使用 VerticaPy 实现 Vertica 与 Saagie 的端到端机器学习方案¶
编译:JiangChong
本文介绍了一个使用 VerticaPy 实现 Vertica 与 Saagie 集成的端到端解决方案。利用 Vertica 的数据库内机器学习能力分析和建模数据,并通过 Saagie 推进您的 ML 管道。
Saagie 是一个 DataOps 平台,能够整合多种技术,让您可以快速、轻松且可靠地运行数据项目。该平台允许您组合使用多种技术来构建和管理数据项目的每一个步骤,从数据提取到可视化。
本文档提供了一个端到端解决方案,涵盖从将数据加载到 Vertica,到使用 VerticaPy 连接 Vertica 和 Saagie 以执行数据科学操作的完整流程。
VerticaPy 是一个 Python 库,具有类似 scikit-learn 的功能,用于 Vertica 的机器学习和高级分析。
Vertica 与 Saagie 高层设计¶
以下是 Saagie 如何使用 VerticaPy 及其他组件连接 Vertica 以进行机器学习和模型训练的高层设计。Saagie 提供 JOBS(作业)和 APPS(应用程序,如 Jupyter Notebook),您可以通过它们使用 VerticaPy 连接到 Vertica,如下图所示。
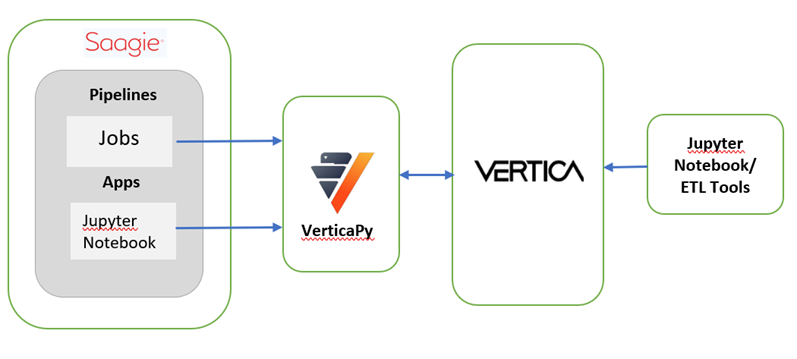
然后您可以探索和准备数据,并训练模型。后续章节将提供以下步骤的详细说明:
- 使用示例数据集
- 将数据加载到 Vertica
- 创建作业和应用程序(Jupyter Notebook)以使用 VerticaPy 连接 Vertica
- 探索和准备数据
- 训练和构建模型以评估并创建聚类
环境¶
开始之前,您需要搭建以下环境:
- Saagie 云实例
- Vertica 分析数据库 12.0.4
- 在 Saagie 环境中安装 VerticaPy 库
- Jupyter Notebook 或任何其他 ETL 工具,用于将数据加载到 Vertica
假设与前提条件¶
- Saagie 已搭建完成(云端或本地部署),实例正在运行。
- 从 Saagie 到 Vertica 实例之间没有防火墙或连接问题。
评估电影质量并创建聚类的分步机器学习方案¶
本方案的目标是构建并训练一个模型,用于分析和评估电影质量,并创建相似电影的聚类。
该示例说明了如何从 Vertica 中的数据集开始,使用 VerticaPy 功能在 Saagie 中执行数据探索、数据准备和数据建模。示例描述了数值列的归一化、数据分类以及创建虚拟变量以帮助模型理解分类变量。最后,还将展示如何创建回归模型和聚类模型,并使用数据集训练模型,以确定电影质量并创建相似电影的聚类。
注意:以下各节为可折叠/展开区域。请务必点击这些主题以阅读更多内容。
使用示例数据集¶
在我们的方案中,我们使用了 CSV 格式的 filmtv_movies 数据集。该数据集包含十二列:电影上映年份、电影 ID、片名、类型、产地国家、描述、电影相关信息、时长、投票数、平均评分、导演以及电影演员。
目标是了解这些预测变量如何影响电影质量,以及如何利用 VerticaPy 功能评估未来的电影质量并创建相似电影的聚类。
如果您想探索这些数据,可以通过在 Kaggle 网站上注册来下载相同的文件:Filmtv movies Datasets。
在以下各节中,我们将引导您完成使用 Jupyter Notebook 创建模型的整个过程。
将数据加载到 Vertica¶
使用 Jupyter Notebook¶
我们通过 Jupyter Notebook 使用 VerticaPy 将示例数据集加载到 Vertica。
- 打开 Jupyter Notebook 并通过运行以下命令安装 VerticaPy:
- 提供 Vertica 数据库连接详细信息以连接到 Vertica。
import verticapy as vp
# 创建新连接
vp.new_connection({"host": "<Verticahost>",
"port": "5433",
"database": "<Verticadbname>",
"password": <password>,
"user": "dbadmin"},
name = "<Verticauser>")
# 连接到数据库
vp.connect("MyVerticaConnection")
- 创建一个新 schema:
- 使用以下命令将 filmtv_movies 数据集加载到 Vertica,其中需要传入下载数据集的路径、表名和 schema 名称:
使用 ETL 工具¶
您可以使用任何 ETL 工具将示例数据集加载到 Vertica。以下是使用 DBVisualizer 将数据加载到 Vertica 的步骤。您可以选择使用任何 ETL 工具。
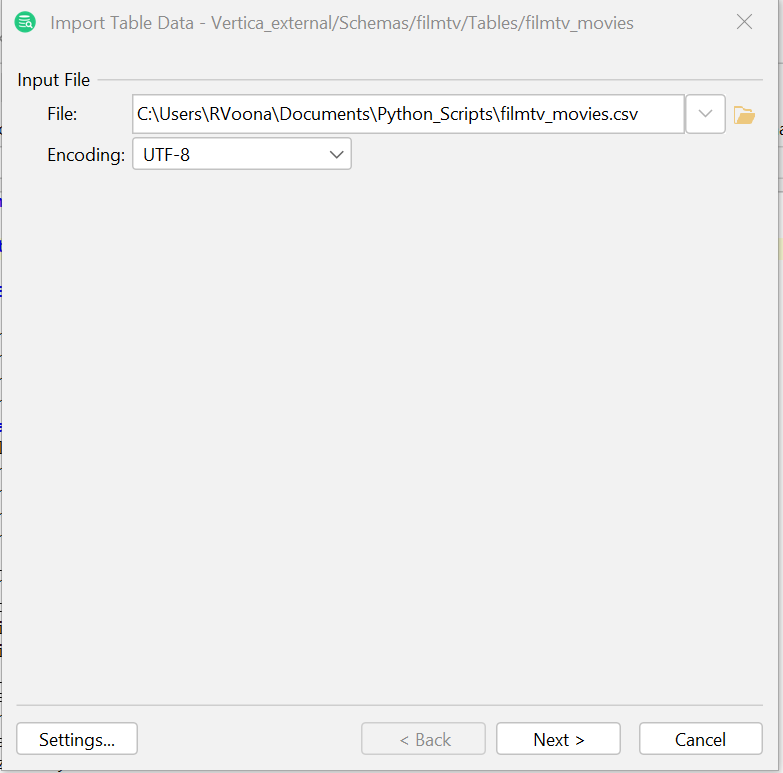
- 在"导入表数据"(Import Table Data)窗口中,选择下载的 filmtv_movies 数据集的位置,然后点击 Next(下一步)。
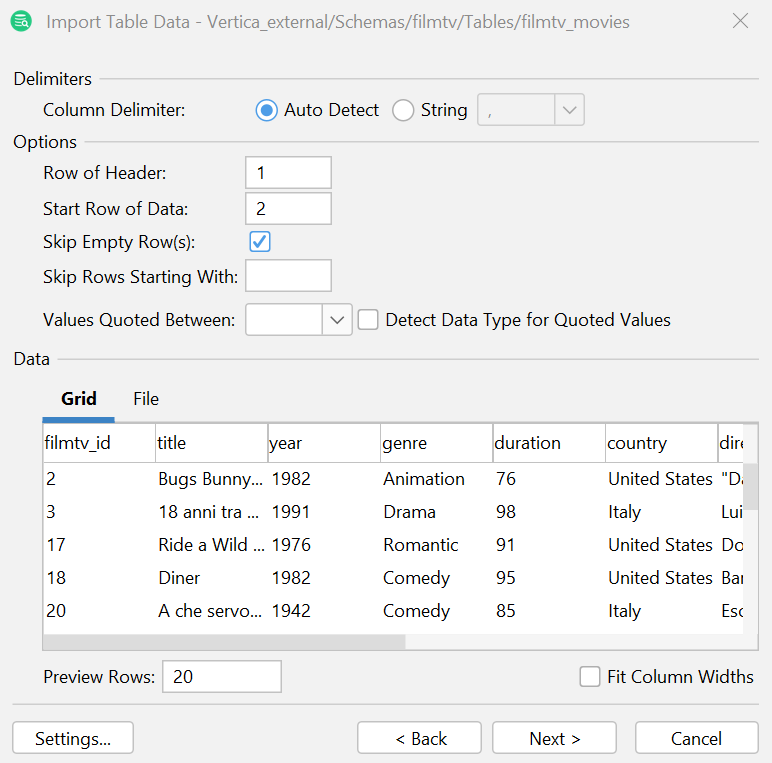
- 在"列分隔符"(Column delimiter)部分,选择 Auto Detect(自动检测),并在"选项"(Options)部分提供如下所示的值,然后点击 Next(下一步)。
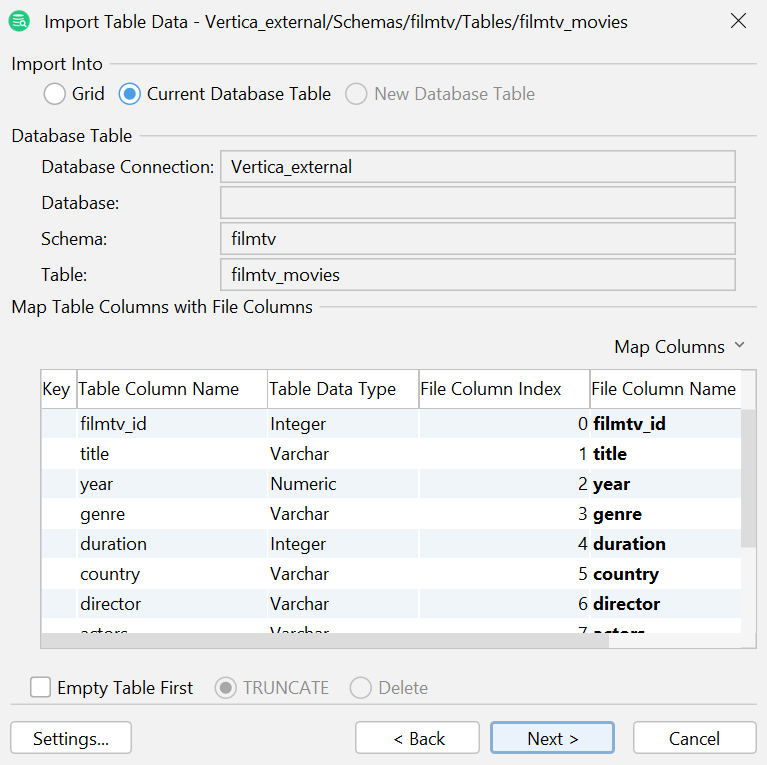
- 通过在数据预览部分进行验证,确保数据类型已正确指示,然后点击 Next(下一步)。
-
验证数据将要导入到的表和 schema 名称,然后点击 Next(下一步)。
-
点击 Import(导入)以将数据集导入到 filmtv_movies 表中。
-
导入完成后,关闭"导入表"(Import table)窗口,并验证数据是否已正确导入 Vertica 的表中。
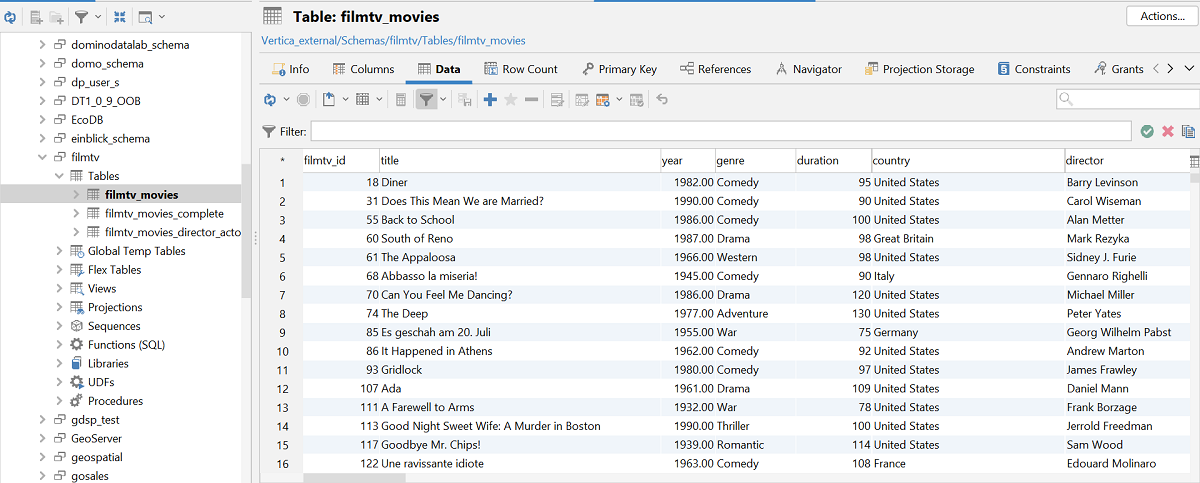
有关更多信息,请参阅 Importing Table Data,了解将 CSV 数据加载到新表或现有表中的步骤。
在 Saagie 中创建作业¶
您可以使用 Saagie 中的"作业"(Jobs)页面连接到 Vertica。让我们为数据初始化、数据探索与准备、以及数据建模(评估电影质量并创建相似电影的聚类)创建不同的作业,并使用这些作业创建管道。
- 使用 Saagie 提供的链接和凭据登录到 Saagie 云实例。
- Saagie 平台打开。它包含 Projects(项目)、Monitoring(监控)和 Catalog(目录)模块。
您可以点击 Projects 模块查看所有项目(All projects)。在"所有项目"页面中,您可以查看所有现有项目并创建新项目。
- 这里我们有一个 Vertica 项目。打开它,您将在左侧窗格中看到相关的 Jobs(作业)、Pipelines(管道)、Apps(应用程序)、Storage(存储)、Environment variables(环境变量)、External connections(外部连接)和 Docker credentials(Docker 凭据)。
- 在创建作业之前,您需要创建一个 Python 文件,其中包含您希望作业执行的操作。创建一个包含代码的 Python 文件,以便使用 VerticaPy Python 库连接到 Vertica 数据库。
初始化¶
- 创建一个 Python 文件,其中包含用于使用 VerticaPy 连接的 Vertica 数据库的详细信息。连接后,将已加载到 Vertica 中的 filmtv_movies 数据集表分配给一个 vDataFrame 对象(filmtv_movies),然后显示 Vertica 数据库中的数据。我们使用环境变量来存储数据库的详细信息,请参阅本文档中的"在 Saagie 中创建环境变量"一节。
import verticapy as vp
import os
vp.new_connection({"host":os.environ["host"],"port":"5433","database":os.environ["database"],"password": os.environ["pwd"],"user":os.environ["user"]},name="Vertica_Connection")
vp.connect("Vertica_Connection")
from verticapy import vDataFrame
film=os.environ["filmtv"]
filmtv_movies=vDataFrame(input_relation=film)
print(filmtv_movies.head(10))
- 要创建作业,请点击 Jobs(作业)> New job(新建作业)。
提供作业名称并添加描述,点击 Continue(继续)。
- 选择您的作业技术。点击 Continue(继续)。
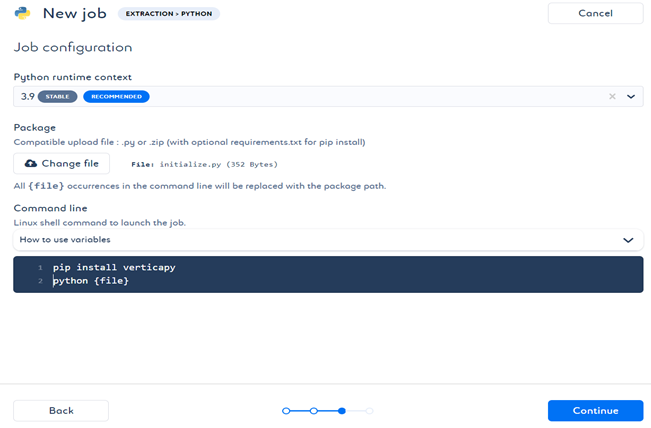
- 选择 Python 版本,然后您可以上传已创建的 Python 文件。
输入 shell 命令 pip install verticapy 和 python {file},如下所示。此处的 file 表示您刚刚上传的文件。此命令将在环境中安装 VerticaPy 以连接到 Vertica。点击 Continue(继续)。
- 您可以根据需要管理资源、告警、运行类型、发布说明等。点击 Create Job(创建作业)。
-
作业现已创建,作业的概览页面将打开。点击 Run(运行)。
-
状态会依次显示为 queued(已排队)> running(正在运行)> succeeded(已成功)。
作业成功后,结果会显示在命令行中,根据 Python 代码显示数据集的前 10 行。
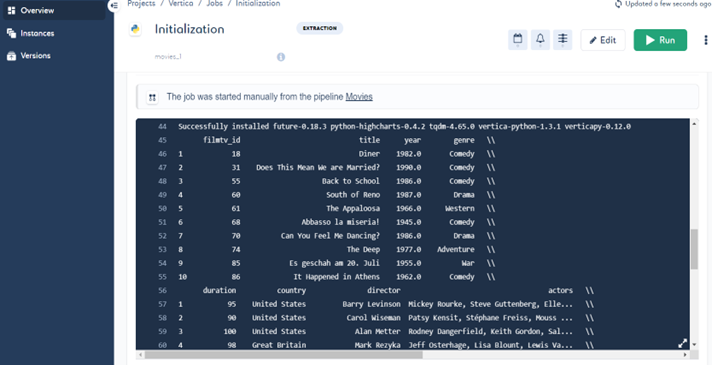
注意:您可以在本文档的"在 Saagie 中创建应用程序"一节中查看 Python 代码中每一行的解释。
有关更多信息,请参阅 Creating a Connection。
数据探索与准备¶
- 让我们再次创建一个 Python 文件,用于探索和准备数据:使用不同的 VerticaPy 函数识别顶级演员和导演,使用 min-max 方法归一化数据,量化演员和导演的知名度。最后,由于我们执行了许多操作,将 vDataFrame 导出为 Vertica 数据库中的表会很有帮助,我们将更改环境变量的值为刚导出的新表名,以便下一个作业使用这个新表的数据。
由于我们使用这些作业来创建管道,数据应在管道中链接的各个作业之间流动。因此,我们将把在每个作业中探索和准备的数据帧作为表上传到 Vertica 数据库,然后在下一个作业中将该表数据作为数据帧进行检索。
import verticapy as vp
import os
vp.new_connection({"host":os.environ["host"],"port":"5433","database":os.environ["database"],"password": os.environ["pwd"],"user":os.environ["user"]},name="Vertica_Connection")
vp.connect("Vertica_Connection")
from verticapy import vDataFrame
film=os.environ["filmtv"]
filmtv_movies=vDataFrame(input_relation=film)
filmtv_movies.describe(method = 'categorical', unique = True)
filmtv_movies.drop(['description','notes'])
filmtv_movies.sort({"avg_vote" : "desc"})
filmtv_movies.search(conditions = [filmtv_movies["votes"] > 10],order_by = {"avg_vote" : "desc" })
for i in range(1, 5):
filmtv_movies2 = vDataFrame(input_relation = '"filmtv"."filmtv_movies"')
filmtv_movies2.regexp(column = "actors",
method = "substr",
pattern = '[^,]+',
occurrence = i,
name = "actor")
if i == 1:
filmtv_movies = filmtv_movies2.copy()
else:
filmtv_movies = filmtv_movies.append(filmtv_movies2)
filmtv_movies["actor"].describe()
import verticapy.stats as st
actors_stats = filmtv_movies.groupby(columns = ["actor"],
expr = [st.sum(filmtv_movies["votes"])._as("notoriety_actors"),
st.count(filmtv_movies["actors"])._as("castings_actors")])
actors_stats["actor"].dropna()
actors_stats["notoriety_actors"].normalize(method = 'minmax')
print(actors_stats.search(order_by = {"notoriety_actors" : "desc","castings_actors" : "desc"}).head(10))
director_stats = filmtv_movies.groupby(columns = ["director"],
expr = [st.sum(filmtv_movies["votes"])._as("notoriety_director"),
st.count(filmtv_movies["director"])._as("castings_director")])
director_stats["notoriety_director"].normalize(method = 'minmax')
print(director_stats.search(order_by = {"notoriety_director" : "desc","castings_director" : "desc" }).head(10))
filmtv_movies_director = filmtv_movies.join(
director_stats,
on = {'director': 'director'},
how = "left",
expr1 = ["*"],
expr2 = ["notoriety_director",
"castings_director"])
filmtv_movies_director_actors = filmtv_movies_director.join(
actors_stats,
on = {'actor': 'actor'},
how = "left",
expr1 = ["*"],
expr2 = ["notoriety_actors",
"castings_actors" ])
print(filmtv_movies_director_actors.head(5))
vp.drop('"filmtv_saagie"."filmtv_movies_director_actors"', relation_type = "table")
filmtv_movies_director_actors.to_db(name = '"filmtv_saagie"."filmtv_movies_director_actors"',relation_type = "table",inplace = True)
var_file = "/workdir/output-vars.properties"
with open(var_file, "a") as file:
file.write(f"""filmtv = '"filmtv_saagie"."filmtv_movies_director_actors"' """)
- 我们将按照相同的步骤,通过上传此 Python 文件来创建新作业。
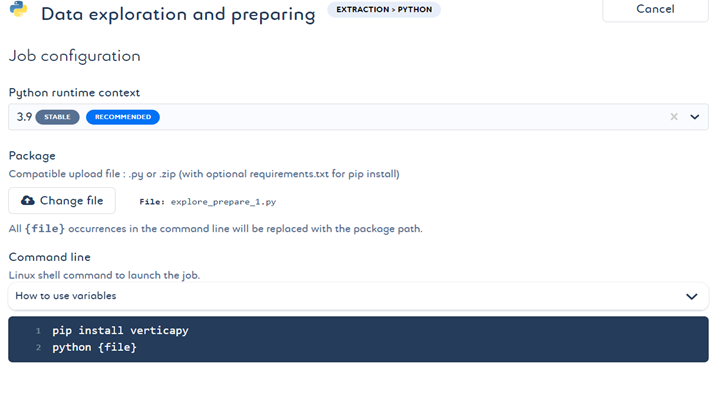
-
当作业通过管道运行时,根据代码在命令行中显示结果。
-
让我们再创建一个作业,用于使用不同的 Python 文件准备数据,其中包括对多个字段进行分类、归一化数值数据、创建虚拟变量以及填充缺失值,然后将 vDataFrame 导出为 Vertica 数据库中的表。我们将更改环境变量的值为刚上传的新表名,以便下一个作业使用这个新表的数据。
import verticapy as vp
import os
vp.new_connection({"host":os.environ["host"],"port":"5433","database":os.environ["database"],"password": os.environ["pwd"],"user":os.environ["user"]},name="Vertica_Connection")
vp.connect("Vertica_Connection")
from verticapy import vDataFrame
film=os.environ["filmtv"]
filmtv_movies_director_actors=vDataFrame(input_relation=film)
import verticapy.stats as st
filmtv_movies_complete = filmtv_movies_director_actors.groupby(
columns = ["filmtv_id",
"title",
"year",
"genre",
"country",
"avg_vote",
"votes",
"duration",
"director",
"notoriety_director",
"castings_director"],
expr = [st.sum(filmtv_movies_director_actors["notoriety_actors"])._as("notoriety_actors"),st.sum(filmtv_movies_director_actors["castings_actors"])._as("castings_actors")])
print(filmtv_movies_complete.describe(method = "all"))
filmtv_movies_complete.case_when('period',filmtv_movies_complete["year"] < 1990,'Old',filmtv_movies_complete["year"] >= 2000,'Recent', '90s')
print(filmtv_movies_complete.head(5))
print(filmtv_movies_complete.groupby(columns = ["country"],expr = ["COUNT(*)"]).sort({"count" : "desc"}).head(10))
from verticapy import str_sql
# 语言离散化
Arabic_Middle_Est = ["Arab", "Iran", "Turkey", "Egypt", "Tunisia",
"Lebanon", "Palestine", "Morocco", "Iraq",
"Sudan", "Algeria", "Yemen", "Afghanistan",
"Azerbaijan", "Kazakhstan", "Kyrgyzstan",
"Kurdistan", "Syria", "Uzbekistan"]
Chinese_Japan_Asian = ["Japan", "Hong Kong", "China", "South Korea",
"Thailand", "Philippines", "Taiwan", "Indonesia",
"Singapore", "Malaysia", "Vietnam", "Laos", "Cambodia",
"Bhutan"]
Indian = ["India", "Pakistan", "Nepal", "Sri Lanka", "Bangladesh"]
Hebrew = ["Israel"]
Spanish_Portuguese = ["Spain", "Portugal", "Mexico", "Brasil", "Chile",
"Argentina", "Colombia", "Cuba", "Venezuela", "Peru",
"Uruguay", "Dominican Republic", "Ecuador", "Guatemala",
"Costa Rica", "Paraguay", "Bolivia"]
English = ["United States", "England", "Great Britain", "Ireland",
"Australia", "New Zealand", "South Africa"]
French = ["France", "Canada", "Belgium", "Switzerland", "Luxembourg"]
Italian = ["Italy"]
German_North_Europe = ["German", "Austria", "Holland", "Netherlands", "Denmark",
"Norway", "Iceland", "Finland", "Sweden", "Greenland"]
Russian_Est_Europe = ["Russia", "Soviet Union", "Yugoslavia", "Czechoslovakia",
"Poland", "Bulgaria", "Croatia", "Czech Republic", "Serbia",
"Ukraine", "Slovenia", "Lithuania", "Latvia", "Estonia",
"Bosnia and Herzegovina", "Georgia"]
Grec_Balkan = ["Greece", "Macedonia", "Cyprus", "Romania", "Armenia", "Hungary",
"Albania", "Malta"]
# 创建新特征
filmtv_movies_complete.case_when('language_area',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Arabic_Middle_Est))), 'Arabic_Middle_Est',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Chinese_Japan_Asian))), 'Chinese_Japan_Asian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Indian))), 'Indian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Hebrew))), 'Hebrew',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Spanish_Portuguese))), 'Spanish_Portuguese',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(English))), 'English',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(French))), 'French',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Italian))), 'Italian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(German_North_Europe))), 'German_North_Europe',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Russian_Est_Europe))), 'Russian_Est_Europe',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Grec_Balkan))), 'Grec_Balkan',
'Others')
filmtv_movies_complete.case_when(
'Category',
str_sql("REGEXP_LIKE(Genre, 'Drama|Noir')"), 'Drama',
str_sql("REGEXP_LIKE(Genre, 'Comedy|Grotesque')"), 'Comedy',
str_sql("REGEXP_LIKE(Genre, 'Fantasy|Super-hero')"), 'Fantasy',
str_sql("REGEXP_LIKE(Genre, 'Romantic|Sperimental|Mélo')"), 'Romantic',
str_sql("REGEXP_LIKE(Genre, 'Thriller|Crime|Gangster')"), 'Thriller',
str_sql("REGEXP_LIKE(Genre, 'Action|Western|War|Spy')"), 'Action',
str_sql("REGEXP_LIKE(Genre, 'Adventure')"), 'Adventure',
str_sql("REGEXP_LIKE(Genre, 'Animation')"), 'Animation',
str_sql("REGEXP_LIKE(Genre, 'Horror')"), 'Horror',
'Others')
print(filmtv_movies_complete.head(5))
filmtv_movies_complete.drop(columns = ["genre"])
print(filmtv_movies_complete.count_percent())
filmtv_movies_complete["notoriety_actors"].fillna(method = "median",
by = ["director",
"Category"])
filmtv_movies_complete["castings_actors"].fillna(method = "median",
by = ["director",
"Category"])
filmtv_movies_complete.dropna()
print(filmtv_movies_complete.count_percent())
filmtv_movies_complete.normalize(method = "minmax",
columns = ['votes',
'duration',
'notoriety_director',
'castings_director',
'notoriety_actors',
'castings_actors'])
for elem in ['category', 'period', 'language_area']:
filmtv_movies_complete[elem].get_dummies(drop_first = True)
print(filmtv_movies_complete.head(5))
vp.drop('"filmtv_saagie"."filmtv_movies_complete"', relation_type = "table")
filmtv_movies_complete.to_db(name = '"filmtv_saagie"."filmtv_movies_complete"',
relation_type = "table",
inplace = True)
vp.drop('"filmtv_saagie"."filmtv_movies_mco"', relation_type ="view")
filmtv_movies_complete.to_db(name = '"filmtv_saagie"."filmtv_movies_mco"',
relation_type = "view",
db_filter = "votes > 0.02")
var_file = "/workdir/output-vars.properties"
with open(var_file, "a") as file:
file.write(f"""filmtv = '"filmtv_saagie"."filmtv_movies_complete"' """)
- 上传上述 Python 文件并按图示创建作业。
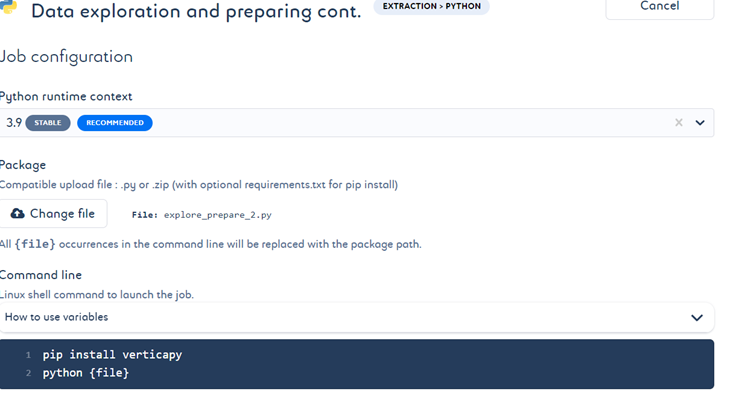
- 当作业通过管道运行时,根据您的代码在执行不同数据准备操作后,命令行中会显示相应的数据。
机器学习:创建线性回归模型¶
- 让我们创建一个 Python 文件,使用上一个作业中上传到 Vertica 数据库的数据创建线性回归模型,训练模型,生成模型报告,并评估顶级电影。
之后,我们将把 vDataFrame 导出为 Vertica 数据库中的表,并更改环境变量的值为导出的新表名。
import verticapy as vp
import os
vp.new_connection({"host":os.environ["host"],"port":"5433","database":os.environ["database"],"password": os.environ["pwd"],"user":os.environ["user"]},name="Vertica_Connection")
vp.connect("Vertica_Connection")
from verticapy import vDataFrame
film=os.environ["filmtv"]
filmtv_movies_complete=vDataFrame(input_relation=film)
from verticapy.learn.linear_model import LinearRegression
predictors = filmtv_movies_complete.get_columns(
exclude_columns = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"])
model = LinearRegression("filmtv_movies_lr",
max_iter = 1000,
solver = "BFGS")
model.fit('"filmtv_saagie"."filmtv_movies_mco"', predictors, "avg_vote")
print(model.report())
model.predict(filmtv_movies_complete,name = "unbiased_vote")
import verticapy.stats as st
filmtv_movies_complete["unbiased_vote"] = st.case_when(filmtv_movies_complete["unbiased_vote"] > 10, 10,
filmtv_movies_complete["unbiased_vote"] < 0, 0,
filmtv_movies_complete["unbiased_vote"])
print(filmtv_movies_complete.search(usecols = ['filmtv_id',
'title',
'year',
'country',
'avg_vote',
'unbiased_vote',
'votes',
'duration',
'director',
'notoriety_director',
'castings_director',
'notoriety_actors',
'castings_actors',
'period',
'language_area'],
order_by = {"unbiased_vote" : "desc",
"avg_vote" : "desc"}).head(10))
vp.drop('"filmtv_saagie"."filmtv_movies_complete_reg"', relation_type = "table")
filmtv_movies_complete.to_db(name = '"filmtv_saagie"."filmtv_movies_complete_reg"',
relation_type = "table",
inplace = True)
var_file = "/workdir/output-vars.properties"
with open(var_file, "a") as file:
file.write(f"""filmtv = '"filmtv_saagie"."filmtv_movies_complete_reg"' """)
- 现在您可以使用上述 Python 文件创建用于创建回归模型的作业。
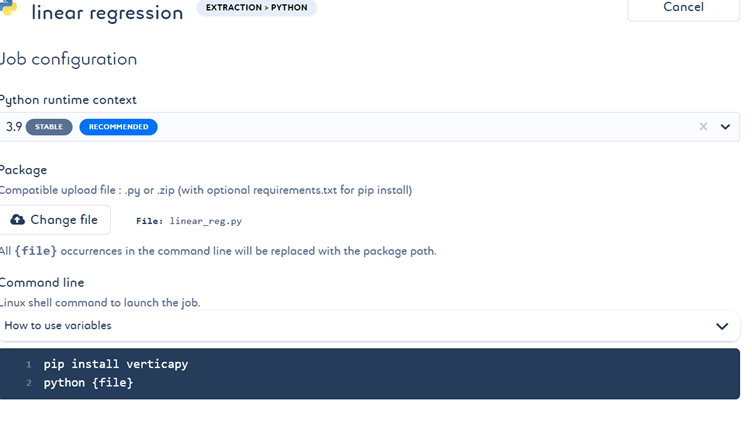
- 通过管道运行作业后,命令行中会显示模型报告,并根据代码显示数据中排名前 10 的电影。
机器学习:创建电影聚类¶
- 最后,我们将创建一个 Python 文件,使用在执行线性回归后上传到 Vertica 数据库的数据创建 k-means 聚类模型,以创建相似电影的聚类。
import verticapy as vp
import os
vp.new_connection({"host":os.environ["host"],"port":"5433","database":os.environ["database"],"password": os.environ["pwd"],"user":os.environ["user"]},name="Vertica_Connection")
vp.connect("Vertica_Connection")
from verticapy import vDataFrame
film=os.environ["filmtv"]
filmtv_movies_complete_reg=vDataFrame(input_relation=film)
filmtv_movies_complete_reg["unbiased_vote"].normalize(method = "minmax")
predictors = filmtv_movies_complete_reg.get_columns(
exclude_columns = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category",
"filmtv_id"])
from verticapy.learn.cluster import KMeans
model_kmeans = KMeans("filmtv_movies_clustering", n_cluster = 17)
model_kmeans.fit(filmtv_movies_complete_reg, predictors)
model_kmeans.cluster_centers_
model_kmeans.predict(filmtv_movies_complete_reg,name = "movies_cluster")
print(filmtv_movies_complete_reg.head(5))
print(filmtv_movies_complete_reg.search(filmtv_movies_complete_reg["movies_cluster"] == 5,
usecols = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"]).head(10))
print(filmtv_movies_complete_reg.search(filmtv_movies_complete_reg["movies_cluster"] == 6,
usecols = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"]).head(10))
- 现在让我们使用上述 Python 文件创建作业并创建聚类。
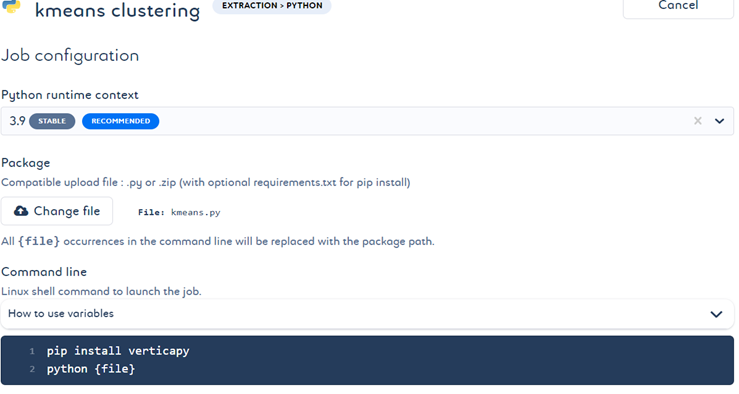
- 最后,当此作业通过管道运行时,结果会根据我们的代码显示数据的不同聚类。
以下是我们创建的 5 个作业,它们将用于构建一个提供端到端机器学习解决方案的管道。
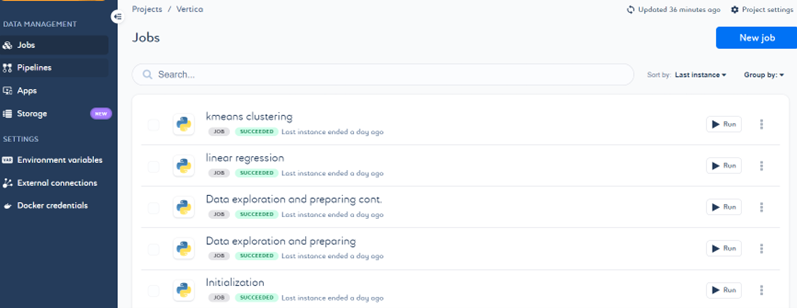
在 Saagie 中创建管道¶
- 要创建管道,请点击 Pipelines(管道)> New pipeline(新建管道)。

- 提供管道名称。通过添加之前创建的作业来构建您的管道。
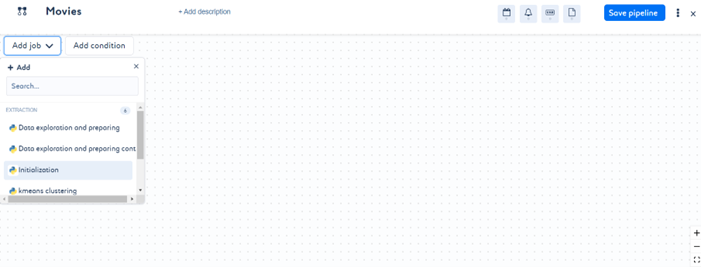
- 选择 Add job(添加作业),然后从列表中选择要添加到管道中的作业。包含基本信息(如名称、技术和作业类别)的作业将显示在图中。
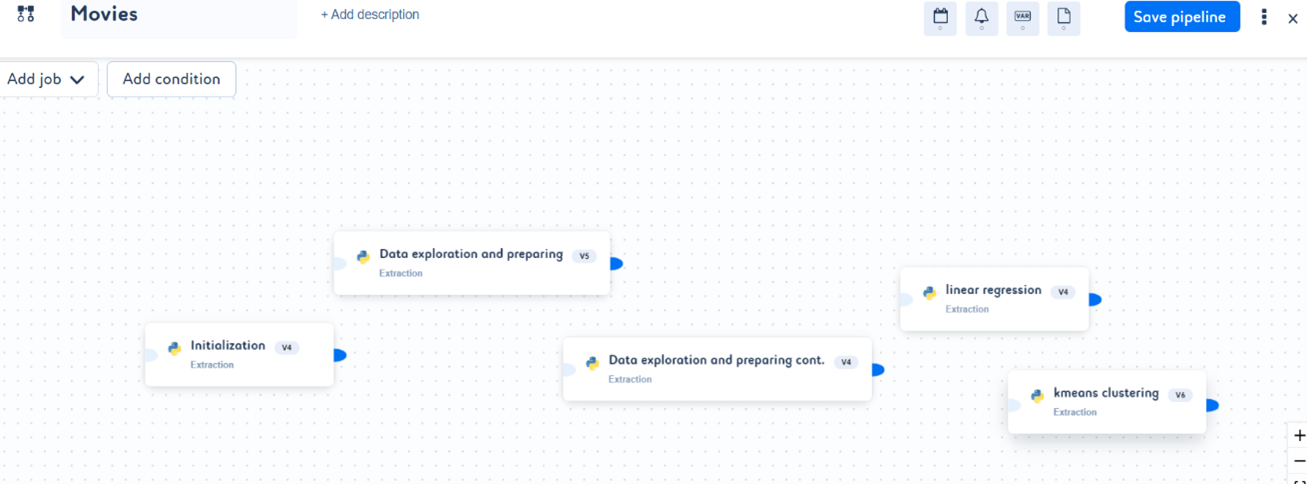
- 按照您的需求按顺序链接作业以创建管道。点击 Save pipeline(保存管道)。
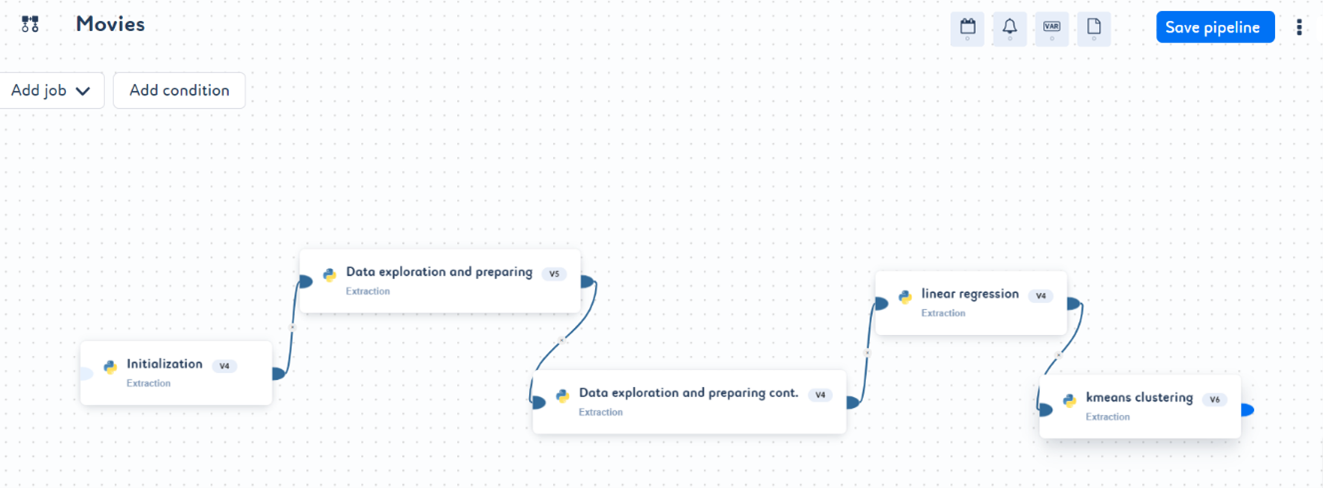
- 管道现已创建。点击 Run(运行)。
运行成功后,管道中连接的作业将被执行。您可以通过点击作业来查看每个作业的日志。
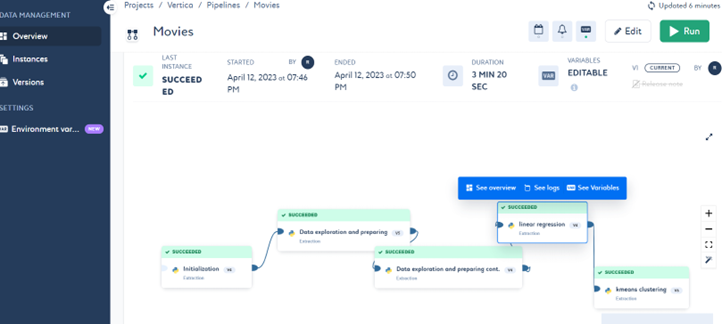
-
您可以通过点击作业来查看每个作业日志中的结果。
-
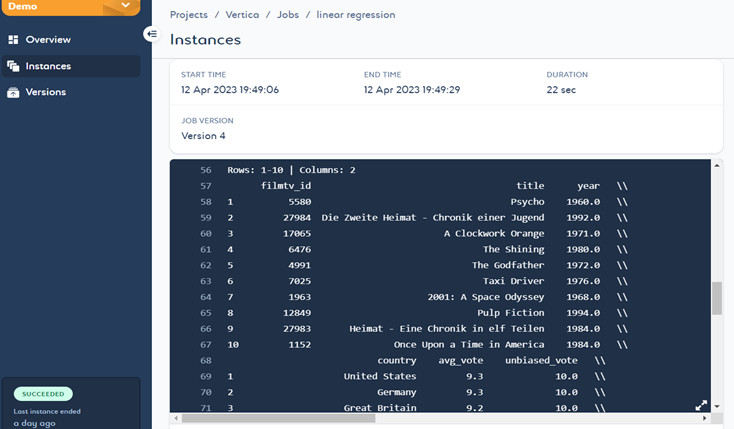
点击线性回归作业的 see logs(查看日志),将打开一个新窗口,其中显示获取顶级电影的方案结果。我们的结果更加一致,您可以看到 Psycho、Pulp Fiction 和 The Godfather 等电影位居顶级电影之列。
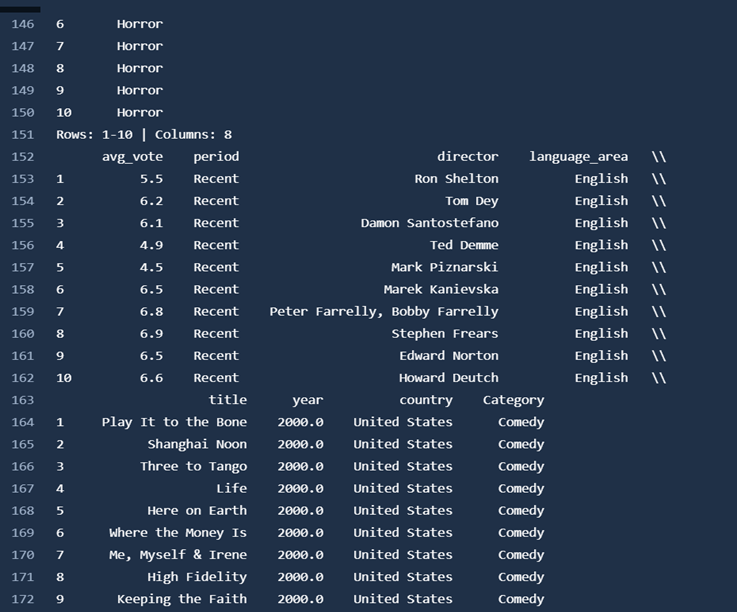
点击 k-means 作业的 see logs(查看日志),将打开一个新窗口,其中显示相似电影的聚类结果。您可以从结果中看到,聚类 5 包含剧情类(drama)电影,聚类 6 包含喜剧类(comedy)电影,其他聚类也包含不同的类别。这表明每个聚类由相似电影组成。
该管道现在提供了评估电影质量并创建相似电影聚类的端到端机器学习解决方案。
在 Saagie 中创建环境变量¶
- 点击项目内的 Environment variables(环境变量)页面。页面将打开,显示我们在作业中创建和使用的现有环境变量列表。
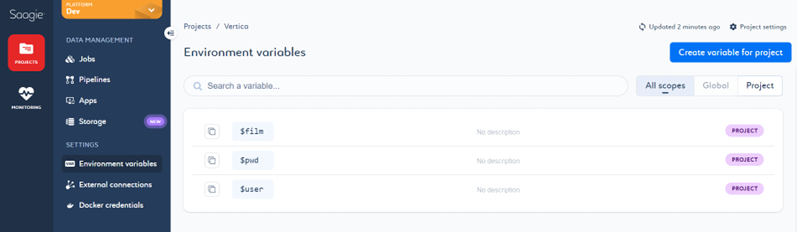
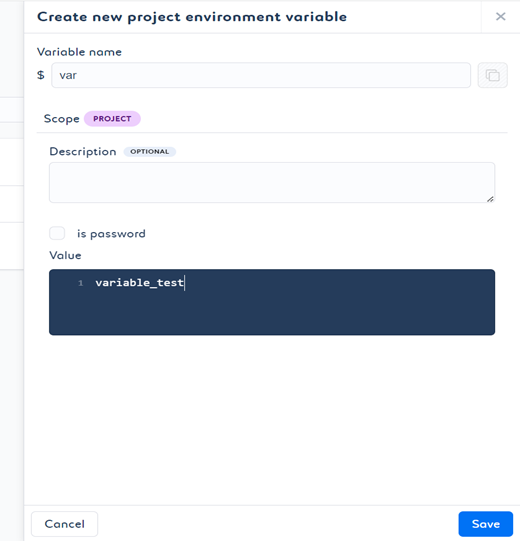
- 要创建新变量,请点击 Create variable for project(为项目创建变量)。输入所需信息并点击 Save(保存)。
如果您的值是密码且希望隐藏,可以选择 is password(是密码)选项。
在管道内¶
在此级别创建的环境变量可以在所选管道内访问,并且还可以访问项目和全局环境变量。您始终可以通过点击变量来编辑管道的变量。
- 点击管道内的 Environment variables(环境变量)。页面将打开,显示作用域为项目和管道的现有环境变量列表。我们创建了这些变量来存储数据库详细信息、表名,并在作业中使用它们。
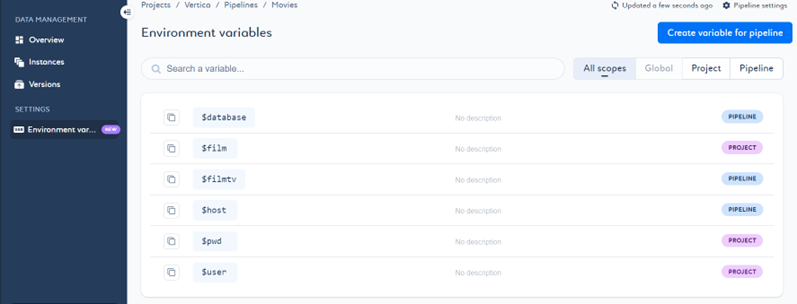
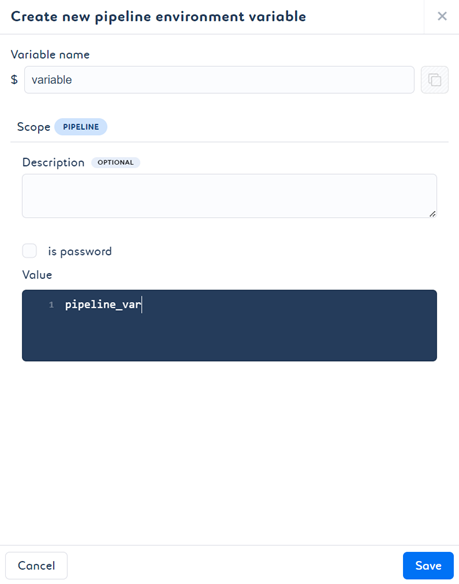
- 要在管道中创建新变量,请点击 Create variable for pipeline(为管道创建变量)。输入所需信息并点击 Save(保存)。
如果您的值是密码且希望隐藏,可以选择 is password(是密码)选项。
在 Saagie 中创建应用程序¶
Saagie 的应用程序(Apps)环境允许您安装 Jupyter Notebook 并执行数据科学操作。
- 要创建应用程序,请点击 Apps(应用程序)> New App(新建应用程序)以安装新应用程序。
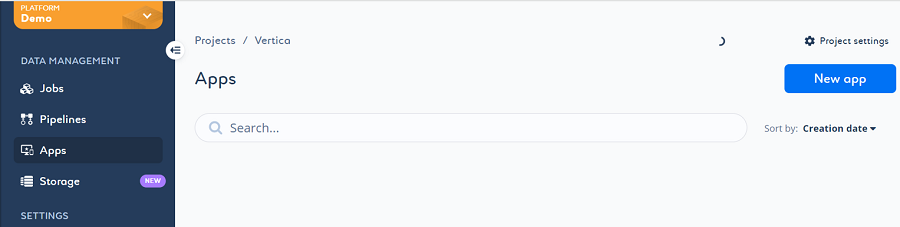
- "从目录安装应用程序"(Install App from the Catalog)页面打开。从列表中选择 Jupyter Notebook,然后点击 Install(安装)。
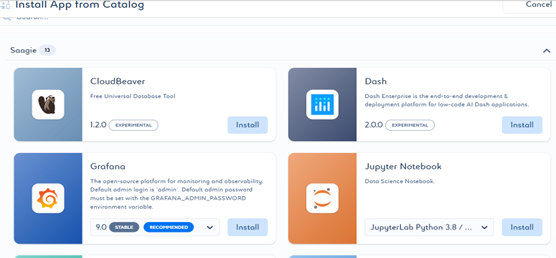
- 应用程序安装完成后,概览页面将出现,状态显示为 Started(已启动)。如果您想停止应用程序,请点击 Stop(停止)。
启动 Jupyter Notebook¶
- 要启动 Jupyter Notebook,请点击 Open Notebook(打开笔记本)。
- 在 Notebook 下选择 Python 版本以创建新笔记本。
- 要连接到 Vertica,您需要在环境中安装 VerticaPy。您可以通过在创建的笔记本中运行带有
pip install verticapy的单元格来完成此操作。
- 运行单元格后,点击 Kernel(内核)> Restart(重启)以重启内核。
初始化¶
- 首先,您需要连接到 Vertica,此连接将在笔记本的其余部分中使用。
import verticapy as vp
# 创建新连接
vp.new_connection({"host": "<Verticahost>",
"port": "5433",
"database": "<Verticadbname>", "password": <password>,
"user": "dbadmin"},
name = "<Verticauser>")
# 连接到数据库
vp.connect("MyVerticaConnection")
- 从 filmtv schema 加载数据,并将数据分配给 vDataFrame 对象。要了解更多关于 vDataFrame 的信息,请参见 vDataFrame。
from verticapy import vDataFrame
filmtv_movies=vDataFrame(input_relation='"filmtv"."filmtv_movies"')
display(filmtv_movies)
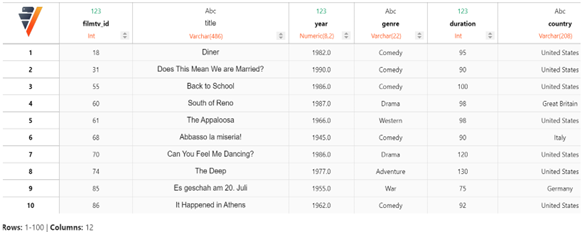
表已成功创建。
有关更多信息,请参阅 Creating a Connection。
数据探索与准备¶
VerticaPy 有许多帮助您了解数据集的功能。您可以获取每个特征的汇总数据。您可以使用以下 VerticaPy 函数获取数据类型、计数、top 值、唯一值等信息。
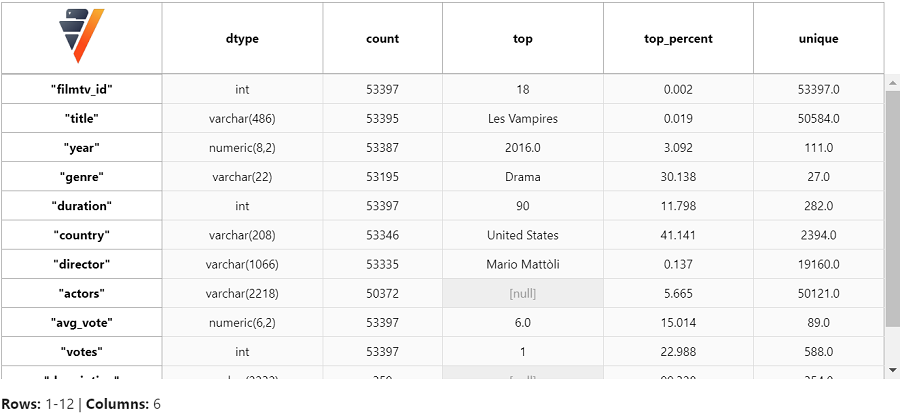
我们可以从数据集中删除 description 和 notes 列,因为这些字段在大部分数据中为空。
该数据集中有超过 50000 部电影,涵盖 27 种不同的类型。因此,让我们根据平均评分对数据进行排序。
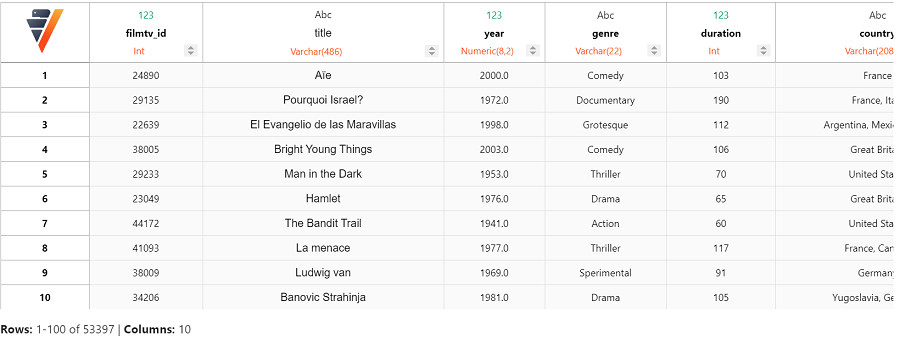
由于我们想要获得合理的平均评分,让我们只考虑至少有 10 票的顶级电影。
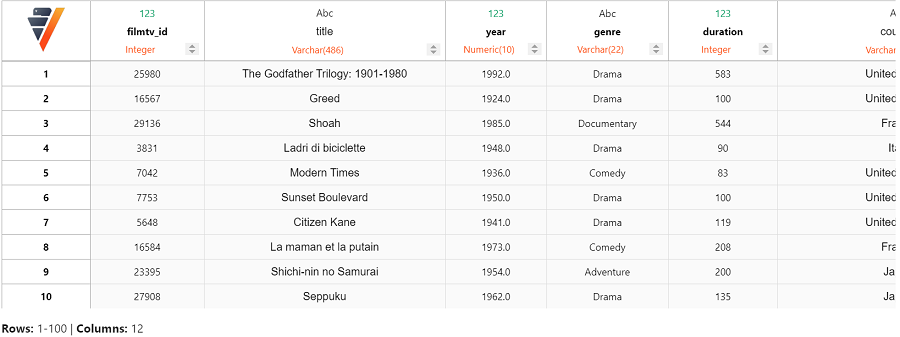
我们可以看到经典电影如 The Godfather 和 Greed 出现在顶级电影列表中。让我们使用线性回归模型平滑平均评分,使其更具代表性。
为了创建模型,我们可以使用投票数、类别、时长等特征,但我们选择使用电影的导演和主要演员。
我们可以使用正则表达式提取每部电影的五位主要演员。
for i in range(1, 5):
filmtv_movies2 = vDataFrame(input_relation = '"filmtv"."filmtv_movies"')
filmtv_movies2.regexp(column = "actors",
method = "substr",
pattern = '[^,]+',
occurrence = i,
name = "actor")
if i == 1:
filmtv_movies = filmtv_movies2.copy()
else:
filmtv_movies = filmtv_movies.append(filmtv_movies2)
filmtv_movies["actor"].describe()
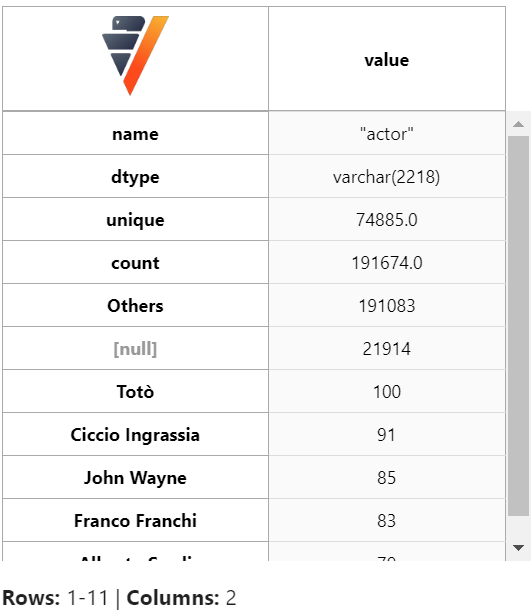
我们可以通过聚合数据来查找演员的数量和演员获得的投票数。然后我们可以使用 min-max 方法归一化数据,量化演员的知名度。
import verticapy.stats as st
actors_stats = filmtv_movies.groupby(columns = ["actor"],
expr = [st.sum(filmtv_movies["votes"])._as("notoriety_actors"),
st.count(filmtv_movies["actors"])._as("castings_actors")])
actors_stats["actor"].dropna()
actors_stats["notoriety_actors"].normalize(method = 'minmax')
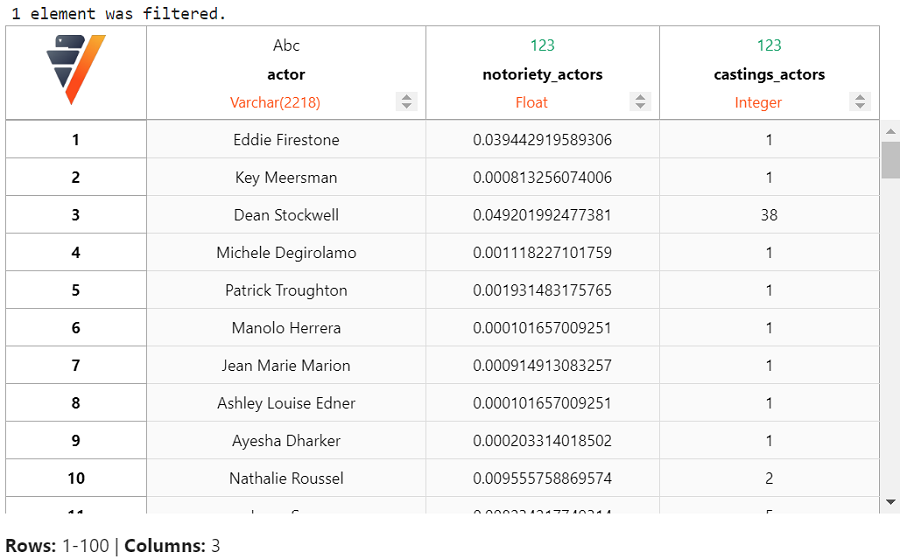
让我们查看知名度排名前十的演员。
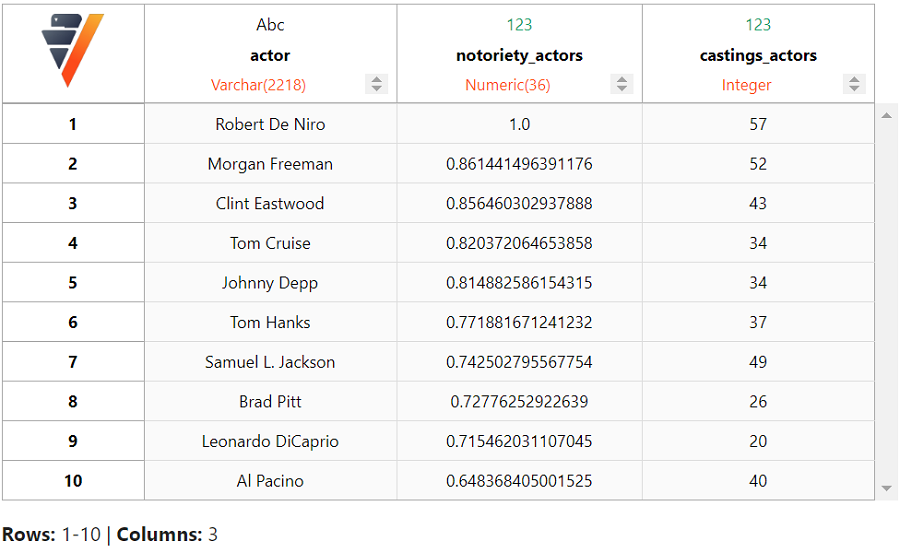
我们得到了非常受欢迎的演员列表,如 Robert De Niro、Morgan Freeman 和 Clint Eastwood 等出现在前十名中。
让我们对导演执行相同的操作。
director_stats = filmtv_movies.groupby(columns = ["director"],
expr = [st.sum(filmtv_movies["votes"])._as("notoriety_director"),
st.count(filmtv_movies["director"])._as("castings_director")])
director_stats["notoriety_director"].normalize(method = 'minmax')
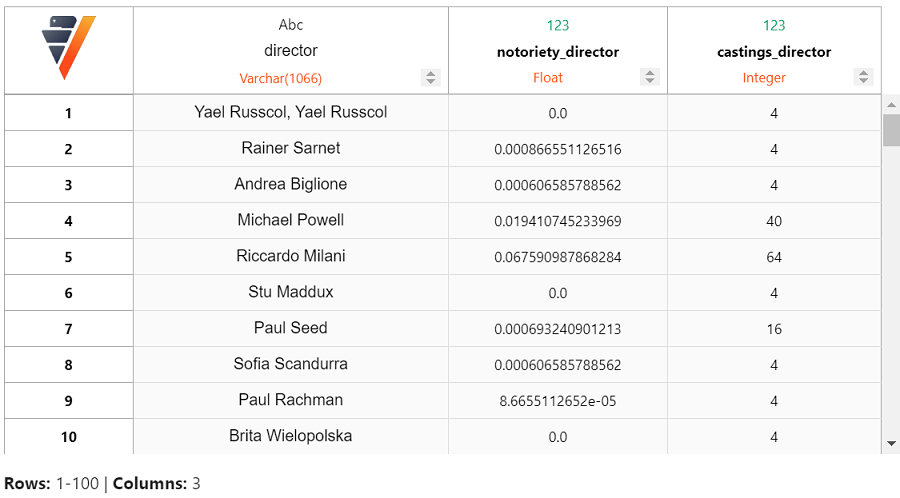
现在让我们查看排名前十的电影导演。
director_stats.search(order_by = {"notoriety_director" : "desc",
"castings_director" : "desc" }).head(10)
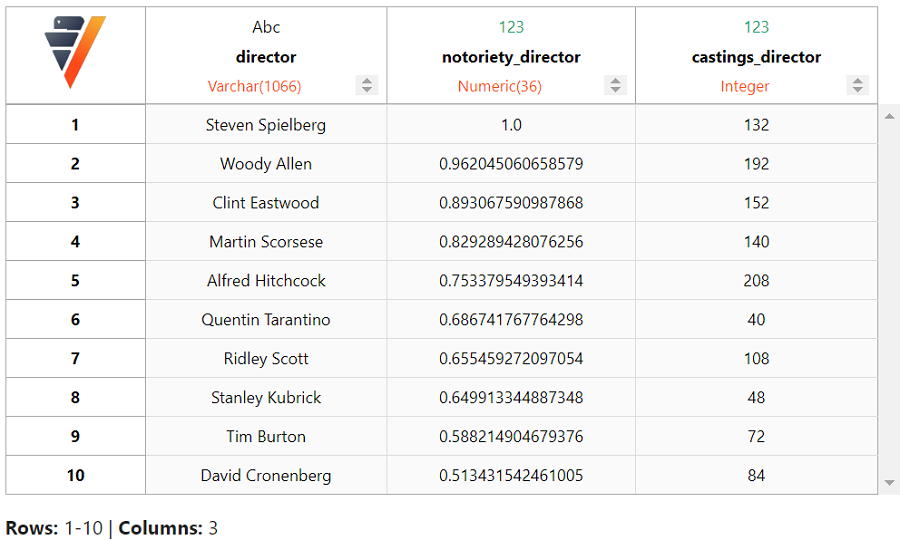
同样,我们得到了热门导演列表,如 Steven Spielberg、Woody Allen 和 Clint Eastwood。
让我们将演员和导演的知名度指标与主数据集进行连接。
filmtv_movies_director = filmtv_movies.join(
director_stats,
on = {'director': 'director'},
how = "left",
expr1 = ["*"],
expr2 = ["notoriety_director",
"castings_director"])
filmtv_movies_director_actors = filmtv_movies_director.join(
actors_stats,
on = {'actor': 'actor'},
how = "left",
expr1 = ["*"],
expr2 = ["notoriety_actors",
"castings_actors" ])
由于我们执行了许多操作,将 vDataFrame 保存为 Vertica 数据库中的表会很有帮助。
vp.drop('"filmtv"."filmtv_movies_director_actors"', relation_type = "table")
filmtv_movies_director_actors.to_db(name = '"filmtv"."filmtv_movies_director_actors"',
relation_type = "table",
inplace = True)
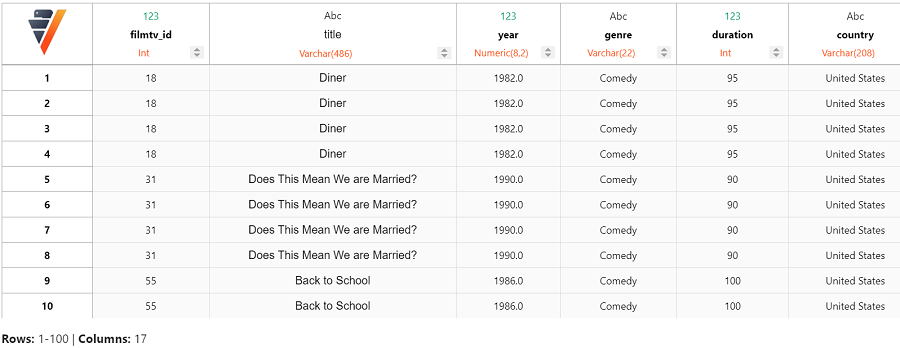
我们可以聚合数据以获取每部电影的指标。
filmtv_movies_complete = filmtv_movies_director_actors.groupby(
columns = ["filmtv_id",
"title",
"year",
"genre",
"country",
"avg_vote",
"votes",
"duration",
"director",
"notoriety_director",
"castings_director"],
expr = [st.sum(filmtv_movies_director_actors["notoriety_actors"])._as("notoriety_actors"),
st.sum(filmtv_movies_director_actors["castings_actors"])._as("castings_actors")])
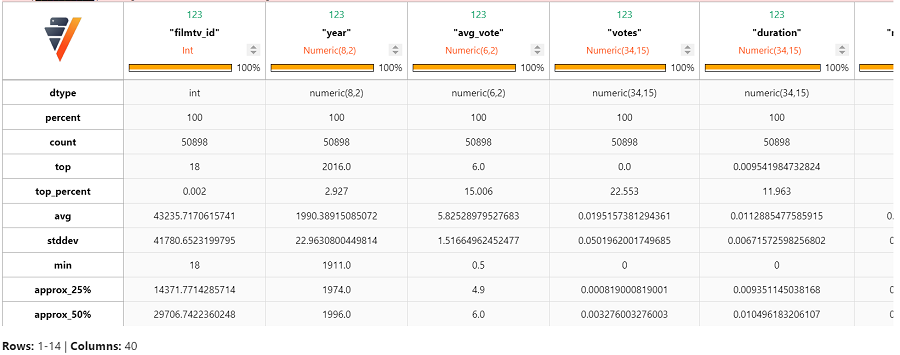
让我们使用以下 VerticaPy 函数计算数据集的一些统计信息,如最大值、最小值、标准差、数据类型、top 计数等。
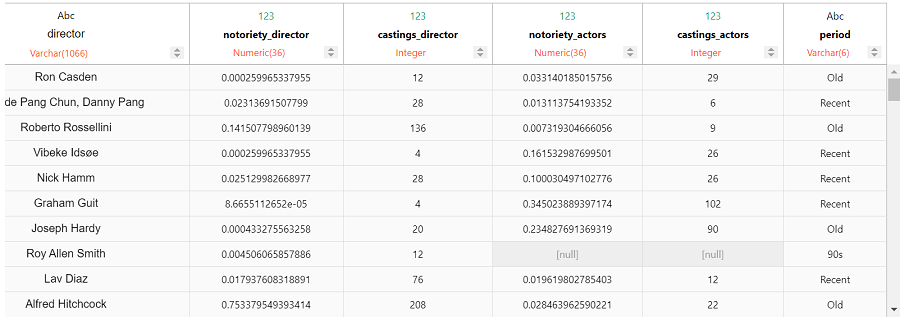
我们可以使用电影的上映年份创建三个类别:老电影(Old)、近期电影(Recent)和 90 年代电影(90s)。
filmtv_movies_complete.case_when('period',
filmtv_movies_complete["year"] < 1990, 'Old',
filmtv_movies_complete["year"] >= 2000, 'Recent', '90s')
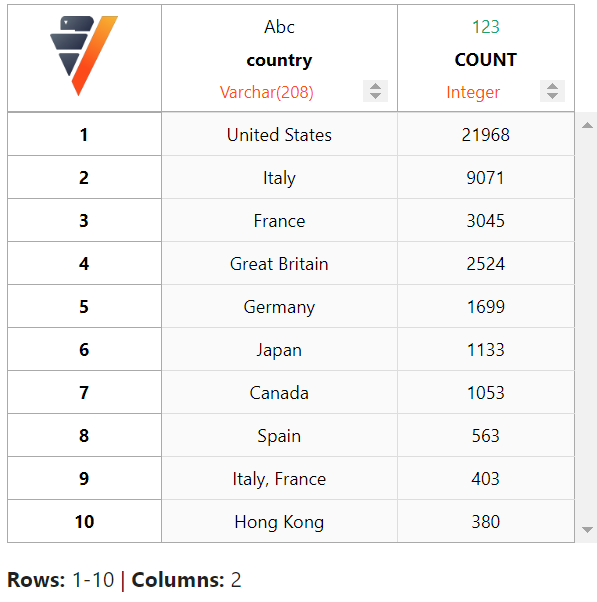
现在,让我们查看制作电影最多的国家。
filmtv_movies_complete.groupby(columns = ["country"],
expr = ["COUNT(*)"]).sort(
{"count" : "desc"}).head(10)
让我们对电影的语言进行离散化,创建语言分组,并添加一个新特征 language_area。
from verticapy import str_sql
# 语言离散化
Arabic_Middle_Est = ["Arab", "Iran", "Turkey", "Egypt", "Tunisia",
"Lebanon", "Palestine", "Morocco", "Iraq",
"Sudan", "Algeria", "Yemen", "Afghanistan",
"Azerbaijan", "Kazakhstan", "Kyrgyzstan",
"Kurdistan", "Syria", "Uzbekistan"]
Chinese_Japan_Asian = ["Japan", "Hong Kong", "China", "South Korea",
"Thailand", "Philippines", "Taiwan", "Indonesia",
"Singapore", "Malaysia", "Vietnam", "Laos", "Cambodia",
"Bhutan"]
Indian = ["India", "Pakistan", "Nepal", "Sri Lanka", "Bangladesh"]
Hebrew = ["Israel"]
Spanish_Portuguese = ["Spain", "Portugal", "Mexico", "Brasil", "Chile",
"Argentina", "Colombia", "Cuba", "Venezuela", "Peru",
"Uruguay", "Dominican Republic", "Ecuador", "Guatemala",
"Costa Rica", "Paraguay", "Bolivia"]
English = ["United States", "England", "Great Britain", "Ireland",
"Australia", "New Zealand", "South Africa"]
French = ["France", "Canada", "Belgium", "Switzerland", "Luxembourg"]
Italian = ["Italy"]
German_North_Europe = ["German", "Austria", "Holland", "Netherlands", "Denmark",
"Norway", "Iceland", "Finland", "Sweden", "Greenland"]
Russian_Est_Europe = ["Russia", "Soviet Union", "Yugoslavia", "Czechoslovakia",
"Poland", "Bulgaria", "Croatia", "Czech Republic", "Serbia",
"Ukraine", "Slovenia", "Lithuania", "Latvia", "Estonia",
"Bosnia and Herzegovina", "Georgia"]
Grec_Balkan = ["Greece", "Macedonia", "Cyprus", "Romania", "Armenia", "Hungary",
"Albania", "Malta"]
# 创建新特征
filmtv_movies_complete.case_when('language_area',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Arabic_Middle_Est))), 'Arabic_Middle_Est',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Chinese_Japan_Asian))), 'Chinese_Japan_Asian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Indian))), 'Indian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Hebrew))), 'Hebrew',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Spanish_Portuguese))), 'Spanish_Portuguese',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(English))), 'English',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(French))), 'French',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Italian))), 'Italian',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(German_North_Europe))), 'German_North_Europe',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Russian_Est_Europe))), 'Russian_Est_Europe',
str_sql("REGEXP_LIKE(Country, '{}')".format("|".join(Grec_Balkan))), 'Grec_Balkan',
'Others')
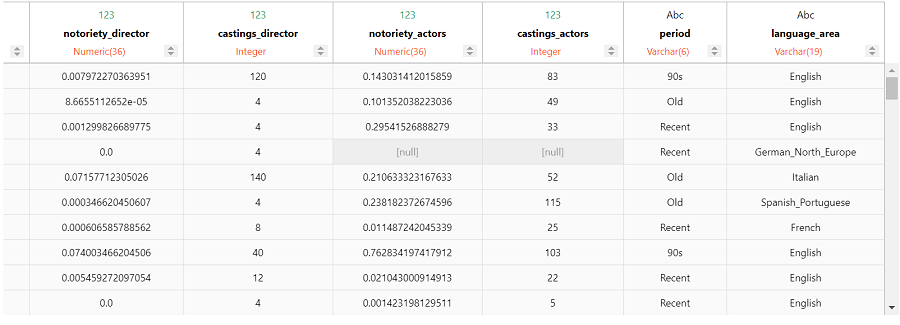
我们可以对电影类型的数据进行相同的分类处理。
filmtv_movies_complete.case_when(
'Category',
str_sql("REGEXP_LIKE(Genre, 'Drama|Noir')"), 'Drama',
str_sql("REGEXP_LIKE(Genre, 'Comedy|Grotesque')"), 'Comedy',
str_sql("REGEXP_LIKE(Genre, 'Fantasy|Super-hero')"), 'Fantasy',
str_sql("REGEXP_LIKE(Genre, 'Romantic|Sperimental|Mélo')"), 'Romantic',
str_sql("REGEXP_LIKE(Genre, 'Thriller|Crime|Gangster')"), 'Thriller',
str_sql("REGEXP_LIKE(Genre, 'Action|Western|War|Spy')"), 'Action',
str_sql("REGEXP_LIKE(Genre, 'Adventure')"), 'Adventure',
str_sql("REGEXP_LIKE(Genre, 'Animation')"), 'Animation',
str_sql("REGEXP_LIKE(Genre, 'Horror')"), 'Horror',
'Others')
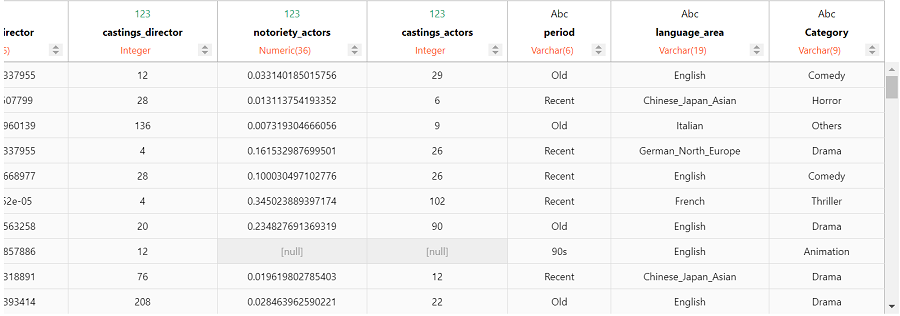
由于此时我们更关注类别(Category),可以删除 genre 列。
让我们检查缺失值。
在机器学习中,在使用数据集训练模型之前检查数据中是否有缺失数据非常重要。
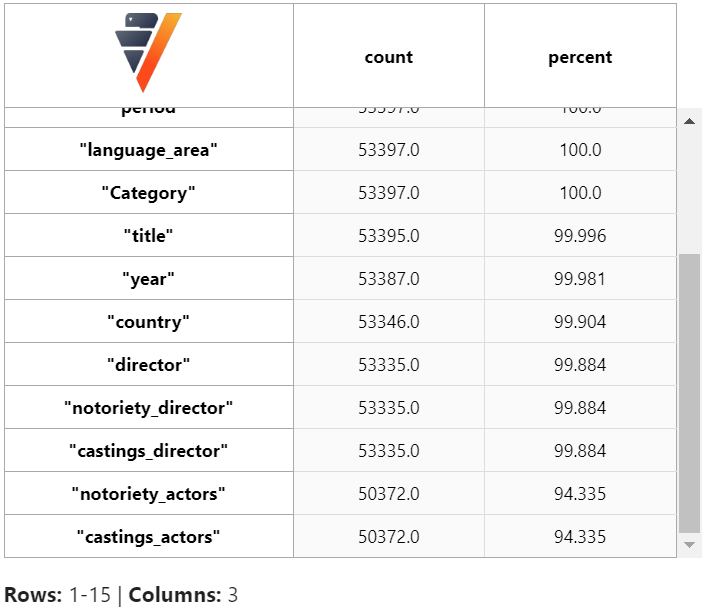
如我们所见,该数据集中有缺失值。让我们使用 verticapy 的 fillna 函数,以 median 方法填充 'notoriety_actors' 和 'castings_actors' 的缺失值。然后删除剩余的少量缺失值。
filmtv_movies_complete["notoriety_actors"].fillna(method = "median",
by = ["director",
"Category"])
filmtv_movies_complete["castings_actors"].fillna(method = "median",
by = ["director",
"Category"])
filmtv_movies_complete.dropna()
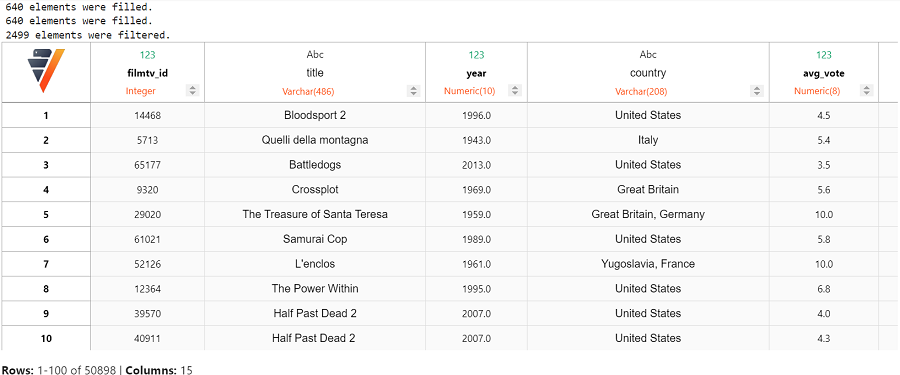
现在检查缺失值。我们可以看到该数据集中没有缺失值了。

在导出数据之前,我们将对数值列进行归一化,并为不同的类别(如 period、language_area 和 category)创建虚拟变量。
filmtv_movies_complete.normalize(method = "minmax",
columns = ['votes',
'duration',
'notoriety_director',
'castings_director',
'notoriety_actors',
'castings_actors'])
for elem in ['category', 'period', 'language_area']:
filmtv_movies_complete[elem].get_dummies(drop_first = True)
我们可以将结果导出到 Vertica 数据库。
vp.drop('"filmtv"."filmtv_movies_complete"', relation_type = "table")
filmtv_movies_complete.to_db(name = '"filmtv"."filmtv_movies_complete"',
relation_type = "table",
inplace = True)
vp.drop('"filmtv"."filmtv_movies_mco"', relation_type ="view")
filmtv_movies_complete.to_db(name = '"filmtv"."filmtv_movies_mco"',
relation_type = "view",
db_filter = "votes > 0.02")
机器学习:创建线性回归模型¶
我们可以创建一个模型来评估每部不同电影的无偏评分。让我们使用线性回归进行评估并获取报告。
from verticapy.learn.linear_model import LinearRegression
predictors = filmtv_movies_complete.get_columns(
exclude_columns = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"])
model = LinearRegression("filmtv_movies_lr",
max_iter = 1000,
solver = "BFGS")
model.fit('"filmtv"."filmtv_movies_mco"', predictors, "avg_vote")
model.report()
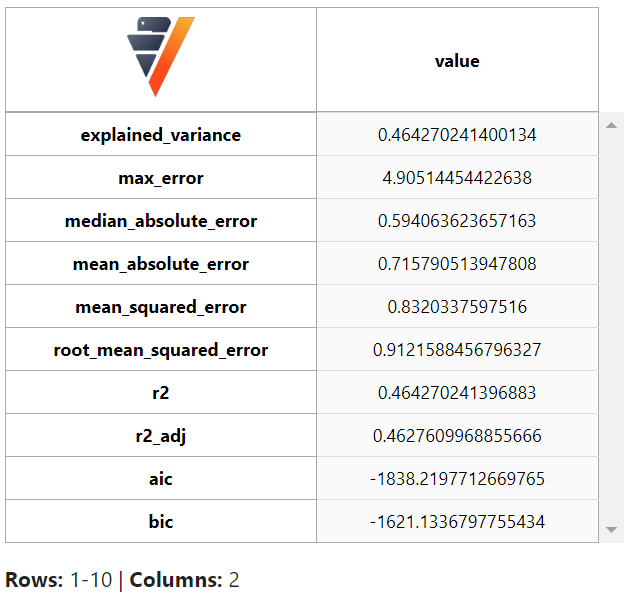
模型看起来不错。让我们将其添加到 vDataFrame 中。
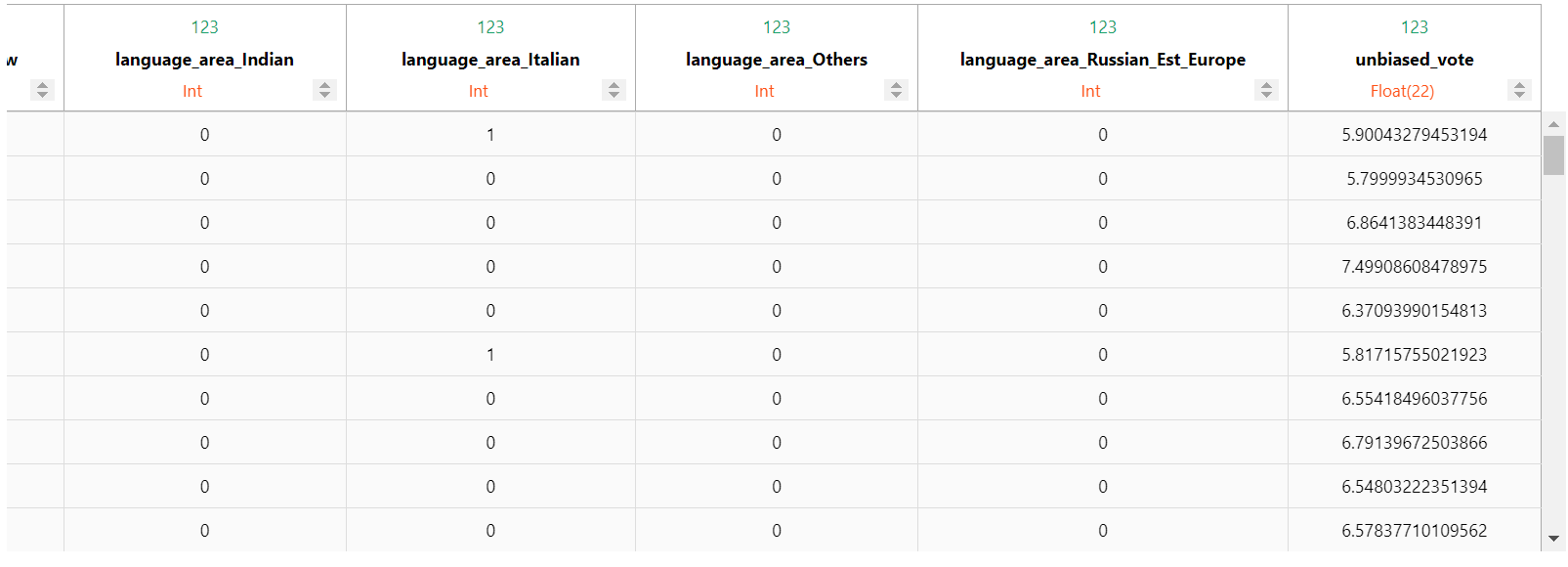
由于评分不能大于 10 或小于 0,我们需要将 'unbiased_vote' 调整到 0 到 10 之间。
filmtv_movies_complete["unbiased_vote"] = st.case_when(filmtv_movies_complete["unbiased_vote"] > 10, 10,
filmtv_movies_complete["unbiased_vote"] < 0, 0,
filmtv_movies_complete["unbiased_vote"])
让我们查看顶级电影。
filmtv_movies_complete.search(usecols = ['filmtv_id',
'title',
'year',
'country',
'avg_vote',
'unbiased_vote',
'votes',
'duration',
'director',
'notoriety_director',
'castings_director',
'notoriety_actors',
'castings_actors',
'period',
'language_area'],
order_by = {"unbiased_vote" : "desc",
"avg_vote" : "desc"}).head(10)
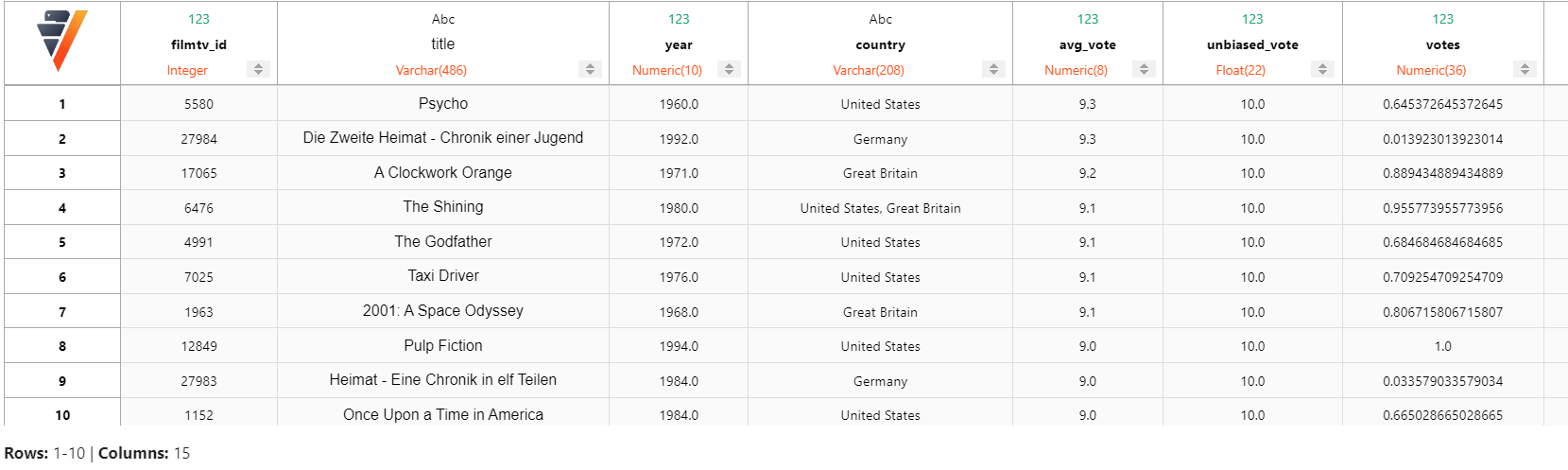
太好了,我们的结果更加一致。Psycho、Pulp Fiction 和 The Godfather 等电影位居顶级电影之列。
机器学习:创建电影聚类¶
让我们使用 K-means 聚类来创建相似电影的聚类。
由于 k-means 聚类对未归一化的数据敏感,让我们先归一化新的预测变量。
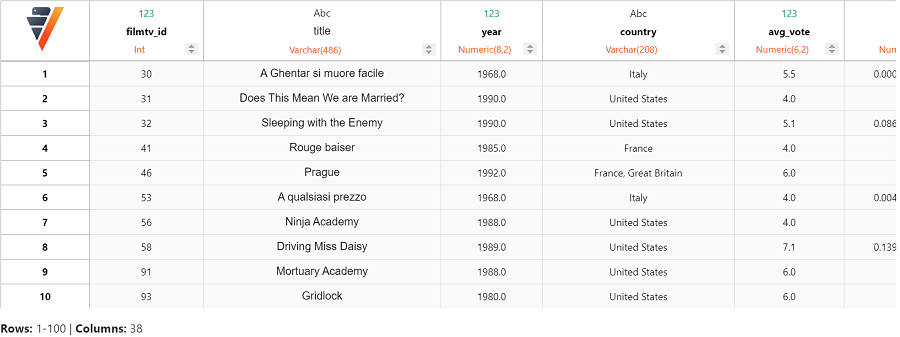
我们可以计算肘部曲线(elbow curve)来找到合适的聚类数,以创建 K-means 模型。
%matplotlib inline
predictors = filmtv_movies_complete.get_columns(
exclude_columns = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category",
"filmtv_id"])
from verticapy.learn.model_selection import elbow
elbow = elbow(filmtv_movies_complete,
predictors,
n_cluster = (1, 60))
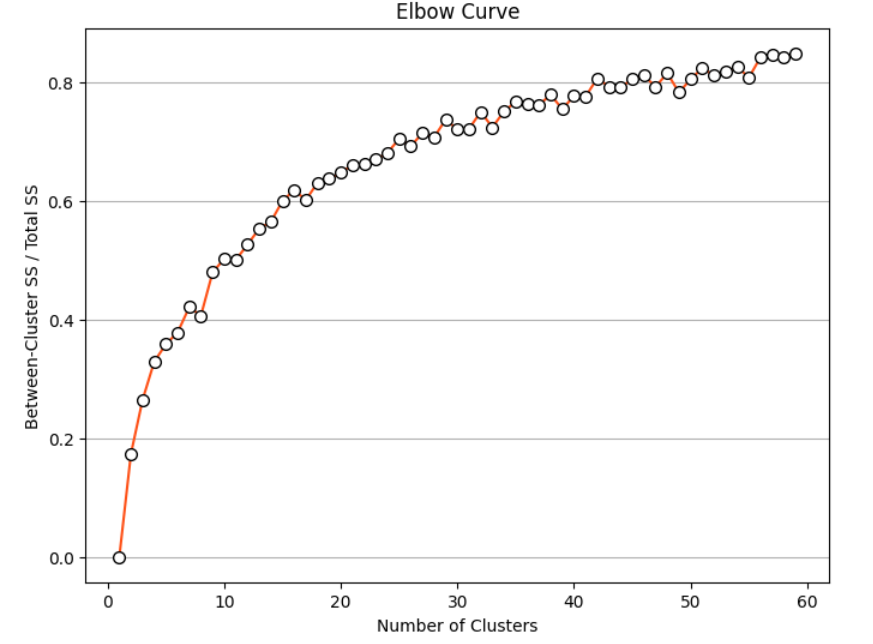
通过观察肘部曲线,我们可以选择 17 个聚类。让我们创建 k-means 模型。
from verticapy.learn.cluster import KMeans
model_kmeans = KMeans("filmtv_movies_clustering", n_cluster = 17)
model_kmeans.fit(filmtv_movies_complete, predictors)
model_kmeans.cluster_centers_
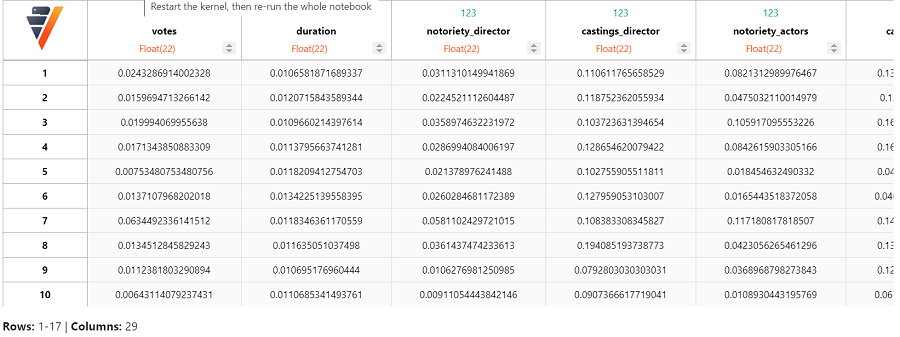
现在我们将聚类结果添加到 vDataFrame 中。
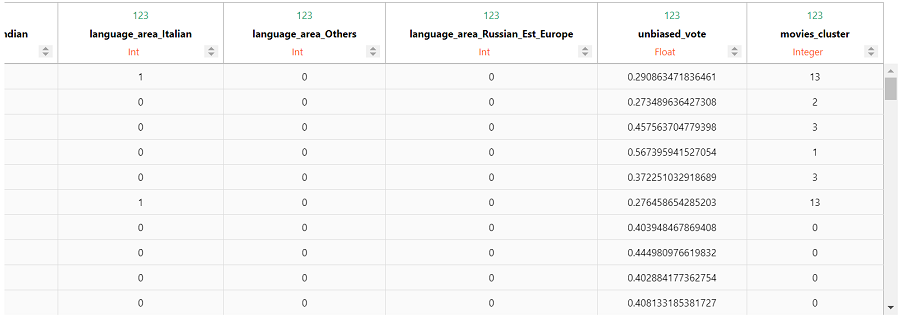
让我们查看不同的电影聚类。
filmtv_movies_complete.search(filmtv_movies_complete["movies_cluster"] == 0,
usecols = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"])
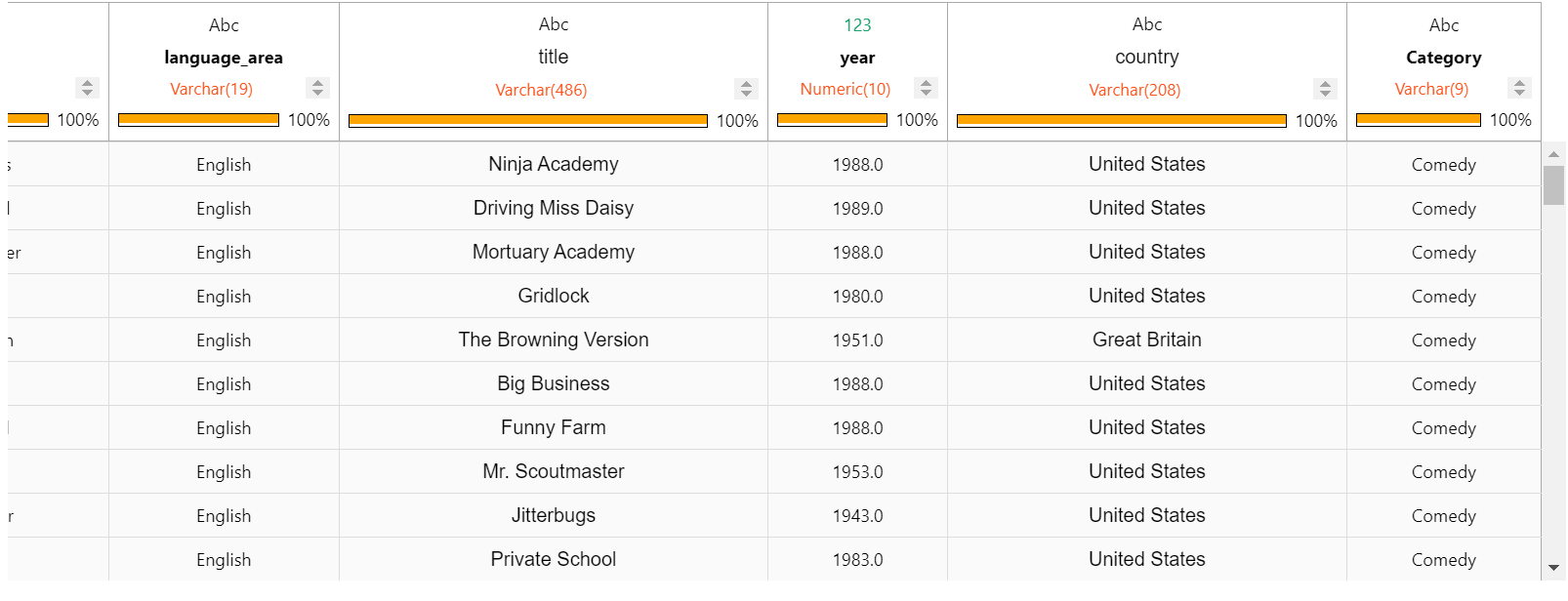
filmtv_movies_complete.search(filmtv_movies_complete["movies_cluster"] == 6,
usecols = ["avg_vote",
"period",
"director",
"language_area",
"title",
"year",
"country",
"Category"])
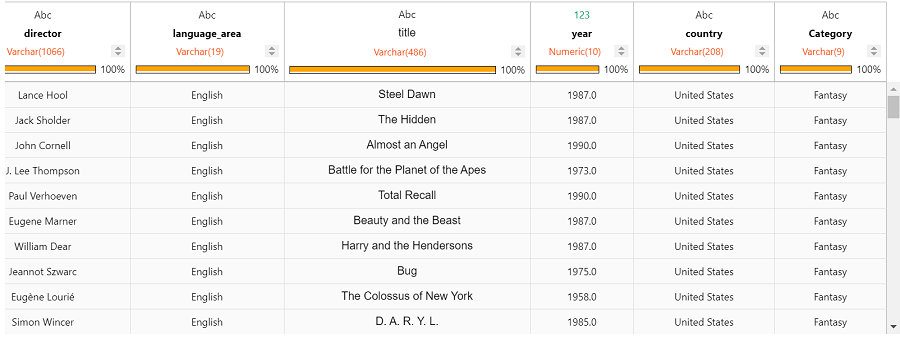
从结果中可以看出,每个聚类由相似电影组成。这些聚类可用于提供电影推荐或帮助流媒体平台对电影进行分组。