ROS Bundling 最佳实践¶
原文:ROS Bundling
背景¶
在 Vertica 7.2 之前,每个列有两个文件——一个数据文件和一个索引文件。从 Vertica 7.2 开始,这种格式不再存在,两部分合并存储在一个文件中。此外,多个数据文件和索引文件也可以存储在一个文件中。
Vertica 文件架构¶
下图说明了 Vertica 的文件架构,以及表和投影如何归结为文件:
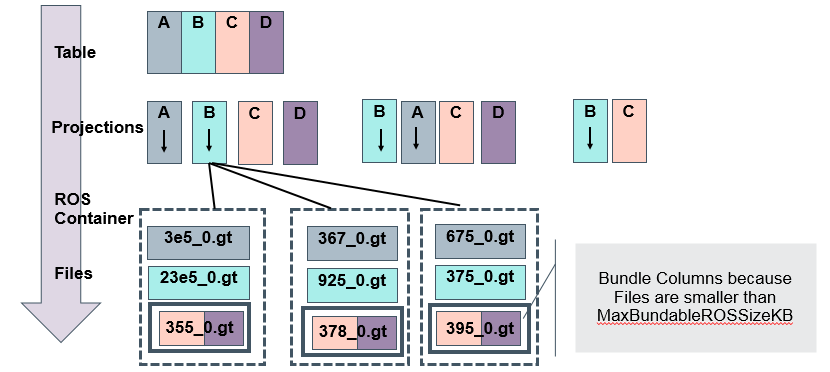
新存储格式¶
Vertica 设计用于处理大型数据集。磁盘上的文件大小从数百 MB 到数百 GB 不等。Tuple Mover 负责管理数据存储:
- 内存缓冲区吸收小批量加载(trickle load)
- 当内存缓冲区填满时,Tuple Mover 的 moveout 操作将数据写入 ROS 容器
- 为管理磁盘上的文件数量,Tuple Mover 的 mergeout 操作将大小相近的 ROS 容器合并为更大的容器
详见 Tuple Mover 最佳实践。
虽然这种方法对大多数表效果良好,但对有大量小文件的表可能会出问题。以下情况可能导致此问题:
- 宽表包含大量 NULL 值列
- 分区范围过小,例如按分钟分区(不推荐)
- 启用了本地分段(Local Segmentation),且分段数设置较高(不推荐)
这些因素会在磁盘上产生大量小文件,导致严重的碎片化,影响节点恢复和备份操作。为解决此问题,Vertica 工程团队开发了新的磁盘存储格式和布局,减少磁盘上的文件数量。
新格式有何不同?¶
数据文件及其索引文件现在存储在一个文件中。例如:
- Vertica 7.2 之前:一个两列投影的存储容器存储 6 个文件
- Vertica 7.2 及以后:同一容器存储 3 个文件
- 如果这些文件小于 1MB,Vertica 会将它们打捆(bundle)为一个文件
是否对所有投影文件进行打捆?¶
不会。 打捆仅在单个存储容器和单个存储位置内进行。小于 MaxBundleableROSSizeKB 的列文件会被打捆在一起;其他列文件在存储容器中保持为独立的列文件。
ROS Bundling 的好处¶
| 好处 | 说明 |
|---|---|
| 减少文件数量 | 减轻底层文件系统压力 |
| 加快备份和恢复 | 文件数减少,备份更快 |
| 加快节点恢复 | 适用于故障恢复场景 |
不改变的内容: - 不减少 catalog 大小 - 不消除 ROS pushback 错误 - 不改变读取列文件时的文件句柄数量
配置参数¶
| 参数 | 数据类型 / 默认值 | 说明 |
|---|---|---|
EnableStorageBundling |
Boolean / true | 启用或禁用存储打捆 |
MaxBundleableROSSizeKB |
Integer / 1024 | 最大可设置 1024 KB。如果同一容器和存储位置中有多个数据文件小于此限制,则打捆在一起 |
CompactStorageJobSizeMB |
Integer / 2048 | 控制 COMPACT_STORAGE() 函数的 job 大小 |
升级影响(7.1 → 7.2)¶
升级不会自动将现有文件从旧格式转换为新格式。升级后,可使用 COMPACT_STORAGE() 函数转换现有文件的格式。
如果 EnableStorageBundling 设为 true:
- 所有新的加载和插入都以新存储格式写入
- 被 mergeout 的现有存储以新存储格式写入
新旧格式兼容性¶
兼容。 如果升级数据库后表中同时包含小文件和大文件,可以选择性地将小文件迁移到新格式,而将大文件保留在旧格式中。
如何将数据从旧格式迁移到新格式?¶
使用 COMPACT_STORAGE() 函数:
SELECT COMPACT_STORAGE(object-name, object-name, min-ros-filesize-kb, small-or-all-files, simulate);
示例输出:
compact_storage
-------------------------------------------------------------------------------------------
Task: compact_storage
On node node01:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node node02:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node node03:
Projection Name :public.foo_super | selected_storage_containers :2 | selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
Success
min_ros_filesize_kb 与 MaxBundleableROSSizeKB 的关系¶
COMPACT_STORAGE() 的参数 min_ros_filesize_kb 与配置参数 MaxBundleableROSSizeKB 相互独立。函数使用你指定的 min_ros_filesize_kb 值,不影响 MaxBundleableROSSizeKB。如果希望在后续的 mergeout 和加载中对更大文件进行打捆,需要单独修改 MaxBundleableROSSizeKB。
最佳转换时机¶
建议: 升级到 Vertica 7.2 后、执行首次备份之前转换现有文件。
原因: - 减少文件数量,备份更快 - 新存储格式使后续备份更快
COMPACT_STORAGE()运行期间数据库可正常使用。
对查询性能的影响¶
COMPACT_STORAGE() 在存储容器级别读写文件。与 mergeout 操作相比内存消耗更少,但会与磁盘 I/O 竞争。
执行时间¶
由于需要重写文件,执行时间取决于数据变更量。
建议: 先将 simulate 参数设为 true 运行模拟,评估存储变更量后再执行。
可以按表或投影级别迭代运行 COMPACT_STORAGE(),逐步完成格式转换。
如何判断是否需要 Bundling?¶
如果备份和恢复操作缓慢,很可能有大量未合并的大文件。
查询投影在某节点上的中位数文件大小¶
SELECT MEDIAN(size) OVER() AS median_fsize
FROM vs_ros AS ros, storage_containers AS cont
WHERE ros.delid = cont.storage_oid
AND cont.node_name = 'node'
AND cont.projection_name = 'proj_name'
LIMIT 1;
模拟模式预估文件减少量¶
查看打捆信息¶
查询系统表 VS_BUNDLED_ROS 查看哪些列文件被打捆:
SELECT node_name, projection_id, sal_storage_id, ros_id, size_bytes, storage_id
FROM VS_BUNDLED_ROS;
示例输出:
node_name | projection_id | sal_storage_id | ros_id | size_bytes | storage_id
----------+--------------------+-------------------------------------------------+------------------+------------+---------------
initiator | 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721409 | 5 | 45035996273721409
initiator | 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721413 | 5 | 45035996273721409
initiator | 45035996273721386 | 0262c017f1fb9eb26b8d8e6266a7005e00a0000000004041 | 45035996273721417 | 48 | 45035996273721409
如何确定 min_ros_filesize_kb 的值¶
场景分析¶
- 场景1:100 个数据文件,每个 < 1MB →
COMPACT_STORAGE()将 200 个文件合并为 1 个。此时指定 100MB 或 1MB 效果相同。 - 场景2:100 个数据文件,每个约 40MB → 指定 100MB 可将 200 个文件合并为 1 个;若指定 1MB,则只能从 200 个减到 100 个。
确定最佳值的方法¶
- 选择一个投影
- 确定文件数量和中位数文件大小
- 以不同
min_ros_filesize_kb值(从中位数到 100MB)运行模拟模式 - 根据模拟结果找到最佳值
完整操作示例¶
1. 检查未打捆的文件数¶
SELECT COUNT(DISTINCT (salstorageid)) * 2 -- 一个 fdb + 一个 pidx
FROM v_internal.vs_ros
WHERE bundleindex < 0; -- 旧版本没有 bundleindex
-- 结果示例:
count
---------
1379533
2. 按投影和节点查看文件大小与数量¶
SELECT
CASE WHEN segment_lower_bound IS NOT NULL THEN 'SEGMENTED' ELSE 'REPLICATED' END AS type,
schema_name,
projection_name,
max(used_bytes) AS max_used_bytes,
min(used_bytes) AS min_used_bytes,
CASE WHEN segment_lower_bound IS NOT NULL
THEN count(DISTINCT colid) ELSE count(DISTINCT colid)
END AS nCols,
count(DISTINCT rosid) AS nFiles
FROM storage_containers
JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE bundleindex < 0
GROUP BY 1, 2, 3, segment_lower_bound
ORDER BY 7 DESC;
示例输出:
type | schema_name | projection_name | max_used_bytes | min_used_bytes | nCols | nFiles
----------+-------------+-----------------+----------------+----------------+-------+--------
SEGMENTED | schema | clients_b1 | 92368520 | 14778 | 13 | 650
SEGMENTED | schema | clients_b0 | 47906279 | 14728 | 13 | 611
SEGMENTED | schema | clients_b0 | 100868741 | 18776 | 13 | 572
SEGMENTED | schema | clients_b0 | 59835832 | 15173 | 13 | 572
SEGMENTED | schema | clients_b1 | 58541167 | 15441 | 13 | 507
SEGMENTED | schema | clients_b1 | 61792636 | 14728 | 13 | 507
3. 按文件大小分桶查看分布¶
SELECT
WIDTH_BUCKET(used_bytes, 0, 1024*1024*1024, 999) AS bucket, -- 1GB 最大桶,1000 个桶(每桶 ~1MB)
count(rosid) AS fileCnt
FROM storage_containers
JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE schema_name = 'schema'
AND projection_name = 'clients_b1'
AND bundleindex < 0
GROUP BY 1
ORDER BY 1;
示例输出(注意 bucket 1 有大量小文件):
4. 模拟运行(dry run)¶
选定 5MB 作为压缩阈值:
输出:
Task: compact_storage
On node v_scrutinload_node0001:
Projection Name :schema.clients_b1 | selected_storage_containers :50 | selected_files_to_compact :1012 | files_after_compact : 50 | modified_storage_KB :35584
On node v_scrutinload_node0002:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :730 | files_after_compact : 39 | modified_storage_KB :16566
On node v_scrutinload_node0003:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :728 | files_after_compact : 39 | modified_storage_KB :23126
Success
5. 执行压缩¶
输出:
Task: compact_storage
On node v_scrutinload_node0001:
Projection Name :schema.clients_b1 | selected_storage_containers :50 | selected_files_to_compact :1212 | files_after_compact : 50 | modified_storage_KB :230564
On node v_scrutinload_node0002:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :928 | files_after_compact : 39 | modified_storage_KB :221211
On node v_scrutinload_node0003:
Projection Name :schema.clients_b1 | selected_storage_containers :39 | selected_files_to_compact :926 | files_after_compact : 39 | modified_storage_KB :227449
Success
6. 验证效果¶
再次分桶查看(小文件已消除):
7. 对比 buddy projection¶
SELECT
CASE WHEN segment_lower_bound IS NOT NULL THEN 'SEGMENTED' ELSE 'REPLICATED' END AS type,
schema_name,
projection_name,
max(used_bytes) AS max_used_bytes,
min(used_bytes) AS min_used_bytes,
CASE WHEN segment_lower_bound IS NOT NULL
THEN count(DISTINCT colid) ELSE count(DISTINCT colid)
END AS nCols,
count(DISTINCT rosid) AS nFiles
FROM storage_containers
JOIN v_internal.vs_ros ON (delid = storage_oid)
WHERE bundleindex < 0
GROUP BY 1, 2, 3, segment_lower_bound
ORDER BY 7 DESC;
结果:clients_b1 文件数从 ~650 降至 ~44,效果显著。
关键要点总结¶
- 新格式 > 旧格式:7.2+ 默认启用 bundling,减少磁盘文件数
- 升级后主动转换:升级不会自动转换旧文件,需手动执行
COMPACT_STORAGE() - 先模拟后执行:始终先 dry-run 评估影响
- 按投影粒度执行:便于控制资源和执行时机
- 先转换再备份:在首次备份前转换可显著加速备份恢复
- 三个关键参数:
EnableStorageBundling、MaxBundleableROSSizeKB、CompactStorageJobSizeMB
扩展阅读¶
- ROS Pushback 故障排查 — ROS 容器超限与 pushback 场景排查
- Tuple Mover 最佳实践完全指南 — Mergeout 与 Tuple Mover 架构详解
- Vertica 备份与恢复方案总览 — Bundling 加速备份和恢复
- Vertica 节点恢复过程 — 节点恢复与文件碎片化的影响
- 理解 Vertica 的分区 — 分区粒度对 ROS 文件数量的影响
- Vertica 维护前准备 Checklist — 升级后执行 COMPACT_STORAGE 的时机