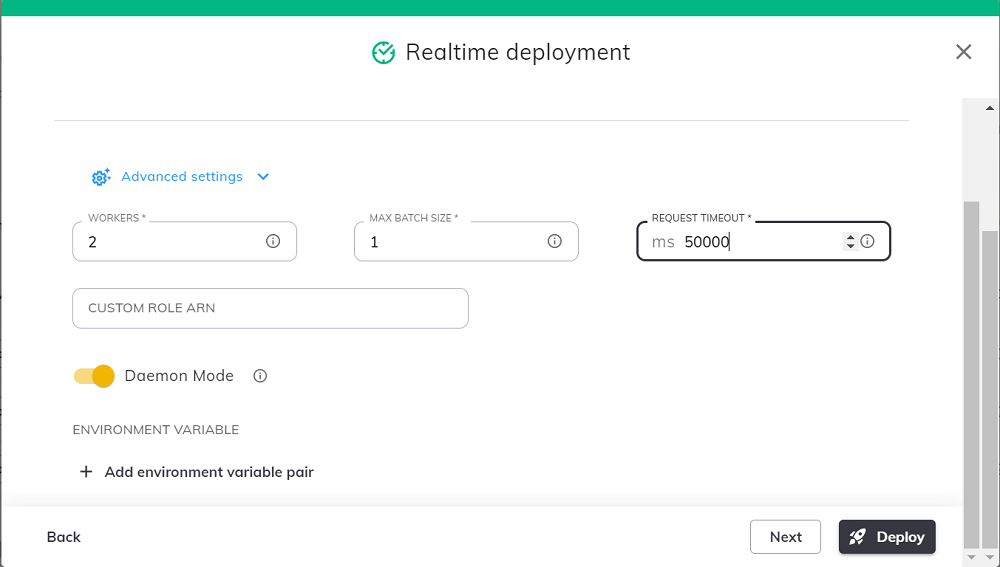
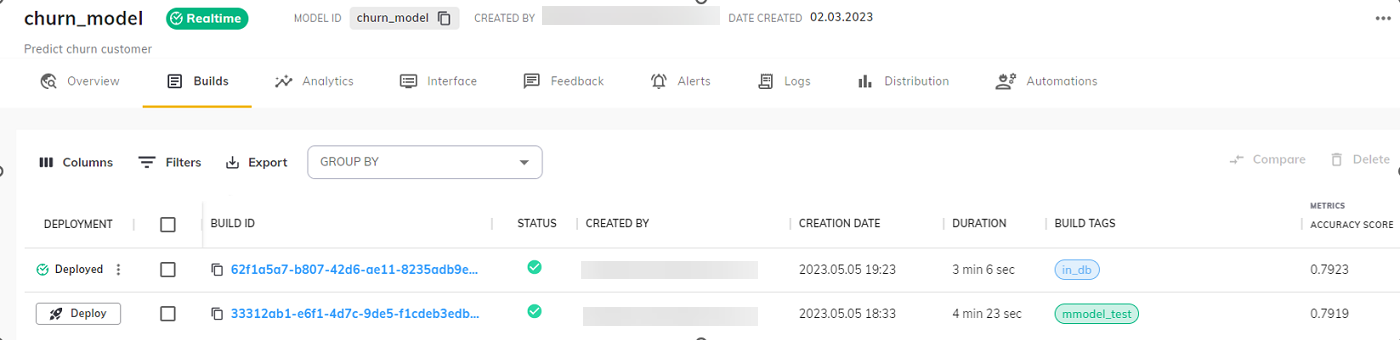
- 您将在构建页面中看到该构建已成功部署。
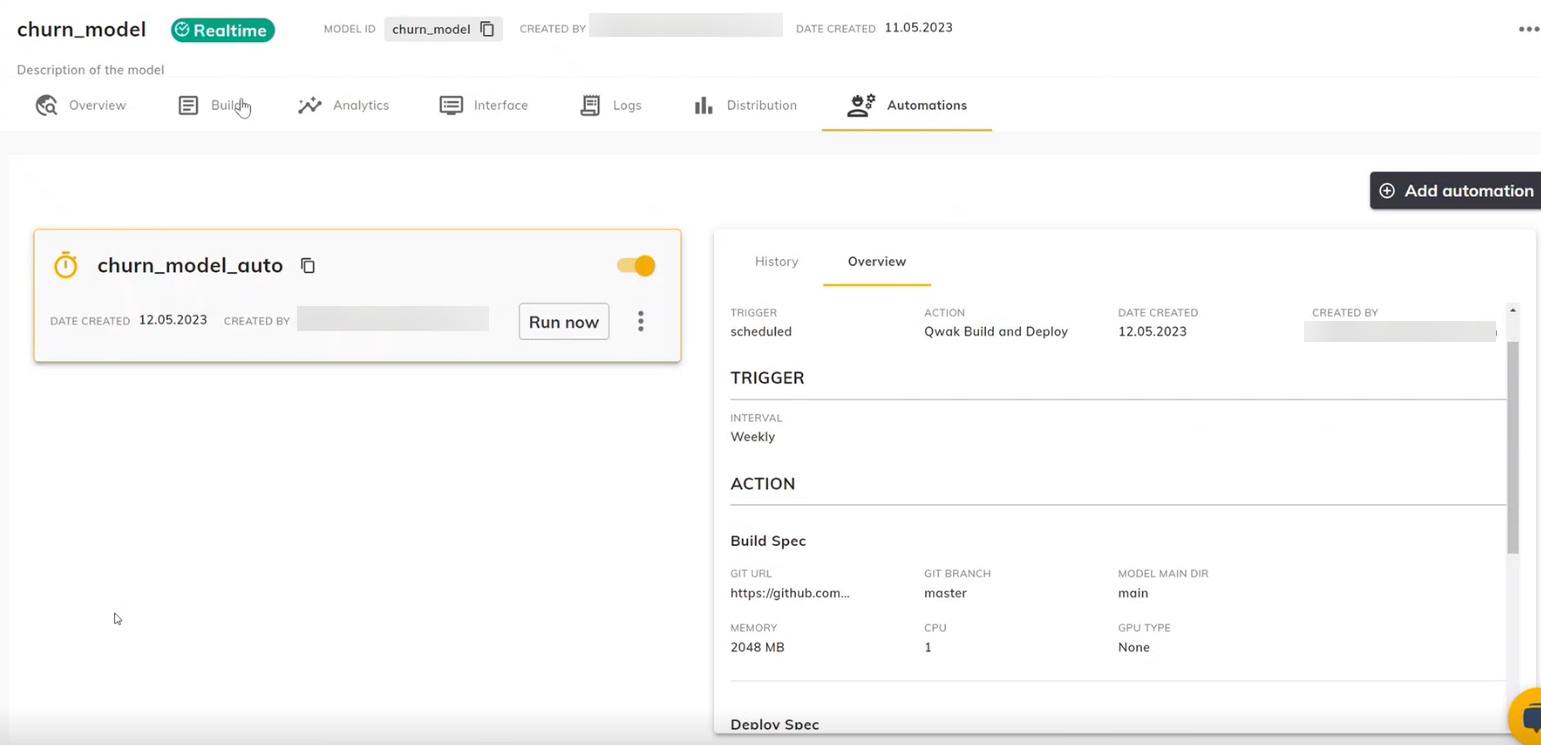
自动化模型构建与部署¶
自动化模型构建和部署有助于保持模型在生产环境中的准确性。通过基于 cron 表达式、定义的时间间隔或基于指标的触发器自动重新训练和部署,使您的模型保持准确。
- 在模型的"Automations"(自动化)页面中,单击"Create your first automation"(创建您的第一个自动化)。
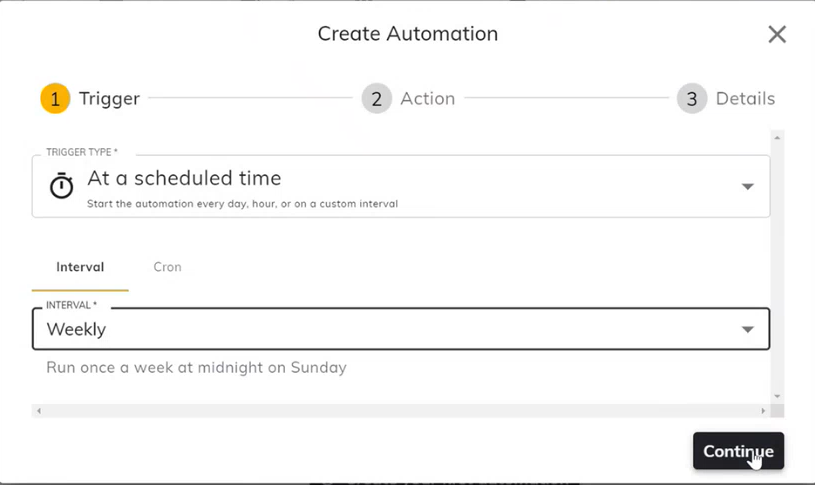
- 自动化训练由时间间隔或条件触发。您可以按时间计划进行自动化,甚至可以是每天、每小时、每周,或者使用 CRON 设置其他周期。单击"Continue"(继续)。
- 您需要将代码推送到 Git,以便平台在需要时拉取代码,然后提供 Git URL、分支和资源信息。
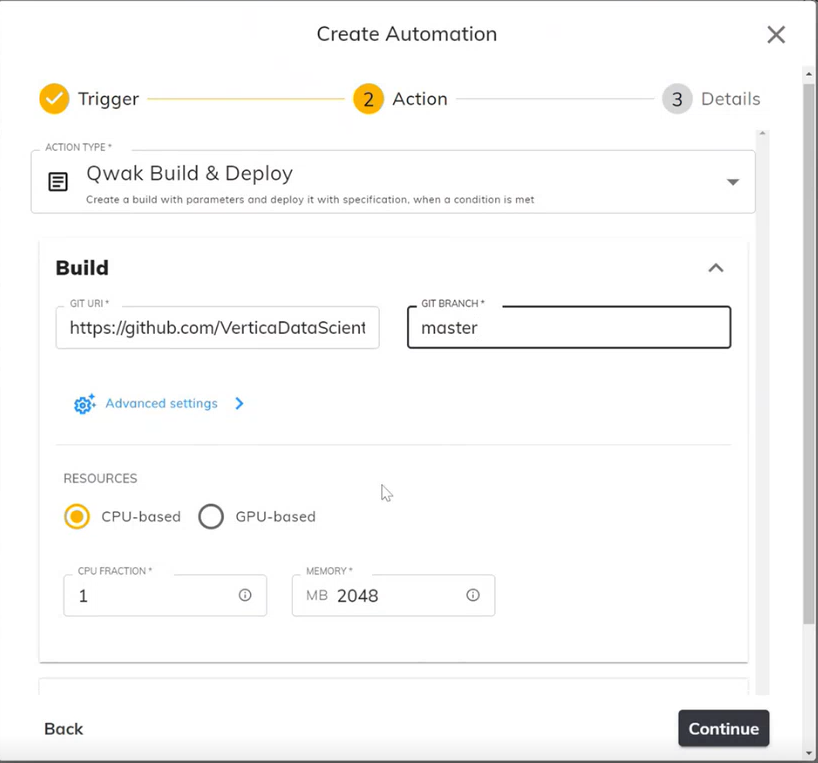
- 向下滚动并设置部署规范。
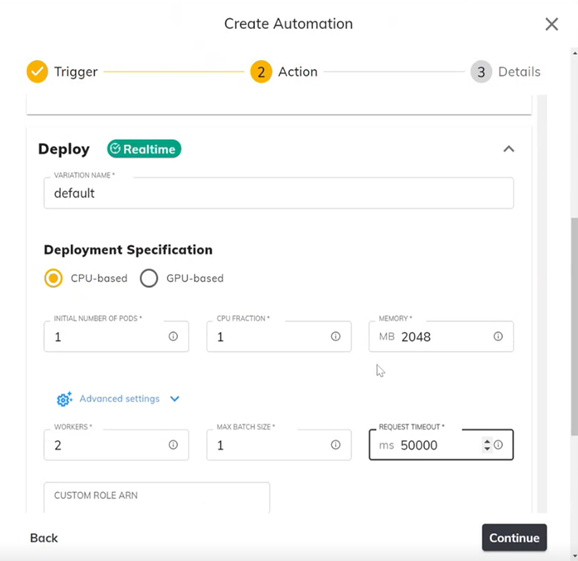
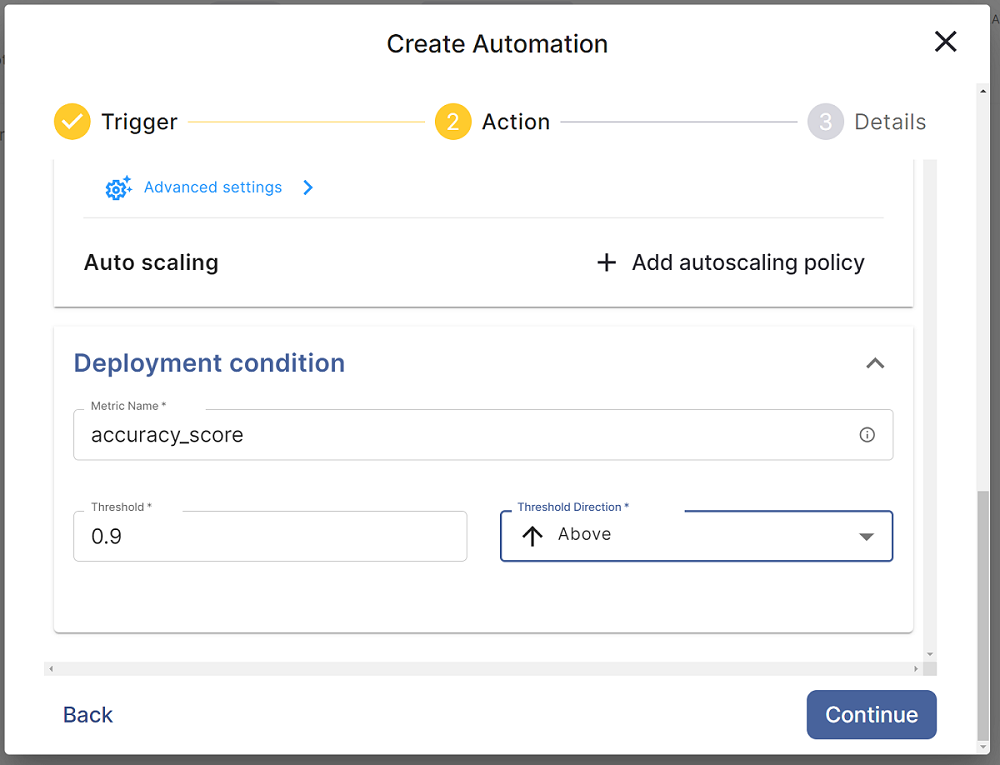
- 然后,您可以根据偏好的指标设置部署条件。您可以为此设置一个阈值,这样每当新模型训练完成时,系统将验证其评分是否满足阈值条件,并自动部署。单击"Continue"(继续)。
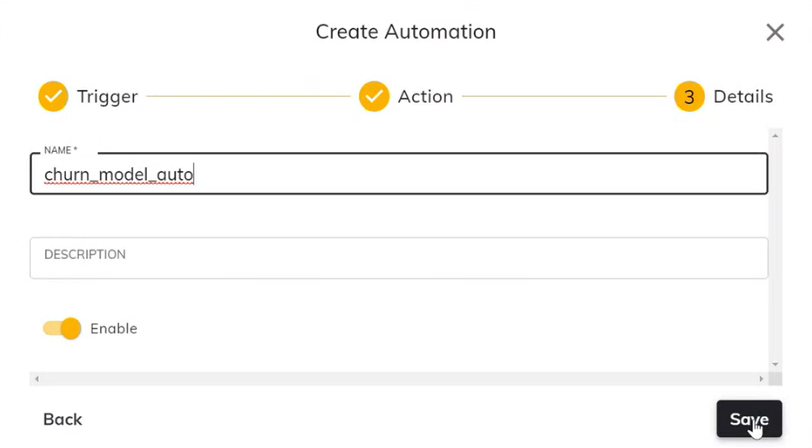
- 为自动化提供一个名称,然后单击"Save"(保存)。
- 单击"Run now"(立即运行)。它将作为模型的另一个版本运行。您可以检查为此自动化分配的资源,并在需要时进行编辑。
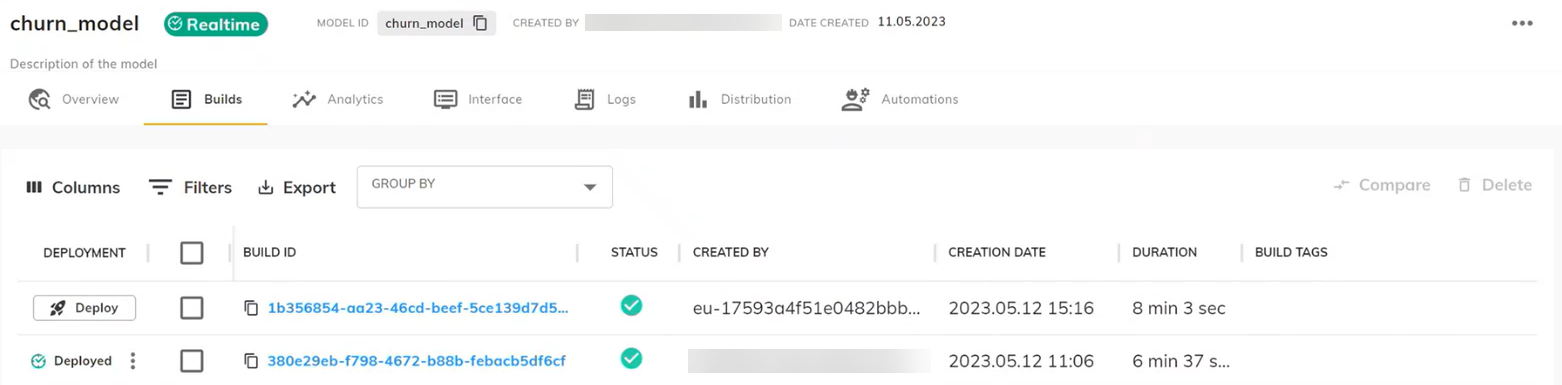
- 在"Builds"(构建)部分,您将看到通过自动化创建的版本,该版本将根据部署条件自动部署。
模型推理¶
部署模型后,通过执行一个 Python 文件来对模型运行预测,其中我们提供客户详细信息作为输入数据并运行预测,您将看到预测结果——该客户是否可能流失。
推理在 Vertica 数据库中¶
如果您已部署构建以在 Vertica 数据库内部运行预测,则执行以下 Python 文件。
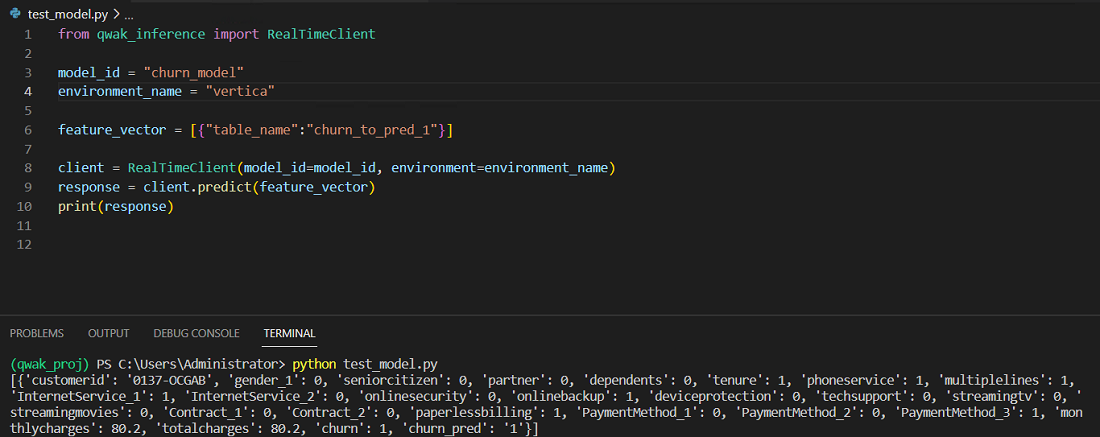
from qwak_inference import RealTimeClient
model_id = "churn_model"
environment_name = "vertica"
feature_vector = [{"table_name":"churn_to_pred_1"}]
client = RealTimeClient(model_id=model_id, environment=environment_name)
response = client.predict(feature_vector)
print(response)
推理在 Qwak 内存中¶
如果您已部署构建以在 Qwak 内存中运行预测,则执行以下 Python 文件。
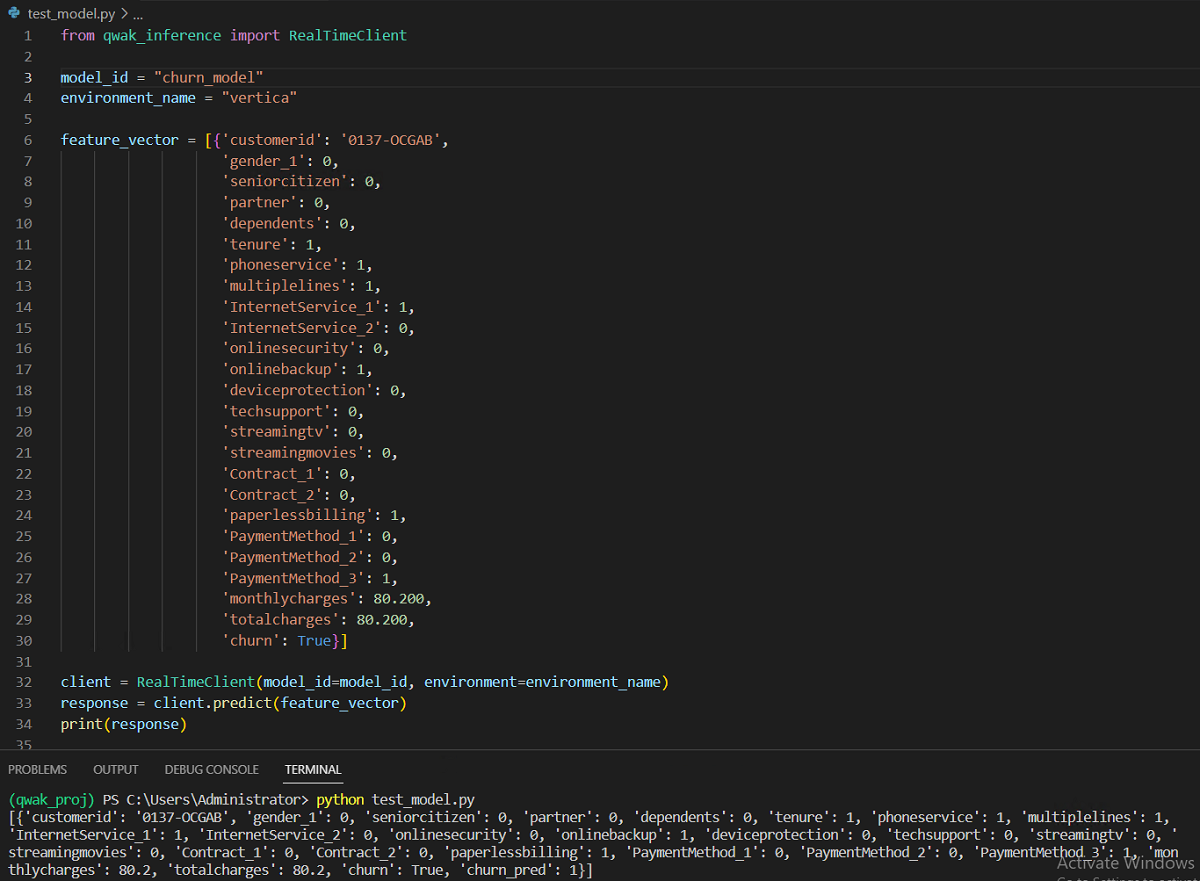
from qwak_inference import RealTimeClient
model_id = "churn_model"
environment_name = "vertica"
feature_vector = [{'customerid': '0137-OCGAB',
'gender_1': 0,
'seniorcitizen': 0,
'partner': 0,
'dependents': 0,
'tenure': 1,
'phoneservice': 1,
'multiplelines': 1,
'InternetService_1': 1,
'InternetService_2': 0,
'onlinesecurity': 0,
'onlinebackup': 1,
'deviceprotection': 0,
'techsupport': 0,
'streamingtv': 0,
'streamingmovies': 0,
'Contract_1': 0,
'Contract_2': 0,
'paperlessbilling': 1,
'PaymentMethod_1': 0,
'PaymentMethod_2': 0,
'PaymentMethod_3': 1,
'monthlycharges': 80.200,
'totalcharges': 80.200,
'churn': True}]
client = RealTimeClient(model_id=model_id, environment=environment_name)
response = client.predict(feature_vector)
print(response)
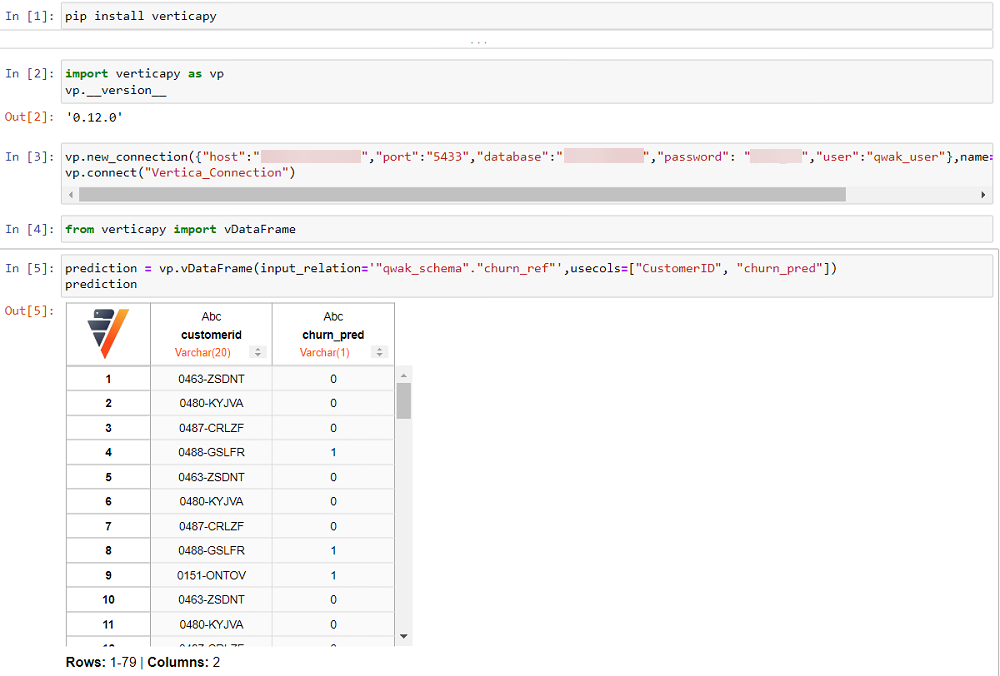
您可以通过 Jupyter Notebook 查看预测结果,这些结果在执行预测时(无论是在 Vertica 数据库内部还是在 Qwak 内存中)已保存在 Vertica 数据库中。
一旦您开始对模型运行预测,您将在"Overview"(概览)选项卡的"Health"(健康度)仪表板中看到相关指标。
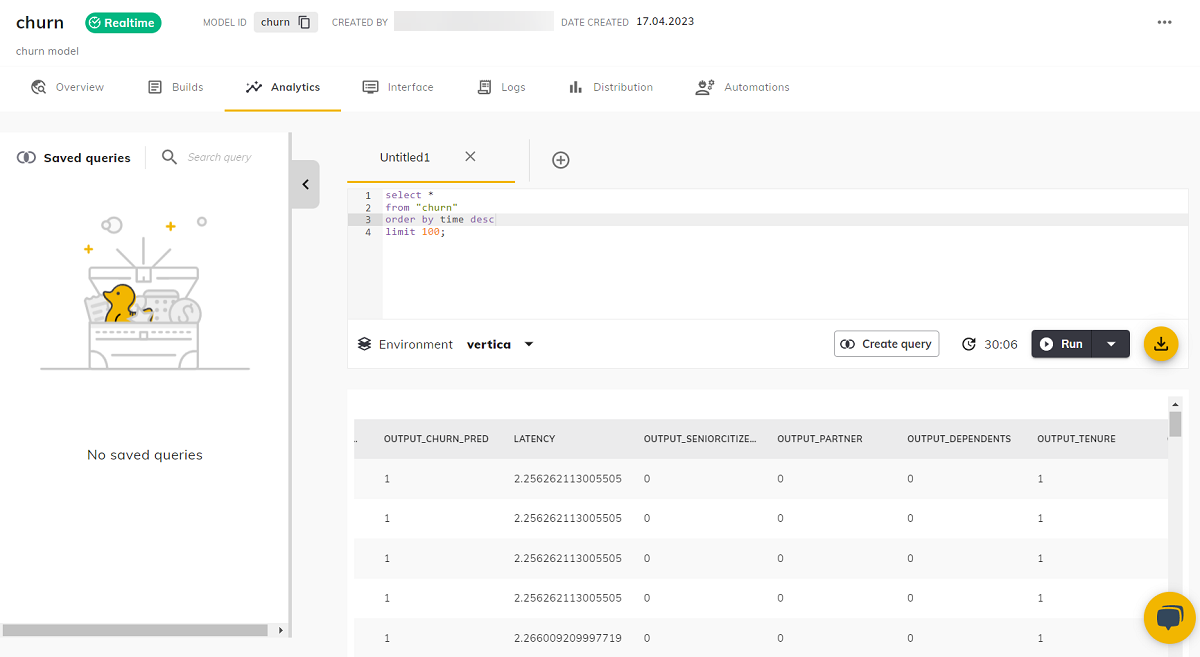
查询模型预测结果¶
您可以通过在"Analytics"(分析)部分查询模型来查看每次对模型调用的预测结果。
- 从模型页面单击"Analytics"(分析)。
- 根据您的需求输入查询。
- 单击"Run"(运行)。您将看到一个表格,其中包含每次对模型调用的预测结果行。