Vertica 备份与恢复方案总览¶
整合自 Vertica KB 5 篇备份恢复系列文章。
关联:Vertica 维护前准备 Checklist(备份是维护前第 2 步)| K-Safety 最佳实践
概述¶
备份是数据库日常运维的重要组成部分。Vertica 通过 vbr.py Python 脚本实现备份、恢复以及跨集群复制。根据数据量大小,可以进行全量和增量备份,也可以备份特定的表和 schema。同样,恢复时可以恢复整个数据库或只恢复特定表。配置好 vbr.py 的运行参数后,Vertica 也支持自动备份和恢复。
术语约定: 主集群称为 source,目标集群称为 target。备份始终在 source 上执行,恢复始终在 target 上执行。
本文档示例使用 2 节点集群以便简洁,但实际生产环境应使用 3 节点、K-safety = 1 的集群。
场景决策树¶
根据你的实际情况选择对应方案:
你的备份/恢复需求是什么?
│
├─ source = target(同一集群,备份到外部存储位置)
│ └─ → Part 1: 同集群备份与恢复
│
├─ source ≈ target(两个集群节点数、节点名、dbadmin、版本完全相同)
│ └─ → Part 2: 相似集群间复制
│
├─ source ≠ target(节点数或版本不同)
│ └─ → Part 3: 异构集群间复制
│
└─ 运行在 AWS 上
└─ → Part 4: AWS 备份恢复指南
| 你的情况 | 选这篇文章 |
|---|---|
| source = target,备份到外部存储位置 | Part 1 |
| source 和 target 是两个相同配置的集群(节点数、版本相同) | Part 2 |
| source 和 target 节点数、版本不同 | Part 3 |
| 在 AWS 上对 Vertica 集群做备份恢复 | Part 4 |
Part 1: 同集群备份与恢复¶
原文:Copy and Restore Data from a Vertica Cluster to a Backup
适用条件: source = target(同一集群),将数据备份到外部备份位置,再恢复到同一集群。
本文示例环境: source 节点 IP 为 10.100.0.66 和 10.100.0.77,target 节点 IP 为 10.100.0.88 和 10.100.0.99。
1.1 备份类型¶
Vertica vbr.py 工具支持以下三种备份类型:
| 备份类型 | 说明 | 限制 |
|---|---|---|
| 全量备份与恢复(Full backup and restore) | 完整复制数据库 catalog、schema、表及其他对象。提供备份时刻的数据库完整镜像 | 备份时对每张表加 U 锁,阻止 Tuple Mover 删除旧 container |
| 对象级备份与恢复(Object-level backup and restore) | 由一个或多个 schema/表(或对象组)组成。不包含整个数据库 | 仅包含指定对象 |
| Hard-link 本地备份与恢复(Hard-link local backup and restore) | 可以是全量或对象级备份。备份由完整的数据库 catalog 副本和一组指向对应数据文件的硬链接组成 | 仅本地文件系统 |
1.2 初始化备份配置¶
Vertica 7.2 起必须先初始化备份位置。配置文件包含数据库快照的元数据和备份文件,用于支持增量备份。
交互式回答各提示:
Snapshot name (backup_snapshot): backup_snapshot
Number of restore points (1): 5
Specify objects (no default): ← 留空 = 全量备份
Object restore mode (coexist, createOrReplace or create) (createOrReplace): createOrReplace
Vertica user name (dbadmin): mydatabase
Node v_mydatabase_node0001
Backup host name (no default): host1
Backup directory (no default): backup_location
Node v_mydatabase_node0002
Backup host name (no default): host2
Backup directory (no default): backup_location
Config file name (backup_snapshot.ini): backup_snapshot
Saved vbr config to backup_snapshot.
# 第 2 步:初始化备份位置
/opt/vertica/bin/vbr.py -t init --config-file backup_snapshot.ini
# 输出:
Initializing backup locations.
Backup locations initialized.
1.3 模式 A:全量备份 → 全量恢复¶
适用场景:
- 机房遭遇灾难,集群全部损失
- 数据库发生多节点、不可恢复的数据损坏,导致全部数据丢失
前提条件:
- target 集群与 source 集群节点数相同
- target 集群与 source 集群具有相同的 IP 地址、dbadmin 用户和数据库名
- source 和 target 运行相同的 Vertica 版本
- 必须已用备份配置文件在备份位置创建了全量备份
执行全量备份¶
在 source 集群上执行。下面是在 2 节点集群上创建全量备份的示例:
/opt/vertica/bin/vbr.py -t backup --config-file backup_snapshot.ini
# 输出:
Starting backup of database mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Snapshotting database.
Snapshot complete.
Approximate bytes to copy: 348431103 of 348431103 total.
Copying backup metadata.
Finalizing backup.
Backup complete!
关于恢复点: 如果在不同时间点多次备份数据库,Vertica 会记录每次备份之间的差异。每个时间点的备份称为一个恢复点(restore point)。
执行全量恢复¶
# === 在 target 上创建同名空库 ===
admintools -t create_db -d mydatabase -s v_mydatabase_node0001,v_mydatabase_node0002
admintools -t stop_db -d mydatabase
# === 在 target 上执行全量恢复(指定恢复到哪个时间点)===
/opt/vertica/bin/vbr.py -t restore --archive 20150914_150023 --config-file backup_snapshot.ini
# 输出:
Starting full restore of database mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Restoring from restore point: backup_snapshot_20150914_150023
Syncing data from backup to cluster nodes.
Restoring catalog.
Restore complete!
--archive参数用于指定恢复到哪个特定的恢复点(快照名)。
| 优点 | 限制 |
|---|---|
| 数据库在线运行时可备份 | 恢复时 target 数据库必须停机 |
| 支持多次增量备份 | source 和 target 的节点数、IP 地址、数据库名、dbadmin、版本必须完全一致 |
| 可从完整数据库丢失中恢复 | — |
| 数据变化不大时增量备份非常快 | — |
1.4 模式 B:全量备份 → 恢复单表¶
适用场景: 假设你不小心 TRUNCATE 了一张表。如果全库恢复,会丢失上次备份后新增的所有数据。此时就适合只恢复被误删的那张表。
前提条件: 与全量恢复相同。
示例: 全量备份后,误 TRUNCATE store_sales 表。之后又创建了新表 table_order 并插入了数据。如果全库恢复到全量备份的时间点,会丢失 table_order。
-- 备份后做了误操作
TRUNCATE TABLE STORE.STORE_SALES;
-- 验证:表已空
SELECT COUNT(*) FROM STORE.STORE_SALES; -- 0
-- 之后新增了数据
CREATE TABLE TABLE_ORDER (I INT);
INSERT INTO TABLE_ORDER VALUES (1);
COMMIT DURABLE;
只恢复 store_sales 表:
/opt/vertica/bin/vbr.py -t restore --archive 20150914_195908 \
--config-file backup_snapshot.ini \
--restore-objects "store.store_sales"
# 输出:
Starting object restore of database mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Objects to restore: store.store_sales.
Restoring from restore point: backup_snapshot_20150914_195908
Loading snapshot catalog from backup.
Extracting objects from catalog.
Syncing data from backup to cluster nodes.
Finalizing restore.
Restore complete!
验证结果:
-- store_sales 已恢复
SELECT COUNT(*) FROM STORE.STORE_SALES; -- 5000000
-- table_order 未受影响
SELECT * FROM TABLE_ORDER; -- 1
⚠️ 注意参照完整性: 如果要恢复的表有主键或外键约束,务必同时恢复关联的表以维护参照完整性。
| 优点 | 限制 |
|---|---|
| 支持多次增量备份 | 恢复时 source 和 target 约束同模式 A |
| 可恢复特定表(非整库) | — |
| 恢复时数据库可以在线运行 | — |
| 比全库恢复更快 | — |
| 数据变化不大时增量备份很快 | — |
1.5 模式 C:部分备份 → 恢复单表¶
适用场景: 数据库中大部分表数据不变(如 Products),但某些表(如 Sales)频繁变化。只需要备份和恢复这些特定表。
前提条件: 与全量备份恢复相同。
备份特定表¶
# 配置文件 objectbak.ini
[Misc]
snapshotName = objectbak
restorePointLimit = 5
objects = store.store_sales,public.new_table
objectRestoreMode = createOrReplace
[Database]
dbName = mydatabase
dbUser = dbadmin
dbPromptForPassword = False
[Transmission]
[Mapping]
v_mydatabase_node0001 = host1:/vertica/data/objbackup
v_mydatabase_node0002 = host1:/vertica/data/objbackup
/opt/vertica/bin/vbr.py -t backup --config-file objectbak.ini
# 输出:
Starting backup of database mydatabase.
Objects: ['public.new_table', 'store.store_sales']
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Snapshotting database.
Snapshot complete.
Approximate bytes to copy: 51 of 108630328 total.
Copying backup metadata.
Finalizing backup.
Backup complete!
注意:备份时只复制了 51 字节(仅 catalog 元数据),而数据库总共 108MB。因为这次备份只针对 2 张表。
从部分备份中恢复指定表¶
/opt/vertica/bin/vbr.py -t restore --config-file objectbak.ini \
--restore-objects "store.store_sales"
# 输出:
Starting object restore of database mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Objects to restore: store.store_sales.
Restoring from restore point: objectbak_20150914_203903
Loading snapshot catalog from backup.
Extracting objects from catalog.
Syncing data from backup to cluster nodes.
Finalizing restore.
Restore complete!
| 优点 | 限制 |
|---|---|
| 数据库在线时备份 | 仅适用于表和分区 |
| 支持多次增量备份 | source/target 约束同模式 A |
| 可恢复特定表 | — |
| 比全量备份快,节省备份位置磁盘空间 | — |
| 恢复时其他表数据不丢失 | — |
1.6 模式 D:并排表恢复(Side-by-Side)¶
适用场景: 周一早上发现周末 10 个作业中 9 个通过、1 个失败。失败的作业以不可预测的方式修改了数据。你需要对比当前数据与周五的备份数据,找出差异。
前提条件: 与全量备份恢复相同。
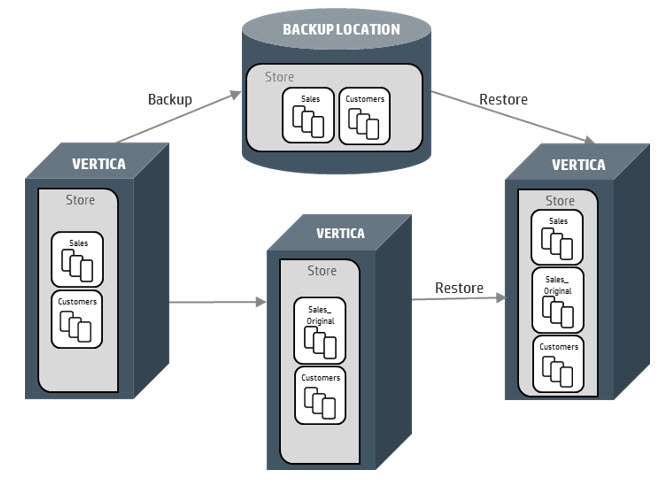
完整步骤:
-- 第 1 步:将当前表重命名(保留修改后的版本)
ALTER TABLE STORE.STORE_SALES RENAME TO STORE_SALES_ORIGINAL;
ALTER PROJECTION STORE.STORE_SALES_SUPER RENAME TO STORE_SALES_ORIGINAL_SUPER;
# 第 2 步:从备份恢复原始表(此时两个版本同时存在)
/opt/vertica/bin/vbr.py -t restore --config-file objectbak.ini \
--restore-objects "store.store_sales"
# 输出:
Starting object restore of database mydatabase.
...
Restore complete!
-- 第 3 步:查看两张表
\dt STORE_SALES*
Schema | Name | Kind | Owner
store | store_sales | table | dbadmin
store | store_sales_original | table | dbadmin
现在可以对比 store_sales_original(修改后的版本)和 store_sales(备份版本),然后将 store_sales 更新为正确的数据。通过分区交换合并两个表:
-- 第 4 步:按需交换分区
SELECT SWAP_PARTITIONS_BETWEEN_TABLES(
'STORE.STORE_SALES', '1', '1', 'STORE.STORE_SALES_ORIGINAL'
);
| 优点 | 限制 |
|---|---|
| 可恢复已有表的备份 | source/target 约束同模式 A |
| 可在活表和备份表之间执行操作 | 仅适用于表和分区 |
| 备份后原表和恢复表同时可用 | — |
Part 2: 相似集群间复制¶
原文:Copying Data Between Similar Vertica Clusters
适用条件: source 和 target 是两个完全相同的 Vertica 集群 —— 相同的节点数、节点名、dbadmin 用户、Vertica 版本。IP 地址可以不同。
本文示例环境: source 节点 IP 为 10.100.0.66 和 10.100.0.77,target 节点 IP 为 10.100.0.88 和 10.100.0.99。
2.1 模式 A:copycluster(全库复制)¶
--copycluster 选项将备份和恢复合并为一步操作。Vertica 从 source 备份数据并恢复到 target,整个过程在一个命令中完成。
⚠️ 警告:
vbr --copycluster会覆盖目标集群的所有现有数据。
前提条件:
- target 集群的 IP 地址与 source 不同
- source 和 target 共享相同的节点数、节点名、dbadmin 用户、数据库名、Vertica 版本
- source 和 target 之间配置了免密 SSH
完整步骤¶
# === 步骤 1:在 target 上安装同版本 Vertica ===
sudo /opt/vertica/sbin/install_vertica --accept-eula \
--license '/opt/vertica/config/licensing/vertica_community_edition.license.key' \
--point-to-point --dba-user-password-disabled --ssh-identity
# === 步骤 2:在 target 上创建同名空库 ===
admintools -t create_db -s 10.100.0.88,10.100.0.99 -d mydatabase
# 输出:
Info: no password specified, using none
Database with 1 or 2 nodes cannot be k-safe and it may lose data if it crashes
Database mydatabase created successfully.
# === 步骤 3:停止 target 空库(copycluster 要求 target 停机)===
admintools -t stop_db -d mydatabase
# 输出:
Info: no password specified, using none
Connecting to database
Issuing shutdown command to database
Database mydatabase stopped successfully
# === 步骤 4:在 source 上创建配置文件 ===
# backup host 填写 target 节点的 IP 地址
/opt/vertica/bin/vbr --setupconfig
交互过程:
Snapshot name (backup_snapshot):
Number of restore points (1): 3
Object restore mode (coexist, createOrReplace or create) (createOrReplace): coexist
Vertica user name (dbadmin):
Node v_verticadb1_node0001
Backup host name (no default): 10.100.0.88 ← target 节点 IP
Backup directory (no default):
Node v_verticadb1_node0002
Backup host name (no default): 10.100.0.99 ← target 节点 IP
Backup directory (no default):
Change advanced settings? (n) [y/n]: n
Config file name (backup_snapshot.ini): copyclusterconfig.ini
Saved vbr config to copyclusterconfig.ini
# === 步骤 5:在 source 上执行 copycluster ===
# 确认 source 数据库处于 UP 状态后执行
/opt/vertica/bin/vbr --config-file copyclusterconfig.ini --task copycluster
# 输出:
Starting copy of database mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Enter vertica password:
Snapshotting database.
Snapshot complete.
Syncing data to destination cluster.
[==================================================] 100%
Reinitializing destination catalog.
Copycluster complete!
# === 步骤 6:在 target 上启动数据库并验证 ===
admintools -t start_db -d mydatabase
# 输出:
Info: no password specified, using none
Starting nodes:
v_mydatabase_node0001 (10.100.0.88)
v_mydatabase_node0002 (10.100.0.99)
Starting Vertica on all nodes...
Node Status: v_mydatabase_node0001: (DOWN) v_mydatabase_node0002: (DOWN)
...
Node Status: v_mydatabase_node0001: (UP) v_mydatabase_node0002: (UP)
Database mydatabase started successfully
# 验证数据已复制
vsql -c "\dt store_sales*"
List of tables
Schema | Name | Kind | Owner
store | store_sales | table | dbadmin
store | store_sales_fact | table | dbadmin
store | store_sales_original | table | dbadmin
| 优点 | 限制 |
|---|---|
| 可创建 source 数据库的完整副本 | source 所有节点必须 UP |
| 多次执行 copycluster 支持增量复制 | target 必须停机 |
| 一步完成备份+恢复 | 节点数、节点名、数据库名、dbadmin、版本必须一致 |
2.2 模式 B:replicate(单表复制)¶
适用场景: source 有 50 张表且已在 target 上备份了 50 张。新增 5 张表,只需要把这 5 张表复制到 target。
特殊之处: source 和 target 可以有不同的节点名和数据库名。
前提条件¶
| 必须相同 | 可以不同 |
|---|---|
| 节点数 | 节点名 |
| Vertica 版本 | 数据库名 |
| dbadmin 用户名 | IP 地址 |
objectRestoreMode 三种选项¶
| 模式 | 行为 | 适用场景 |
|---|---|---|
coexist |
创建带前缀 backup_<timestamp>_<object_name> 的表,与已有表共存 |
需要对比或合并数据 |
createOrReplace |
在 target 创建同名表;如果有同名表则先删除再创建 | 直接覆盖 |
create |
仅在 target 创建同名表;如果有同名表则不覆盖 | 避免意外覆盖 |
完整步骤(以 coexist 模式为例)¶
在 source 上创建数据:
-- 创建一张新表并插入数据
CREATE TABLE cluster1_table1 (i INT NOT NULL) PARTITION BY i;
COPY cluster1_table1 FROM stdin;
1
2
3
4
5
\.
SELECT * FROM cluster1_table1;
i
---
2
3
5
1
4
(5 rows)
-- 还有一张不需要复制的表
\dt
Schema | Name | Kind | Owner
public | cluster1_table1 | table | dbadmin
public | table_that_wont_be_moved | table | dbadmin
在 source 上创建 replicate 配置文件:
交互过程:
Snapshot name (backup_snapshot):
Destination Vertica DB bin directory (only required for object replication) (/opt/vertica/bin):
Number of restore points (1): 3
Specify objects (no default): public.cluster1_table1
Object restore mode (coexist, createOrReplace or create) (createOrReplace): coexist
Vertica user name (dbadmin):
Save password to avoid runtime prompt? (n) [y/n]: n
Node v_mydatabase_node0001
Backup host name (no default): 10.100.0.88
Backup directory (no default): /vertica/backuplocation
Node v_mydatabase_node0002
Backup host name (no default): 10.100.0.99
Backup directory (no default): /vertica/backuplocation
Change advanced settings? (n) [y/n]: n
Config file name (test1.ini): object_specific_replication.ini
Saved vbr config to object_specific_replication.ini.
生成的配置文件内容:
# object_specific_replication.ini
[Misc]
snapshotName = backup_snapshot
dest_verticaBinDir = /opt/vertica/bin
restorePointLimit = 3
objects = public.cluster1_table1
objectRestoreMode = coexist
[Database]
dbName = mydatabase
dbUser = dbadmin
dbPromptForPassword = True
[Mapping]
v_mydatabase_node0001 = 10.100.0.88:/vertica/backuplocation
v_mydatabase_node0002 = 10.100.0.99:/vertica/backuplocation
修改配置文件(如果 target 数据库名不同):
[Database]
dbName = targetdb # ← 改成 target 的数据库名
dbUser = dbadmin
[Mapping]
v_mydatabase_node0001 = 10.100.0.88:/vertica/backuplocation
v_mydatabase_node0002 = 10.100.0.99:/vertica/backuplocation
执行 replicate:
vbr -t replicate -c object_specific_replication.ini
# 输出:
Configured backup directories in Mapping are ignored for object replication.
Starting replication of objects ['public.cluster1_table1'] from mydatabase.
Participating nodes: v_mydatabase_node0001, v_mydatabase_node0002.
Enter vertica password:
Snapshotting the source database.
Snapshot complete.
Copying catalog snapshot from source to destination.
Preparing destination database for replicating objects.
Prep complete, start syncing files.
Complete syncing files, removing snapshot from the source database.
Finalizing object replication.
Object replication complete!
coexist 模式下的数据合并(仅在 coexist 模式下需要):
-- 在 target 上查看:备份表以 backup_<ts>_public 前缀存在
\dt
Schema | Name | Kind | Owner
backup_snapshot_20160203221054_public | cluster1_table1 | table | dbadmin
public | cluster2_table2 | table | dbadmin
-- cluster2_table2 当前数据(target 本地已有):
SELECT * FROM public.cluster2_table2;
i
----
15
13
12
14
11
(5 rows)
-- 将备份表的分区数据移动到 target 本地表
-- 两表必须有完全相同的 schema、投影和分区定义
SELECT MOVE_PARTITIONS_TO_TABLE(
'backup_snapshot_20160203221054_public.cluster1_table1',
1, 5, 'public.cluster2_table2'
);
输出:5 distinct partition values moved at epoch 17.
-- 合并后的数据:
SELECT * FROM cluster2_table2;
i
----
5
3
2
11
15
15
13
12
4
1
(10 rows)
数据移动后,备份源表(带
backup_前缀的表)不再有数据。MOVE_PARTITIONS_TO_TABLE将数据从原位置移除。
| 优点 | 限制 |
|---|---|
| source 和 target 都可以在线 | 表必须有相同的 schema 和投影定义 |
| 支持多次增量备份 | 需手动迁移 UDF/库(两端必须一致) |
| 可选择单独的表进行迁移 | — |
| 比全量备份快,节省磁盘空间 | — |
| source 和 target 可以有不同数据库名和 dbadmin | — |
Part 3: 异构集群间复制¶
原文:Copying Data Between Dissimilar Vertica Clusters
适用条件: source 和 target 节点数不同、Vertica 版本不同。
如果 source 和 target 相似,使用 Part 2 的 vbr.py 方案即可。但跨版本、跨规模的场景需要以下方案。
3.1 方法 A:Vertica EXPORT / IMPORT(推荐)¶
使用 Vertica 内置的导出/导入功能,将数据从旧版本复制到新版本。即使两个集群的以下方面完全不同,也能轻松复制数据库:
- Vertica 版本
- 节点数
- 数据库名
- dbadmin 用户名
⚠️ 注意: 如果两个集群运行不同版本的 Vertica,务必从最新的版本执行导出/导入,以避免向后兼容性问题。如果两个集群规模不同,务必确保 target 集群有足够空间容纳 source 集群的数据。
相关文档:
- Understanding Vertica Import and Export
- Configuring Network to Import and Export Data
- Export to Vertica(产品文档)
| 优点 | 限制 |
|---|---|
| source 和 target 集群大小、节点名、dbadmin、IP、投影和 schema 可全部不同 | 比 vbr.py 慢 |
| 不需要 source 和 target 的所有节点都 UP | 需手动迁移 UDF/库(两端必须一致) |
| 支持跨版本数据迁移 | — |
| 支持基于 epoch(AHM 之后的所有 epoch)的增量传输 | — |
| 可使用特定查询迁移数据 | — |
3.2 方法 B:第三方工具¶
可通过 Vertica 支持的第三方应用程序在不同集群间复制数据。数据分别加载到 source 和 target。
例如 Attunity Replicate: 专为大数据分析设计的数据加载加速工具。详见 Qlik (Attunity) 网站上的 Data Management for the Vertica Analytics Platform。
| 优点 | 限制 |
|---|---|
| 专业的数据同步和加速能力 | 需要额外购买 license |
Part 4: AWS 备份恢复指南¶
原文:Vertica on Amazon Web Services Backup and Restore Guide
适用条件: Vertica 集群运行在 AWS EC2 上。
本文使用 VMart 示例数据库演示从多种故障中恢复的方法。
4.0 K-Safe 集群配置¶
K-safe 集群通过在其他节点存储 buddy 数据,防止单节点故障导致数据丢失。要成为 K-safe,集群至少需要 3 个节点。详见 K-Safety 最佳实践 和 Designing For K-Safety。
4.1 策略一:从 K-Safe 故障中恢复(无需备份)¶
适用: 隔离的单节点故障,集群仍为 UP 状态。
从 K-safe 故障恢复不需要备份。如果节点宕机且无法重新连接,必须重新创建该节点。
如果主节点故障,必须先重新分配 Elastic IP,然后将
.pem密钥文件复制到其他运行中的节点以进行恢复。
步骤 A:创建目标节点¶
创建目标 AWS 实例时,必须满足以下条件:
| 要求 | 说明 |
|---|---|
| 子网/网络/VPC | 与 source 集群节点位于相同子网、网络和 VPC,且网络配置相同 |
| 集群放置组和可用区 | 与 source 集群节点位于相同的集群放置组和可用区 |
| 内网 IP 地址 | 必须与 source 节点的 IP 地址相同(通过实例创建时的 Network Interfaces 选项指定) |
| 版本兼容性 | 使用与 source 集群节点相同的 Vertica AMI 版本和 hotfix 版本 |
| 实例类型 | 使用与 source 集群节点相同的实例类型 |
步骤 B:恢复节点¶
# 1. 在所有节点上删除故障节点的 .pem key 信息
/root/.ssh/known_hosts
/home/dbadmin/.ssh/known_hosts
# 2. 在主节点上运行 install_vertica 脚本
# 指定你自己的密钥文件、-Y 选项为 point-to-point、禁用 dba 用户密码
sudo /opt/vertica/sbin/install_vertica -i ~/userkey.pem -Y \
--point-to-point --dba-user-password-disabled --dba-user dbadmin
# 3. SSH 到目标节点,配置存储以匹配 source 集群
# 创建与 source 节点匹配的空 catalog 和 data 目录
mkdir -p /vertica/data/VMart/v_vmart_node0003_catalog
sudo chown dbadmin:verticadba /vertica/data/VMart
# 4. 使用 admintools 重启目标节点
# 指定目标节点的 IP 地址和数据库名
admintools -t restart_node -s 10.0.10.15 -d VMart
目标节点将从其 buddy 节点恢复数据,使集群恢复 K-safe 状态。恢复时间取决于数据库大小。
4.2 策略二:全量备份(EBS)¶
适用: 非 K-safe 损失,如多节点故障或全集群故障。
全量备份捕获数据库在特定时间点的完整镜像,是最安全、最稳定的备份方式。
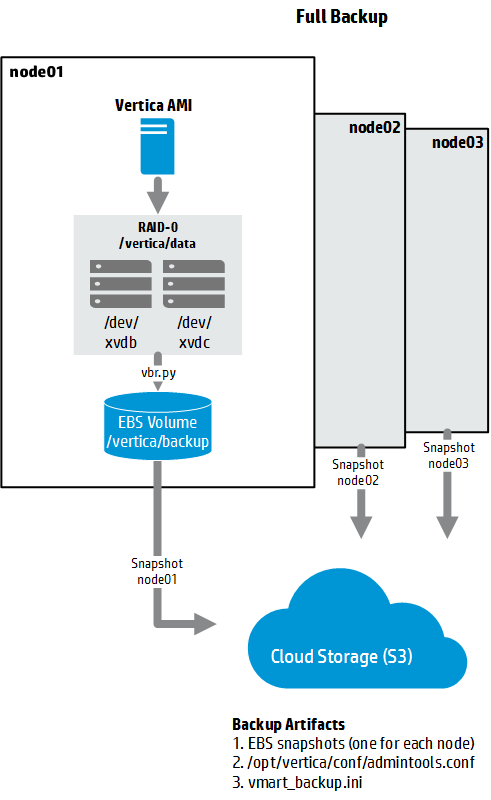
存储注意事项¶
- 如果使用 ephemeral 存储,必须做全量备份(ephemeral 不持久)。
- 备份卷必须使用 EBS 存储。
- 需要一个完整备份 = 正确格式化并挂载的备份卷 + AWS EBS snapshot + 备份配置文件。
准备备份卷¶
# 1. 查找每个 source 节点的 data catalog 大小
df -h /vertica/data/
# 关注 Used 列的数字
# 2. 找出所有 source 节点中最大的 data catalog,
在此基础上增加 20–50% 的安全余量
# 3. 创建并挂载一个新的 EBS 卷到每个 source 节点
卷大小 = 最大 catalog + 安全余量
# 4. 验证新卷已出现在每个节点上
ls /dev
# 5. 在所有节点上执行(使用 Vertica 支持的文件系统):
sudo mkfs.ext4 /dev/xvdf
sudo mkdir /vertica/backup
sudo mount /vertica/backup
sudo bash -c "echo '/dev/xvdf /vertica/backup ext4 defaults 0 0' >> /etc/fstab"
sudo chown dbadmin:verticadba /vertica/backup
# 6. 验证挂载成功
df -h
创建备份¶
# 创建配置文件
/opt/vertica/bin/vbr.py --config-file vmart_backup.ini --task backup
# 执行全量备份
/opt/vertica/bin/vbr.py --config-file vmart_backup.ini --task backup
# 验证 vbr.py 无错误完成
# 在每个节点的备份卷上创建 EBS snapshot
# 保存 admintools.conf:/opt/vertica/conf/admintools.conf
- 如果配置文件依赖密码文件,可能需要将密码文件复制到每个节点才能运行 vbr.py。
- 完整初始备份 = EBS snapshot + 备份配置文件 + admintools.conf。
- 后续可做增量备份:重复创建备份 + 创建 snapshot(只保存与首次的差异部分)。
- Snapshot 是异步的,上一个 snapshot 还在进行时可以开始写下一个备份。
从全量备份恢复¶
如果集群故障,使用备份配置文件和备份卷的 snapshot 从最近一次全量备份恢复。
# === 步骤 1:创建 target 集群 ===
新实例必须与 source 集群匹配:
- 相同网络/VPC(target 节点之间相同,但不必与 source 相同)
- 相同的实例数和节点数
- 相同的节点内网 IP 地址
- 相同的 AMI 和 Vertica 版本,相同 hotfix 版本
可以不同:可用区、实例类型
# === 步骤 2:从 source 备份的 snapshot 创建 EBS 卷 ===
为每个节点创建一个卷并挂载到 target 集群的对应节点
⚠️ device mapping 必须正确:例如 node 1 的备份 snapshot
必须恢复到新集群的 node 1 上
# === 步骤 3:挂载备份位置 ===
# 在所有节点上,以与 source 相同的文件路径挂载:
sudo bash -c "echo '/dev/xvdf /vertica/backup ext4 defaults 0 0' >> /etc/fstab"
sudo mkdir /vertica/backup
sudo mount /vertica/backup
# 验证备份目录下有数据
ls /vertica/backup/
# === 步骤 4:创建同名空库 ===
参考备份的 admintools.conf,使用相同的 dbadmin 用户名/密码、数据路径、数据库名
停止数据库(如果正在运行)
# === 步骤 5:执行恢复 ===
/opt/vertica/bin/vbr.py --config-file vmart_backup.ini --task restore
# === 步骤 6:启动数据库,完成恢复 ===
4.3 策略三:Hard-Link 备份(RAID-0)¶
AWS 上的 hard-link 备份与传统裸机 Vertica 安装截然不同。 由于 RAID-0 软件设备由多个 EBS 卷组成,对每个 EBS 卷做 snapshot 存在极其微小的时间差,会导致备份不一致。因此必须先冻结或卸载 RAID-0 文件系统,然后再做 snapshot。不能在使用 ephemeral 卷的安装上执行 hard-link 备份。
两种执行方式可选:
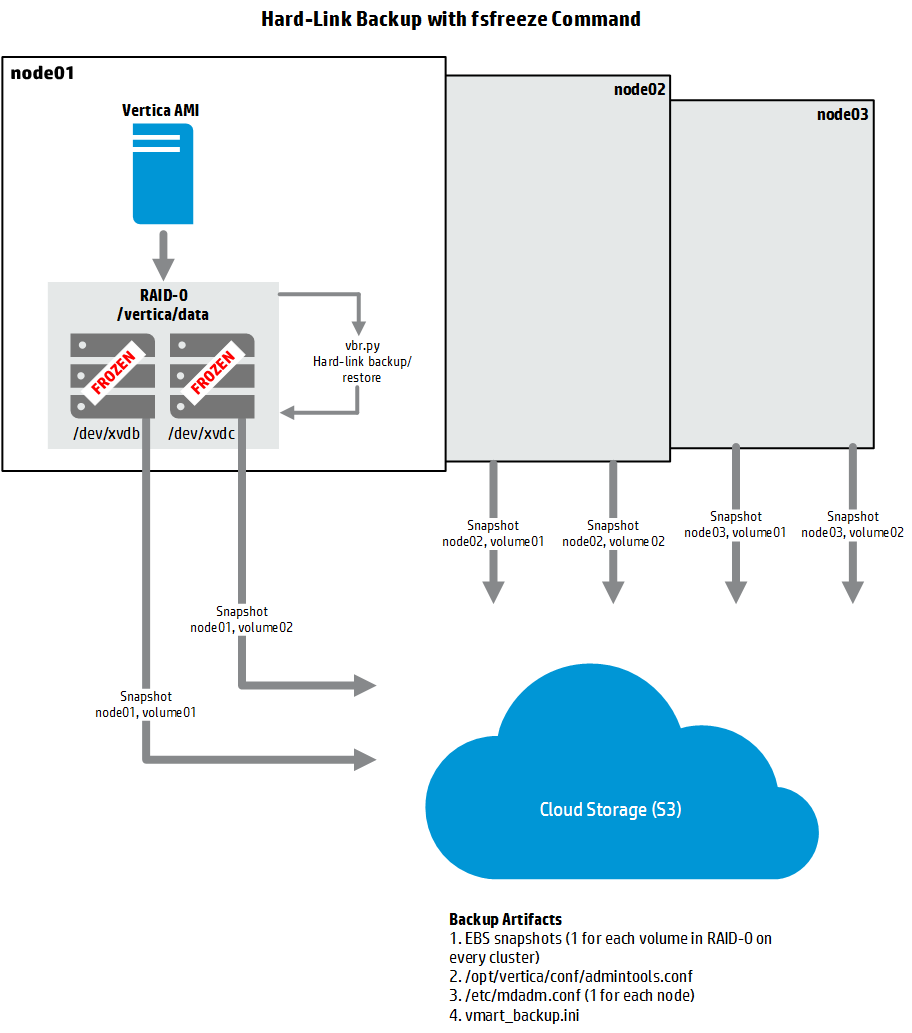
方法 A:admintools stop(需要停机)¶
如果备份时数据库已停机,恢复时无需 vbr.py 备份和恢复脚本。但如想维护多个时间点备份,仍可用 vbr.py。
适用于 SLA 允许停机足够长以发起 snapshot 的场景。
# 1. 停止数据库
admintools -t stop_db -d VMart
# 2. 在每个节点上卸载数据卷
umount /vertica/data
# 3. 创建整个集群所有 RAID-0 卷的 EBS snapshot
# 记录每个卷对应的 snapshot ID(恢复时需要)
# 4. 在每个节点上重新挂载数据卷
mount /vertica/data
# 5. 启动数据库
admintools -t start_db -d VMart
必须保存以下文件:
- 每个节点的 RAID-0 配置文件:
/etc/mdadm.conf - 备份配置文件:
vmart_backup.ini - [可选] admintools 配置文件:
/opt/vertica/conf/admintools.conf
方法 B:fsfreeze(秒级冻结,几乎不停机)¶
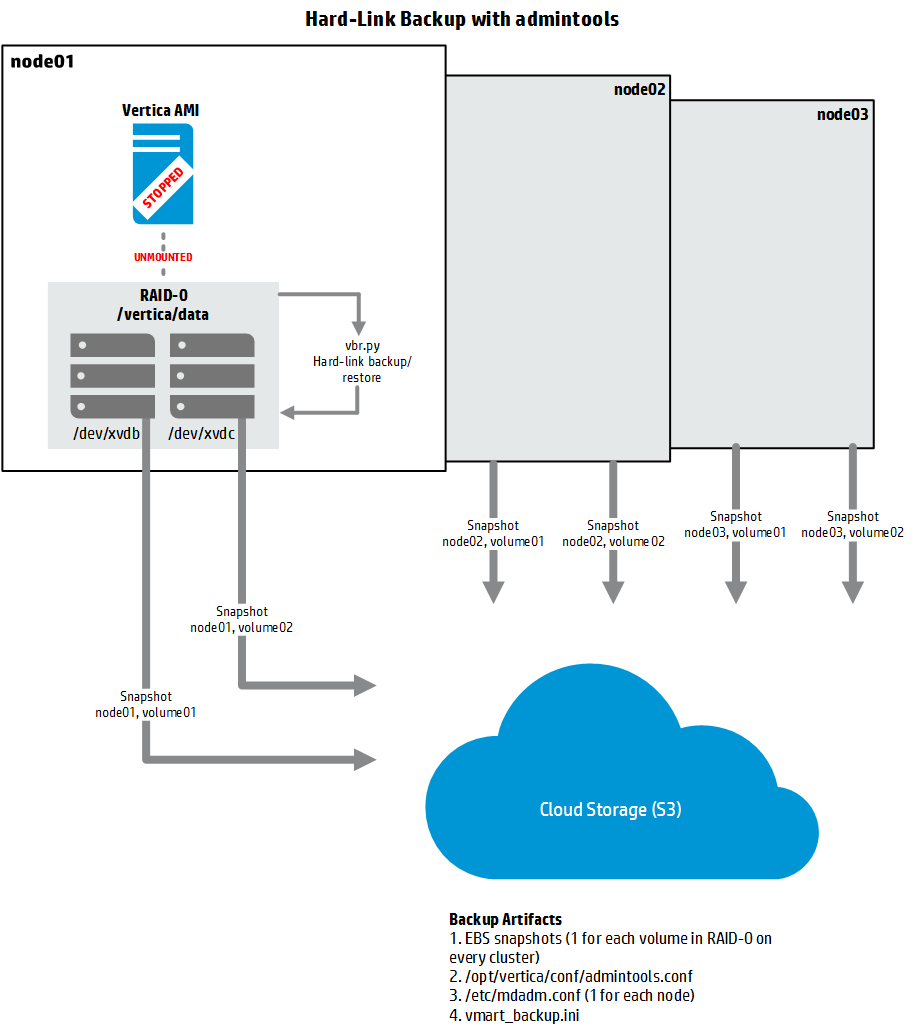
用 fsfreeze 命令冻结集群,无需停止集群。用户几乎感觉不到性能影响。必须使用 vbr.py 从 fsfreeze 方式创建的备份中恢复。
# 1. 在 RAID-0 设备上创建 hard-link 备份
/opt/vertica/bin/vbr.py --config-file vmart_backup.ini --task backup
# 2. 冻结整个集群的 RAID-0 卷(保证 EBS snapshot 一致性)
# ⚠️ 冻结期间暂停所有数据库/SQL 操作
for IP in 10.0.10.13 10.0.10.14 10.0.10.15; do
ssh $IP sudo fsfreeze --freeze /vertica/data
done
⚠️ 绝对不要在没有冻结的情况下对 RAID-0 卷做 snapshot! 没有冻结会直接导致 snapshot 无效。必须检查
fsfreeze --freeze的返回码,确认设备已冻结再继续。
# 3. 创建所有 RAID-0 卷的 EBS snapshot
# 记录每个卷对应的 snapshot ID
# 4. 所有 EBS 卷所有节点的 snapshot 都已启动后,解冻文件系统
# 注意:无需等待 snapshot 完成即可解冻
for IP in 10.0.10.13 10.0.10.14 10.0.10.15; do
ssh $IP sudo fsfreeze --unfreeze /vertica/data
done
必须保存以下文件:
- 每个节点的 RAID-0 配置文件:
/etc/mdadm.conf - 备份配置文件:
vmart_backup.ini - [可选] admintools 配置文件:
/opt/vertica/conf/admintools.conf
从 Hard-Link 备份恢复¶
# 1. 创建 target 集群(要求同全量备份恢复:相同网络/VPC、节点数、内网 IP、AMI/hotfix)
# 2. 从备份的 snapshot 创建 EBS 卷
# 3. 挂载新卷之前,先停止并卸载 target 集群上已有的 RAID 卷
# 4. 将新 EBS 卷挂载到 target 集群的对应节点和卷位置
⚠️ device mapping 必须正确:node 1 卷 /dev/xvdf 的 snapshot →
新集群 node 1 卷 /dev/xvdf
# 5. 用保存的 mdadm.conf 重建 RAID-0 设备
恢复 /etc/mdadm.conf
# 6. 卷挂载完成后,重新挂载 RAID
for IP in 10.0.10.13 10.0.10.14 10.0.10.15; do
ssh $IP sudo mount /vertica/data
done
# 7. 创建同名空库(相同 dbadmin 用户名/密码、数据路径、数据库名)
# 执行恢复
/opt/vertica/bin/vbr.py --config-file vmart_backup.ini --task restore
两种 Hard-Link 备份方式对比¶
| 比较维度 | admintools stop | fsfreeze |
|---|---|---|
| 停机时间 | 需要完全停机 | 秒级冻结 |
| 适用条件 | SLA 允许停机 | 不能停机的生产环境 |
| 恢复工具 | 可不通过 vbr.py(停机备份的卷直接挂载即可用) | 必须通过 vbr.py |
| 多时间点备份 | 可用 vbr.py | 可用 vbr.py |
全方案对比速查¶
| 方案 | 适用场景 | 节点数 | 版本 | 工具 | 停机要求 |
|---|---|---|---|---|---|
| 全量备份恢复 | 同集群灾难恢复 | 必须相同 | 必须相同 | vbr.py | target 恢复时停机 |
| 全量备份→恢复单表 | 误删表,部分恢复 | 必须相同 | 必须相同 | vbr.py | 无需停机 |
| 部分备份→恢复单表 | 只备份变化频繁的表 | 必须相同 | 必须相同 | vbr.py | 无需停机 |
| 并排表恢复 | 对比备份前后差异 | 必须相同 | 必须相同 | vbr.py | 无需停机 |
| copycluster | 整库 A→B | 必须相同 | 必须相同 | vbr.py | target 停机 |
| replicate | 同步特定表到另一集群 | 必须相同 | 必须相同 | vbr.py | 无需停机 |
| EXPORT/IMPORT | 异构集群迁移 | 可不同 | 可不同 | SQL | 无需全部 UP |
| K-safe 节点恢复 | AWS 单节点故障 | 必须相同 | 必须相同 | admintools | 无需停机 |
| EBS 全量备份 | AWS 多节点/全集群故障 | 必须相同 | 必须相同 | vbr.py + EBS | 备份时在线 |
| RAID-0 hard-link | AWS 高性能备份 | 必须相同 | 必须相同 | vbr.py + fsfreeze | admintools:停机 / fsfreeze:秒级 |
与维护 Checklist 的关系¶
Vertica 维护前准备 Checklist
│
├─ 步骤 1: 检查节点依赖 → [K-Safety 最佳实践](k-safety-best-practices.md)
│
├─ 步骤 2: 备份数据库 → 本文(5 篇整合)
│ ├─ 标准备份(vbr.py) → Part 1 全量备份
│ ├─ 冷备份(手动复制目录) → Part 1 → 维护 Checklist §2 方法 B
│ ├─ 集群复制 → Part 2 copycluster
│ └─ AWS 环境 → Part 4 EBS / RAID-0 hard-link
│
├─ 步骤 3: 安全关机
│
└─ 步骤 4: 验证关机
扩展阅读¶
- ROS Bundling 最佳实践 — 减少文件数量以加速备份
- Vertica 维护前准备 Checklist — 维护前完整流程(备份是第 2 步)
- K-Safety 最佳实践 — K-safety 与节点依赖
- Vertica RAID 存储方案 — RAID 存储选型指南
- Vertica Eon 模式数据库的备份 — Eon 模式备份方案